 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Integrated AI-Enabled System Using One Class Twin Cross Learning (OCT-X) for Early Gastric Cancer Detection
Mar 31, 2025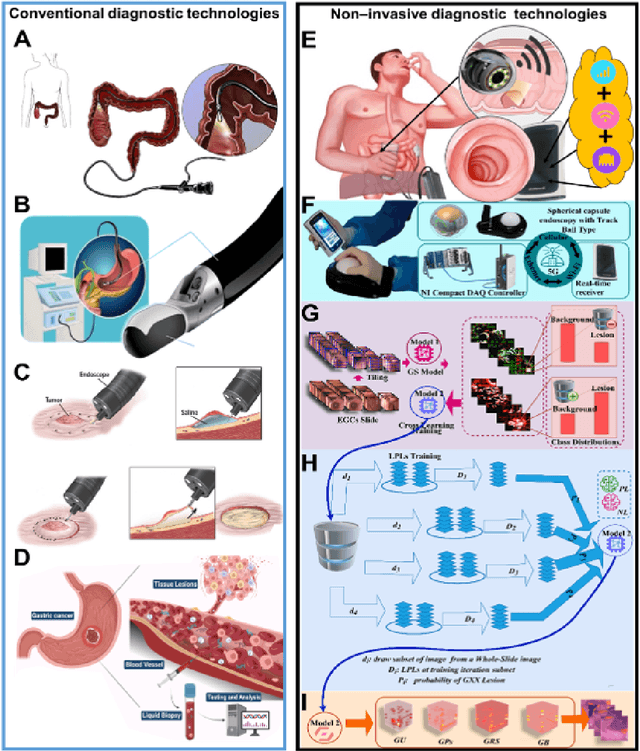
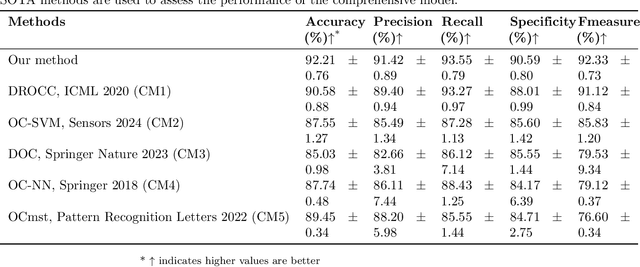
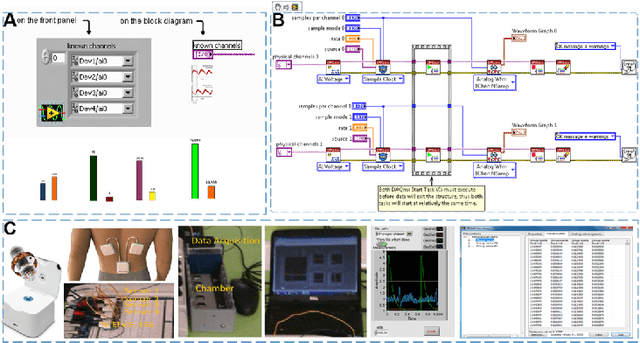
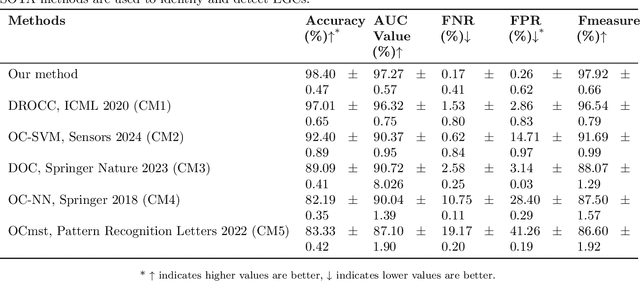
Early detection of gastric cancer, a leading cause of cancer-related mortality worldwide, remains hampered by the limitations of current diagnostic technologies, leading to high rates of misdiagnosis and missed diagnoses. To address these challenges, we propose an integrated system that synergizes advanced hardware and software technologies to balance speed-accuracy. Our study introduces the One Class Twin Cross Learning (OCT-X) algorithm. Leveraging a novel fast double-threshold grid search strategy (FDT-GS) and a patch-based deep fully convolutional network, OCT-X maximizes diagnostic accuracy through real-time data processing and seamless lesion surveillance. The hardware component includes an all-in-one point-of-care testing (POCT) device with high-resolution imaging sensors, real-time data processing, and wireless connectivity, facilitated by the NI CompactDAQ and LabVIEW software. Our integrated system achieved an unprecedented diagnostic accuracy of 99.70%, significantly outperforming existing models by up to 4.47%, and demonstrated a 10% improvement in multirate adaptability. These findings underscore the potential of OCT-X as well as the integrated system in clinical diagnostics, offering a path toward more accurate, efficient, and less invasive early gastric cancer detection. Future research will explore broader applications, further advancing oncological diagnostics. Code is available at https://github.com/liu37972/Multirate-Location-on-OCT-X-Learning.git.
Enhancing Diagnostic Precision in Gastric Bleeding through Automated Lesion Segmentation: A Deep DuS-KFCM Approach
Nov 21, 2024


Timely and precise classification and segmentation of gastric bleeding in endoscopic imagery are pivotal for the rapid diagnosis and intervention of gastric complications, which is critical in life-saving medical procedures. Traditional methods grapple with the challenge posed by the indistinguishable intensity values of bleeding tissues adjacent to other gastric structures. Our study seeks to revolutionize this domain by introducing a novel deep learning model, the Dual Spatial Kernelized Constrained Fuzzy C-Means (Deep DuS-KFCM) clustering algorithm. This Hybrid Neuro-Fuzzy system synergizes Neural Networks with Fuzzy Logic to offer a highly precise and efficient identification of bleeding regions. Implementing a two-fold coarse-to-fine strategy for segmentation, this model initially employs the Spatial Kernelized Fuzzy C-Means (SKFCM) algorithm enhanced with spatial intensity profiles and subsequently harnesses the state-of-the-art DeepLabv3+ with ResNet50 architecture to refine the segmentation output. Through extensive experiments across mainstream gastric bleeding and red spots datasets, our Deep DuS-KFCM model demonstrated unprecedented accuracy rates of 87.95%, coupled with a specificity of 96.33%, outperforming contemporary segmentation methods. The findings underscore the model's robustness against noise and its outstanding segmentation capabilities, particularly for identifying subtle bleeding symptoms, thereby presenting a significant leap forward in medical image processing.
MsMemoryGAN: A Multi-scale Memory GAN for Palm-vein Adversarial Purification
Aug 20, 2024

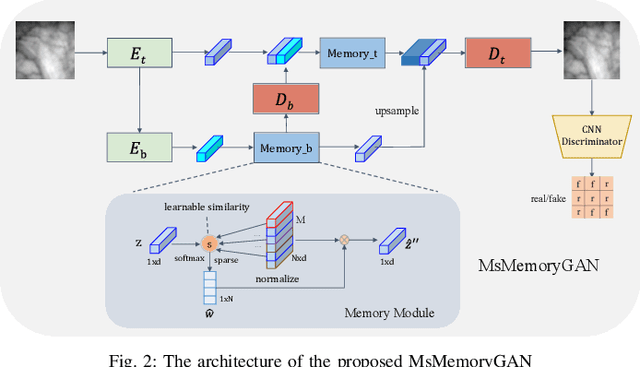
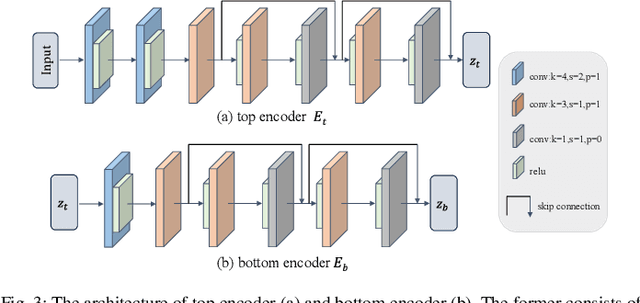
Deep neural networks have recently achieved promising performance in the vein recognition task and have shown an increasing application trend, however, they are prone to adversarial perturbation attacks by adding imperceptible perturbations to the input, resulting in making incorrect recognition. To address this issue, we propose a novel defense model named MsMemoryGAN, which aims to filter the perturbations from adversarial samples before recognition. First, we design a multi-scale autoencoder to achieve high-quality reconstruction and two memory modules to learn the detailed patterns of normal samples at different scales. Second, we investigate a learnable metric in the memory module to retrieve the most relevant memory items to reconstruct the input image. Finally, the perceptional loss is combined with the pixel loss to further enhance the quality of the reconstructed image. During the training phase, the MsMemoryGAN learns to reconstruct the input by merely using fewer prototypical elements of the normal patterns recorded in the memory. At the testing stage, given an adversarial sample, the MsMemoryGAN retrieves its most relevant normal patterns in memory for the reconstruction. Perturbations in the adversarial sample are usually not reconstructed well, resulting in purifying the input from adversarial perturbations. We have conducted extensive experiments on two public vein datasets under different adversarial attack methods to evaluate the performance of the proposed approach. The experimental results show that our approach removes a wide variety of adversarial perturbations, allowing vein classifiers to achieve the highest recognition accuracy.
Leveraging Foundation Models for Zero-Shot IoT Sensing
Jul 29, 2024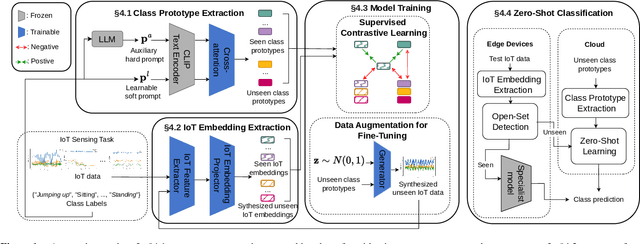
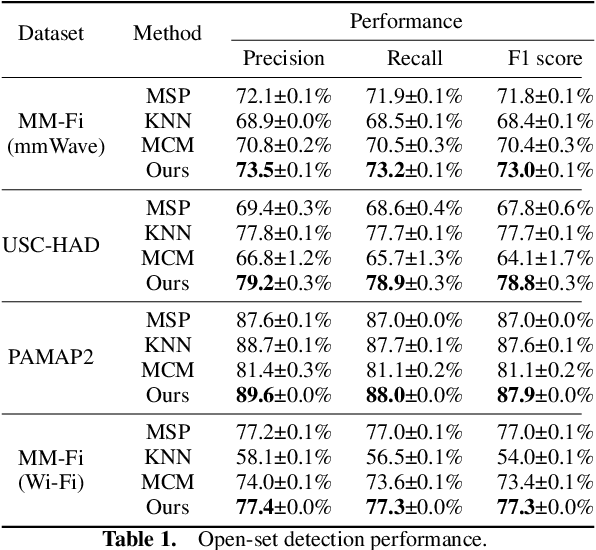
Deep learning models are increasingly deployed on edge Internet of Things (IoT) devices. However, these models typically operate under supervised conditions and fail to recognize unseen classes different from training. To address this, zero-shot learning (ZSL) aims to classify data of unseen classes with the help of semantic information. Foundation models (FMs) trained on web-scale data have shown impressive ZSL capability in natural language processing and visual understanding. However, leveraging FMs' generalized knowledge for zero-shot IoT sensing using signals such as mmWave, IMU, and Wi-Fi has not been fully investigated. In this work, we align the IoT data embeddings with the semantic embeddings generated by an FM's text encoder for zero-shot IoT sensing. To utilize the physics principles governing the generation of IoT sensor signals to derive more effective prompts for semantic embedding extraction, we propose to use cross-attention to combine a learnable soft prompt that is optimized automatically on training data and an auxiliary hard prompt that encodes domain knowledge of the IoT sensing task. To address the problem of IoT embeddings biasing to seen classes due to the lack of unseen class data during training, we propose using data augmentation to synthesize unseen class IoT data for fine-tuning the IoT feature extractor and embedding projector. We evaluate our approach on multiple IoT sensing tasks. Results show that our approach achieves superior open-set detection and generalized zero-shot learning performance compared with various baselines. Our code is available at https://github.com/schrodingho/FM\_ZSL\_IoT.
A First Physical-World Trajectory Prediction Attack via LiDAR-induced Deceptions in Autonomous Driving
Jun 17, 2024



Trajectory prediction forecasts nearby agents' moves based on their historical trajectories. Accurate trajectory prediction is crucial for autonomous vehicles. Existing attacks compromise the prediction model of a victim AV by directly manipulating the historical trajectory of an attacker AV, which has limited real-world applicability. This paper, for the first time, explores an indirect attack approach that induces prediction errors via attacks against the perception module of a victim AV. Although it has been shown that physically realizable attacks against LiDAR-based perception are possible by placing a few objects at strategic locations, it is still an open challenge to find an object location from the vast search space in order to launch effective attacks against prediction under varying victim AV velocities. Through analysis, we observe that a prediction model is prone to an attack focusing on a single point in the scene. Consequently, we propose a novel two-stage attack framework to realize the single-point attack. The first stage of prediction-side attack efficiently identifies, guided by the distribution of detection results under object-based attacks against perception, the state perturbations for the prediction model that are effective and velocity-insensitive. In the second stage of location matching, we match the feasible object locations with the found state perturbations. Our evaluation using a public autonomous driving dataset shows that our attack causes a collision rate of up to 63% and various hazardous responses of the victim AV. The effectiveness of our attack is also demonstrated on a real testbed car. To the best of our knowledge, this study is the first security analysis spanning from LiDAR-based perception to prediction in autonomous driving, leading to a realistic attack on prediction. To counteract the proposed attack, potential defenses are discussed.
Instant Answering in E-Commerce Buyer-Seller Messaging using Message-to-Question Reformulation
Jan 30, 2024
E-commerce customers frequently seek detailed product information for purchase decisions, commonly contacting sellers directly with extended queries. This manual response requirement imposes additional costs and disrupts buyer's shopping experience with response time fluctuations ranging from hours to days. We seek to automate buyer inquiries to sellers in a leading e-commerce store using a domain-specific federated Question Answering (QA) system. The main challenge is adapting current QA systems, designed for single questions, to address detailed customer queries. We address this with a low-latency, sequence-to-sequence approach, MESSAGE-TO-QUESTION ( M2Q ). It reformulates buyer messages into succinct questions by identifying and extracting the most salient information from a message. Evaluation against baselines shows that M2Q yields relative increases of 757% in question understanding, and 1,746% in answering rate from the federated QA system. Live deployment shows that automatic answering saves sellers from manually responding to millions of messages per year, and also accelerates customer purchase decisions by eliminating the need for buyers to wait for a reply
EmMixformer: Mix transformer for eye movement recognition
Jan 10, 2024



Eye movement (EM) is a new highly secure biometric behavioral modality that has received increasing attention in recent years. Although deep neural networks, such as convolutional neural network (CNN), have recently achieved promising performance, current solutions fail to capture local and global temporal dependencies within eye movement data. To overcome this problem, we propose in this paper a mixed transformer termed EmMixformer to extract time and frequency domain information for eye movement recognition. To this end, we propose a mixed block consisting of three modules, transformer, attention Long short-term memory (attention LSTM), and Fourier transformer. We are the first to attempt leveraging transformer to learn long temporal dependencies within eye movement. Second, we incorporate the attention mechanism into LSTM to propose attention LSTM with the aim to learn short temporal dependencies. Third, we perform self attention in the frequency domain to learn global features. As the three modules provide complementary feature representations in terms of local and global dependencies, the proposed EmMixformer is capable of improving recognition accuracy. The experimental results on our eye movement dataset and two public eye movement datasets show that the proposed EmMixformer outperforms the state of the art by achieving the lowest verification error.
Uncertainty-Encoded Multi-Modal Fusion for Robust Object Detection in Autonomous Driving
Jul 30, 2023
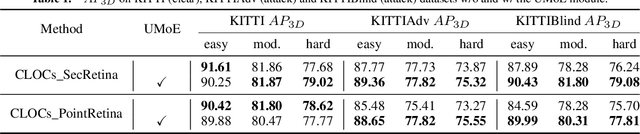

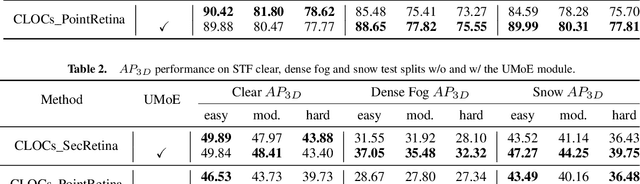
Multi-modal fusion has shown initial promising results for object detection of autonomous driving perception. However, many existing fusion schemes do not consider the quality of each fusion input and may suffer from adverse conditions on one or more sensors. While predictive uncertainty has been applied to characterize single-modal object detection performance at run time, incorporating uncertainties into the multi-modal fusion still lacks effective solutions due primarily to the uncertainty's cross-modal incomparability and distinct sensitivities to various adverse conditions. To fill this gap, this paper proposes Uncertainty-Encoded Mixture-of-Experts (UMoE) that explicitly incorporates single-modal uncertainties into LiDAR-camera fusion. UMoE uses individual expert network to process each sensor's detection result together with encoded uncertainty. Then, the expert networks' outputs are analyzed by a gating network to determine the fusion weights. The proposed UMoE module can be integrated into any proposal fusion pipeline. Evaluation shows that UMoE achieves a maximum of 10.67%, 3.17%, and 5.40% performance gain compared with the state-of-the-art proposal-level multi-modal object detectors under extreme weather, adversarial, and blinding attack scenarios.
PriMask: Cascadable and Collusion-Resilient Data Masking for Mobile Cloud Inference
Nov 12, 2022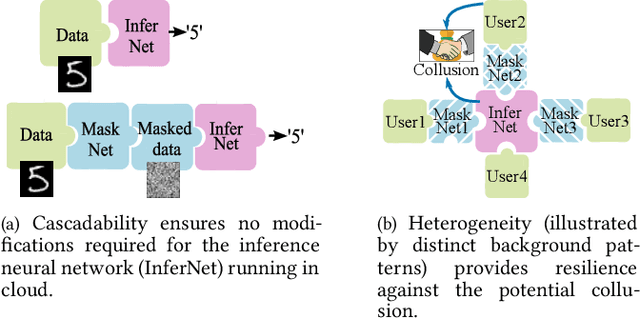
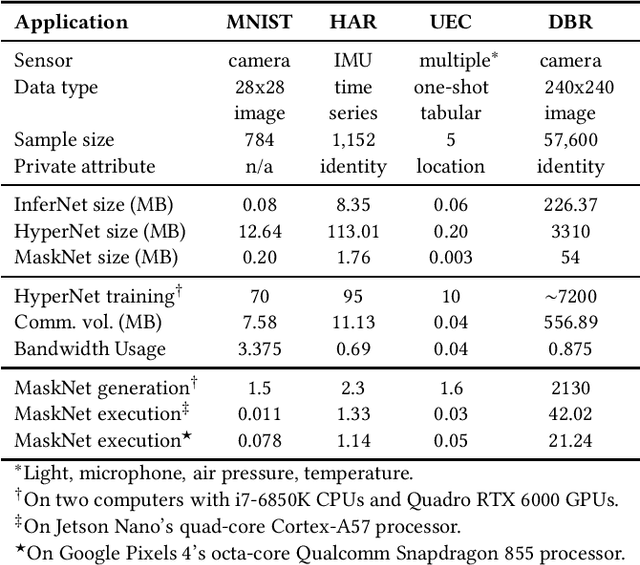
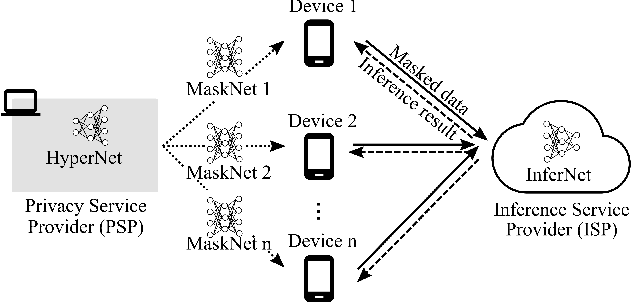

Mobile cloud offloading is indispensable for inference tasks based on large-scale deep models. However, transmitting privacy-rich inference data to the cloud incurs concerns. This paper presents the design of a system called PriMask, in which the mobile device uses a secret small-scale neural network called MaskNet to mask the data before transmission. PriMask significantly weakens the cloud's capability to recover the data or extract certain private attributes. The MaskNet is em cascadable in that the mobile can opt in to or out of its use seamlessly without any modifications to the cloud's inference service. Moreover, the mobiles use different MaskNets, such that the collusion between the cloud and some mobiles does not weaken the protection for other mobiles. We devise a {\em split adversarial learning} method to train a neural network that generates a new MaskNet quickly (within two seconds) at run time. We apply PriMask to three mobile sensing applications with diverse modalities and complexities, i.e., human activity recognition, urban environment crowdsensing, and driver behavior recognition. Results show PriMask's effectiveness in all three applications.
Indoor Smartphone SLAM with Learned Echoic Location Features
Oct 16, 2022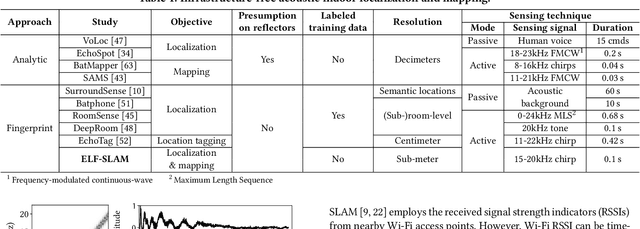
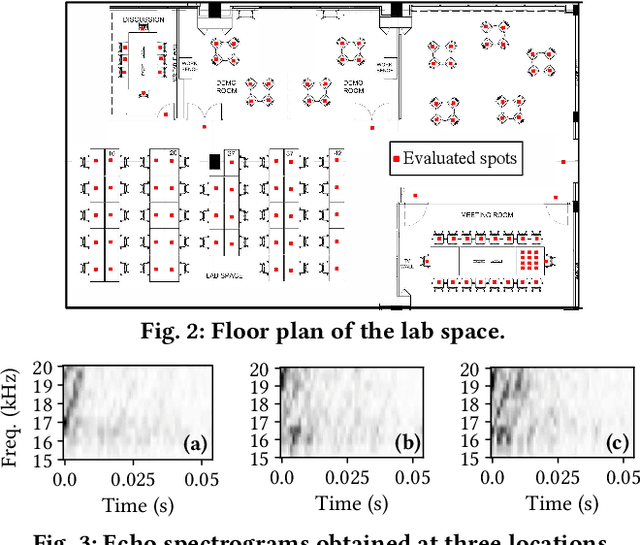

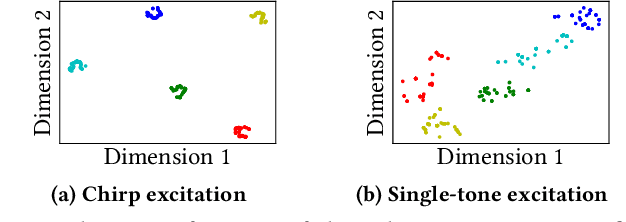
Indoor self-localization is a highly demanded system function for smartphones. The current solutions based on inertial, radio frequency, and geomagnetic sensing may have degraded performance when their limiting factors take effect. In this paper, we present a new indoor simultaneous localization and mapping (SLAM) system that utilizes the smartphone's built-in audio hardware and inertial measurement unit (IMU). Our system uses a smartphone's loudspeaker to emit near-inaudible chirps and then the microphone to record the acoustic echoes from the indoor environment. Our profiling measurements show that the echoes carry location information with sub-meter granularity. To enable SLAM, we apply contrastive learning to construct an echoic location feature (ELF) extractor, such that the loop closures on the smartphone's trajectory can be accurately detected from the associated ELF trace. The detection results effectively regulate the IMU-based trajectory reconstruction. Extensive experiments show that our ELF-based SLAM achieves median localization errors of $0.1\,\text{m}$, $0.53\,\text{m}$, and $0.4\,\text{m}$ on the reconstructed trajectories in a living room, an office, and a shopping mall, and outperforms the Wi-Fi and geomagnetic SLAM systems.