 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Multi-Agent Response Refinement in Conversational Systems
Nov 11, 2025Large Language Models (LLMs) have demonstrated remarkable success in conversational systems by generating human-like responses. However, they can fall short, especially when required to account for personalization or specific knowledge. In real-life settings, it is impractical to rely on users to detect these errors and request a new response. One way to address this problem is to refine the response before returning it to the user. While existing approaches focus on refining responses within a single LLM, this method struggles to consider diverse aspects needed for effective conversations. In this work, we propose refining responses through a multi-agent framework, where each agent is assigned a specific role for each aspect. We focus on three key aspects crucial to conversational quality: factuality, personalization, and coherence. Each agent is responsible for reviewing and refining one of these aspects, and their feedback is then merged to improve the overall response. To enhance collaboration among them, we introduce a dynamic communication strategy. Instead of following a fixed sequence of agents, our approach adaptively selects and coordinates the most relevant agents based on the specific requirements of each query. We validate our framework on challenging conversational datasets, demonstrating that ours significantly outperforms relevant baselines, particularly in tasks involving knowledge or user's persona, or both.
ATLAS: Actor-Critic Task-Completion with Look-ahead Action Simulation
Oct 26, 2025We observe that current state-of-the-art web-agents are unable to effectively adapt to new environments without neural network fine-tuning, without which they produce inefficient execution plans due to a lack of awareness of the structure and dynamics of the new environment. To address this limitation, we introduce ATLAS (Actor-Critic Task-completion with Look-ahead Action Simulation), a memory-augmented agent that is able to make plans grounded in a model of the environment by simulating the consequences of those actions in cognitive space. Our agent starts by building a "cognitive map" by performing a lightweight curiosity driven exploration of the environment. The planner proposes candidate actions; the simulator predicts their consequences in cognitive space; a critic analyzes the options to select the best roll-out and update the original plan; and a browser executor performs the chosen action. On the WebArena-Lite Benchmark, we achieve a 63% success rate compared to 53.9% success rate for the previously published state-of-the-art. Unlike previous systems, our modular architecture requires no website-specific LLM fine-tuning. Ablations show sizable drops without the world-model, hierarchical planner, and look-ahead-based replanner confirming their complementary roles within the design of our system
Align to Structure: Aligning Large Language Models with Structural Information
Apr 04, 2025Generating long, coherent text remains a challenge for large language models (LLMs), as they lack hierarchical planning and structured organization in discourse generation. We introduce Structural Alignment, a novel method that aligns LLMs with human-like discourse structures to enhance long-form text generation. By integrating linguistically grounded discourse frameworks into reinforcement learning, our approach guides models to produce coherent and well-organized outputs. We employ a dense reward scheme within a Proximal Policy Optimization framework, assigning fine-grained, token-level rewards based on the discourse distinctiveness relative to human writing. Two complementary reward models are evaluated: the first improves readability by scoring surface-level textual features to provide explicit structuring, while the second reinforces deeper coherence and rhetorical sophistication by analyzing global discourse patterns through hierarchical discourse motifs, outperforming both standard and RLHF-enhanced models in tasks such as essay generation and long-document summarization. All training data and code will be publicly shared at https://github.com/minnesotanlp/struct_align.
Wizard of Shopping: Target-Oriented E-commerce Dialogue Generation with Decision Tree Branching
Feb 03, 2025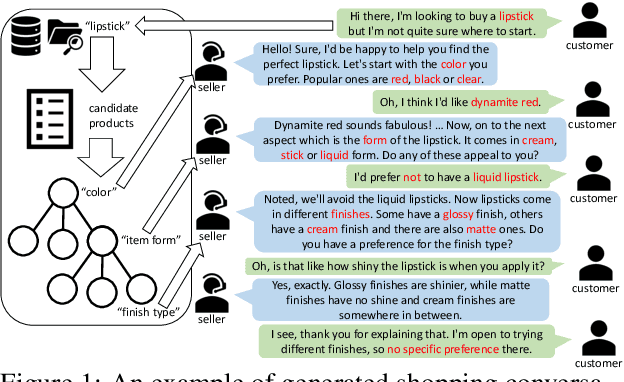

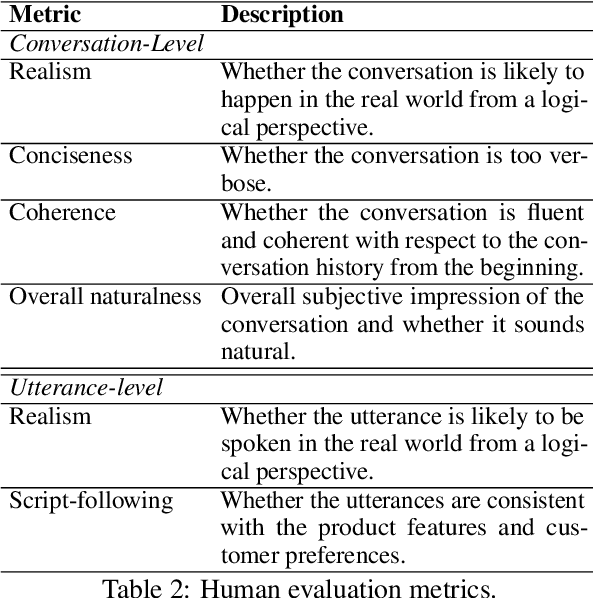
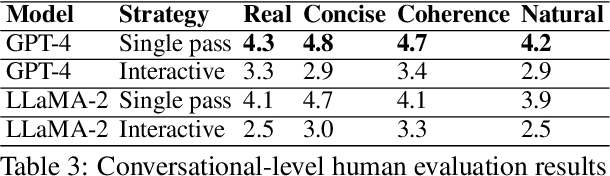
The goal of conversational product search (CPS) is to develop an intelligent, chat-based shopping assistant that can directly interact with customers to understand shopping intents, ask clarification questions, and find relevant products. However, training such assistants is hindered mainly due to the lack of reliable and large-scale datasets. Prior human-annotated CPS datasets are extremely small in size and lack integration with real-world product search systems. We propose a novel approach, TRACER, which leverages large language models (LLMs) to generate realistic and natural conversations for different shopping domains. TRACER's novelty lies in grounding the generation to dialogue plans, which are product search trajectories predicted from a decision tree model, that guarantees relevant product discovery in the shortest number of search conditions. We also release the first target-oriented CPS dataset Wizard of Shopping (WoS), containing highly natural and coherent conversations (3.6k) from three shopping domains. Finally, we demonstrate the quality and effectiveness of WoS via human evaluations and downstream tasks.
Question Suggestion for Conversational Shopping Assistants Using Product Metadata
May 02, 2024
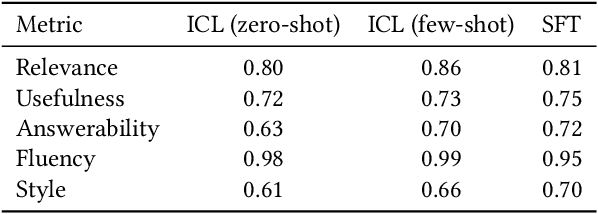
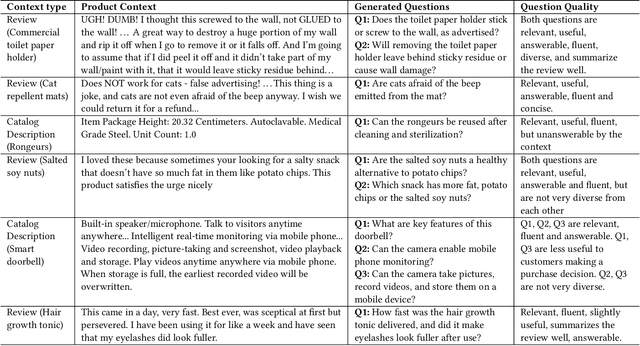
Digital assistants have become ubiquitous in e-commerce applications, following the recent advancements in Information Retrieval (IR), Natural Language Processing (NLP) and Generative Artificial Intelligence (AI). However, customers are often unsure or unaware of how to effectively converse with these assistants to meet their shopping needs. In this work, we emphasize the importance of providing customers a fast, easy to use, and natural way to interact with conversational shopping assistants. We propose a framework that employs Large Language Models (LLMs) to automatically generate contextual, useful, answerable, fluent and diverse questions about products, via in-context learning and supervised fine-tuning. Recommending these questions to customers as helpful suggestions or hints to both start and continue a conversation can result in a smoother and faster shopping experience with reduced conversation overhead and friction. We perform extensive offline evaluations, and discuss in detail about potential customer impact, and the type, length and latency of our generated product questions if incorporated into a real-world shopping assistant.
Identifying Shopping Intent in Product QA for Proactive Recommendations
Apr 09, 2024


Voice assistants have become ubiquitous in smart devices allowing users to instantly access information via voice questions. While extensive research has been conducted in question answering for voice search, little attention has been paid on how to enable proactive recommendations from a voice assistant to its users. This is a highly challenging problem that often leads to user friction, mainly due to recommendations provided to the users at the wrong time. We focus on the domain of e-commerce, namely in identifying Shopping Product Questions (SPQs), where the user asking a product-related question may have an underlying shopping need. Identifying a user's shopping need allows voice assistants to enhance shopping experience by determining when to provide recommendations, such as product or deal recommendations, or proactive shopping actions recommendation. Identifying SPQs is a challenging problem and cannot be done from question text alone, and thus requires to infer latent user behavior patterns inferred from user's past shopping history. We propose features that capture the user's latent shopping behavior from their purchase history, and combine them using a novel Mixture-of-Experts (MoE) model. Our evaluation shows that the proposed approach is able to identify SPQs with a high score of F1=0.91. Furthermore, based on an online evaluation with real voice assistant users, we identify SPQs in real-time and recommend shopping actions to users to add the queried product into their shopping list. We demonstrate that we are able to accurately identify SPQs, as indicated by the significantly higher rate of added products to users' shopping lists when being prompted after SPQs vs random PQs.
Leveraging Interesting Facts to Enhance User Engagement with Conversational Interfaces
Apr 09, 2024



Conversational Task Assistants (CTAs) guide users in performing a multitude of activities, such as making recipes. However, ensuring that interactions remain engaging, interesting, and enjoyable for CTA users is not trivial, especially for time-consuming or challenging tasks. Grounded in psychological theories of human interest, we propose to engage users with contextual and interesting statements or facts during interactions with a multi-modal CTA, to reduce fatigue and task abandonment before a task is complete. To operationalize this idea, we train a high-performing classifier (82% F1-score) to automatically identify relevant and interesting facts for users. We use it to create an annotated dataset of task-specific interesting facts for the domain of cooking. Finally, we design and validate a dialogue policy to incorporate the identified relevant and interesting facts into a conversation, to improve user engagement and task completion. Live testing on a leading multi-modal voice assistant shows that 66% of the presented facts were received positively, leading to a 40% gain in the user satisfaction rating, and a 37% increase in conversation length. These findings emphasize that strategically incorporating interesting facts into the CTA experience can promote real-world user participation for guided task interactions.
Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data
Apr 03, 2024Large Language Models (LLMs) operating in 0-shot or few-shot settings achieve competitive results in Text Classification tasks. In-Context Learning (ICL) typically achieves better accuracy than the 0-shot setting, but it pays in terms of efficiency, due to the longer input prompt. In this paper, we propose a strategy to make LLMs as efficient as 0-shot text classifiers, while getting comparable or better accuracy than ICL. Our solution targets the low resource setting, i.e., when only 4 examples per class are available. Using a single LLM and few-shot real data we perform a sequence of generation, filtering and Parameter-Efficient Fine-Tuning steps to create a robust and efficient classifier. Experimental results show that our approach leads to competitive results on multiple text classification datasets.
Instant Answering in E-Commerce Buyer-Seller Messaging using Message-to-Question Reformulation
Jan 30, 2024
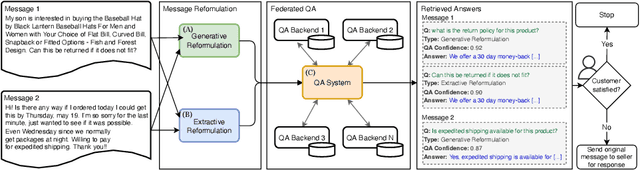
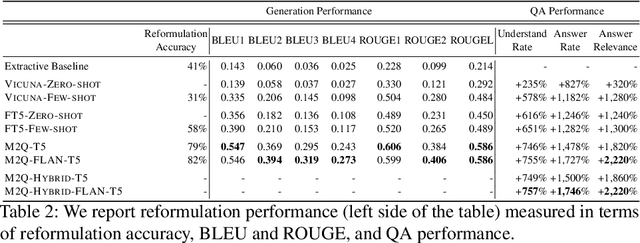
E-commerce customers frequently seek detailed product information for purchase decisions, commonly contacting sellers directly with extended queries. This manual response requirement imposes additional costs and disrupts buyer's shopping experience with response time fluctuations ranging from hours to days. We seek to automate buyer inquiries to sellers in a leading e-commerce store using a domain-specific federated Question Answering (QA) system. The main challenge is adapting current QA systems, designed for single questions, to address detailed customer queries. We address this with a low-latency, sequence-to-sequence approach, MESSAGE-TO-QUESTION ( M2Q ). It reformulates buyer messages into succinct questions by identifying and extracting the most salient information from a message. Evaluation against baselines shows that M2Q yields relative increases of 757% in question understanding, and 1,746% in answering rate from the federated QA system. Live deployment shows that automatic answering saves sellers from manually responding to millions of messages per year, and also accelerates customer purchase decisions by eliminating the need for buyers to wait for a reply
Controllable Decontextualization of Yes/No Question and Answers into Factual Statements
Jan 18, 2024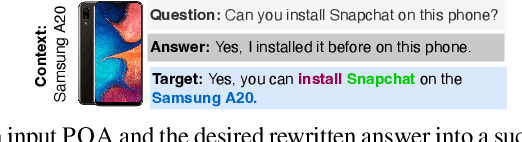
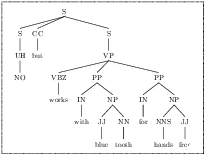


Yes/No or polar questions represent one of the main linguistic question categories. They consist of a main interrogative clause, for which the answer is binary (assertion or negation). Polar questions and answers (PQA) represent a valuable knowledge resource present in many community and other curated QA sources, such as forums or e-commerce applications. Using answers to polar questions alone in other contexts is not trivial. Answers are contextualized, and presume that the interrogative question clause and any shared knowledge between the asker and answerer are provided. We address the problem of controllable rewriting of answers to polar questions into decontextualized and succinct factual statements. We propose a Transformer sequence to sequence model that utilizes soft-constraints to ensure controllable rewriting, such that the output statement is semantically equivalent to its PQA input. Evaluation on three separate PQA datasets as measured through automated and human evaluation metrics show that our proposed approach achieves the best performance when compared to existing baselines.