 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Calibration and Metric Differential Privacy in Language Models
Mar 18, 2025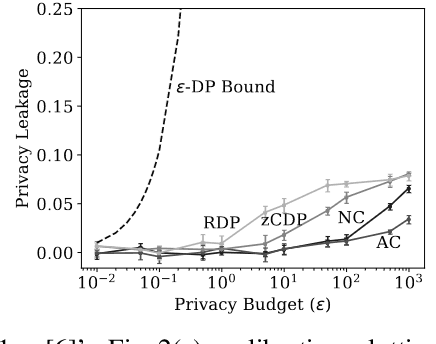
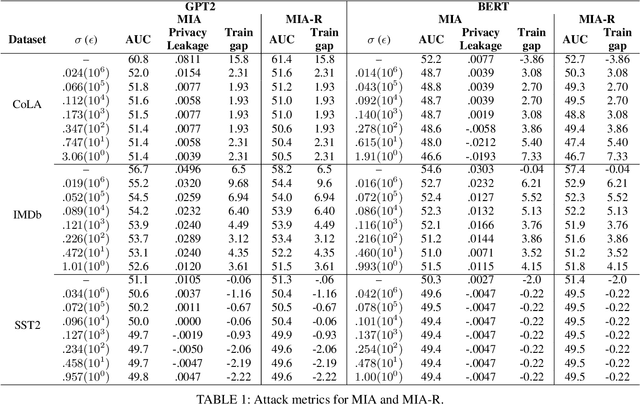
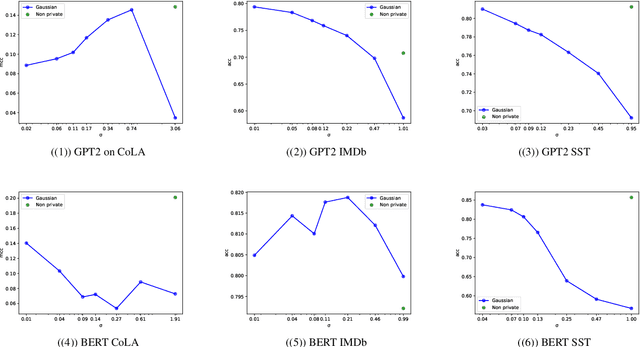

NLP models trained with differential privacy (DP) usually adopt the DP-SGD framework, and privacy guarantees are often reported in terms of the privacy budget $\epsilon$. However, $\epsilon$ does not have any intrinsic meaning, and it is generally not possible to compare across variants of the framework. Work in image processing has therefore explored how to empirically calibrate noise across frameworks using Membership Inference Attacks (MIAs). However, this kind of calibration has not been established for NLP. In this paper, we show that MIAs offer little help in calibrating privacy, whereas reconstruction attacks are more useful. As a use case, we define a novel kind of directional privacy based on the von Mises-Fisher (VMF) distribution, a metric DP mechanism that perturbs angular distance rather than adding (isotropic) Gaussian noise, and apply this to NLP architectures. We show that, even though formal guarantees are incomparable, empirical privacy calibration reveals that each mechanism has different areas of strength with respect to utility-privacy trade-offs.
Comparing privacy notions for protection against reconstruction attacks in machine learning
Feb 06, 2025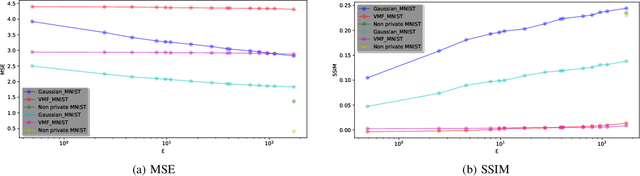



Within the machine learning community, reconstruction attacks are a principal concern and have been identified even in federated learning (FL), which was designed with privacy preservation in mind. In response to these threats, the privacy community recommends the use of differential privacy (DP) in the stochastic gradient descent algorithm, termed DP-SGD. However, the proliferation of variants of DP in recent years\textemdash such as metric privacy\textemdash has made it challenging to conduct a fair comparison between different mechanisms due to the different meanings of the privacy parameters $\epsilon$ and $\delta$ across different variants. Thus, interpreting the practical implications of $\epsilon$ and $\delta$ in the FL context and amongst variants of DP remains ambiguous. In this paper, we lay a foundational framework for comparing mechanisms with differing notions of privacy guarantees, namely $(\epsilon,\delta)$-DP and metric privacy. We provide two foundational means of comparison: firstly, via the well-established $(\epsilon,\delta)$-DP guarantees, made possible through the R\'enyi differential privacy framework; and secondly, via Bayes' capacity, which we identify as an appropriate measure for reconstruction threats.
Suspiciousness of Adversarial Texts to Human
Oct 06, 2024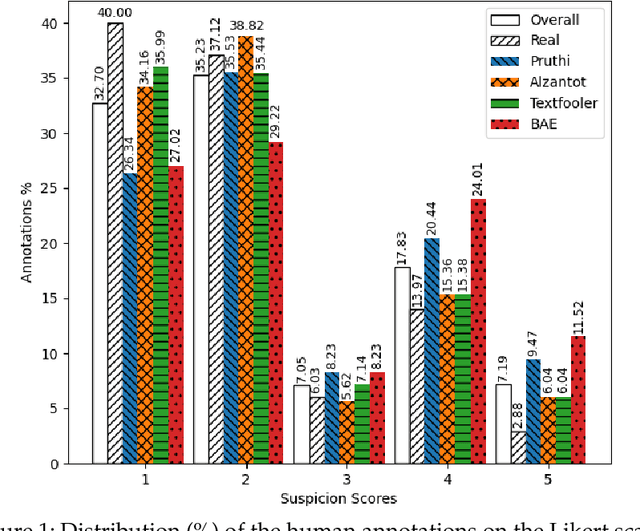


Adversarial examples pose a significant challenge to deep neural networks (DNNs) across both image and text domains, with the intent to degrade model performance through meticulously altered inputs. Adversarial texts, however, are distinct from adversarial images due to their requirement for semantic similarity and the discrete nature of the textual contents. This study delves into the concept of human suspiciousness, a quality distinct from the traditional focus on imperceptibility found in image-based adversarial examples. Unlike images, where adversarial changes are meant to be indistinguishable to the human eye, textual adversarial content must often remain undetected or non-suspicious to human readers, even when the text's purpose is to deceive NLP systems or bypass filters. In this research, we expand the study of human suspiciousness by analyzing how individuals perceive adversarial texts. We gather and publish a novel dataset of Likert-scale human evaluations on the suspiciousness of adversarial sentences, crafted by four widely used adversarial attack methods and assess their correlation with the human ability to detect machine-generated alterations. Additionally, we develop a regression-based model to quantify suspiciousness and establish a baseline for future research in reducing the suspiciousness in adversarial text generation. We also demonstrate how the regressor-generated suspicious scores can be incorporated into adversarial generation methods to produce texts that are less likely to be perceived as computer-generated. We make our human suspiciousness annotated data and our code available.
IDT: Dual-Task Adversarial Attacks for Privacy Protection
Jun 28, 2024



Natural language processing (NLP) models may leak private information in different ways, including membership inference, reconstruction or attribute inference attacks. Sensitive information may not be explicit in the text, but hidden in underlying writing characteristics. Methods to protect privacy can involve using representations inside models that are demonstrated not to detect sensitive attributes or -- for instance, in cases where users might not trust a model, the sort of scenario of interest here -- changing the raw text before models can have access to it. The goal is to rewrite text to prevent someone from inferring a sensitive attribute (e.g. the gender of the author, or their location by the writing style) whilst keeping the text useful for its original intention (e.g. the sentiment of a product review). The few works tackling this have focused on generative techniques. However, these often create extensively different texts from the original ones or face problems such as mode collapse. This paper explores a novel adaptation of adversarial attack techniques to manipulate a text to deceive a classifier w.r.t one task (privacy) whilst keeping the predictions of another classifier trained for another task (utility) unchanged. We propose IDT, a method that analyses predictions made by auxiliary and interpretable models to identify which tokens are important to change for the privacy task, and which ones should be kept for the utility task. We evaluate different datasets for NLP suitable for different tasks. Automatic and human evaluations show that IDT retains the utility of text, while also outperforming existing methods when deceiving a classifier w.r.t privacy task.
Bayes' capacity as a measure for reconstruction attacks in federated learning
Jun 19, 2024

Within the machine learning community, reconstruction attacks are a principal attack of concern and have been identified even in federated learning, which was designed with privacy preservation in mind. In federated learning, it has been shown that an adversary with knowledge of the machine learning architecture is able to infer the exact value of a training element given an observation of the weight updates performed during stochastic gradient descent. In response to these threats, the privacy community recommends the use of differential privacy in the stochastic gradient descent algorithm, termed DP-SGD. However, DP has not yet been formally established as an effective countermeasure against reconstruction attacks. In this paper, we formalise the reconstruction threat model using the information-theoretic framework of quantitative information flow. We show that the Bayes' capacity, related to the Sibson mutual information of order infinity, represents a tight upper bound on the leakage of the DP-SGD algorithm to an adversary interested in performing a reconstruction attack. We provide empirical results demonstrating the effectiveness of this measure for comparing mechanisms against reconstruction threats.
Follow-on Question Suggestion via Voice Hints for Voice Assistants
Oct 25, 2023The adoption of voice assistants like Alexa or Siri has grown rapidly, allowing users to instantly access information via voice search. Query suggestion is a standard feature of screen-based search experiences, allowing users to explore additional topics. However, this is not trivial to implement in voice-based settings. To enable this, we tackle the novel task of suggesting questions with compact and natural voice hints to allow users to ask follow-up questions. We define the task, ground it in syntactic theory and outline linguistic desiderata for spoken hints. We propose baselines and an approach using sequence-to-sequence Transformers to generate spoken hints from a list of questions. Using a new dataset of 6681 input questions and human written hints, we evaluated the models with automatic metrics and human evaluation. Results show that a naive approach of concatenating suggested questions creates poor voice hints. Our approach, which applies a linguistically-motivated pretraining task was strongly preferred by humans for producing the most natural hints.
Answering Unanswered Questions through Semantic Reformulations in Spoken QA
Jun 03, 2023
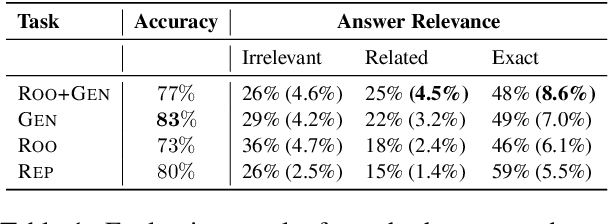
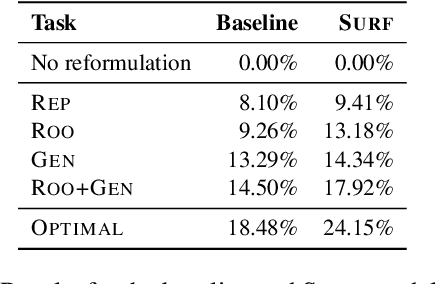
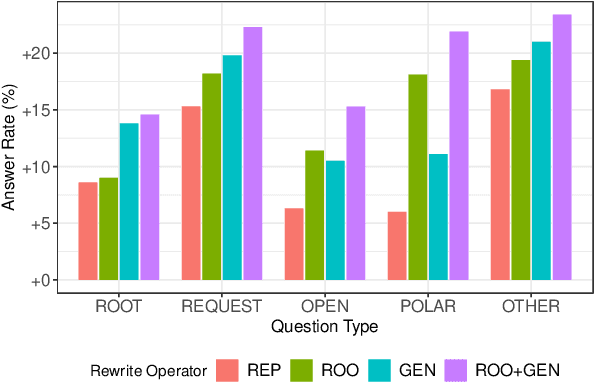
Spoken Question Answering (QA) is a key feature of voice assistants, usually backed by multiple QA systems. Users ask questions via spontaneous speech which can contain disfluencies, errors, and informal syntax or phrasing. This is a major challenge in QA, causing unanswered questions or irrelevant answers, and leading to bad user experiences. We analyze failed QA requests to identify core challenges: lexical gaps, proposition types, complex syntactic structure, and high specificity. We propose a Semantic Question Reformulation (SURF) model offering three linguistically-grounded operations (repair, syntactic reshaping, generalization) to rewrite questions to facilitate answering. Offline evaluation on 1M unanswered questions from a leading voice assistant shows that SURF significantly improves answer rates: up to 24% of previously unanswered questions obtain relevant answers (75%). Live deployment shows positive impact for millions of customers with unanswered questions; explicit relevance feedback shows high user satisfaction.
Directional Privacy for Deep Learning
Nov 09, 2022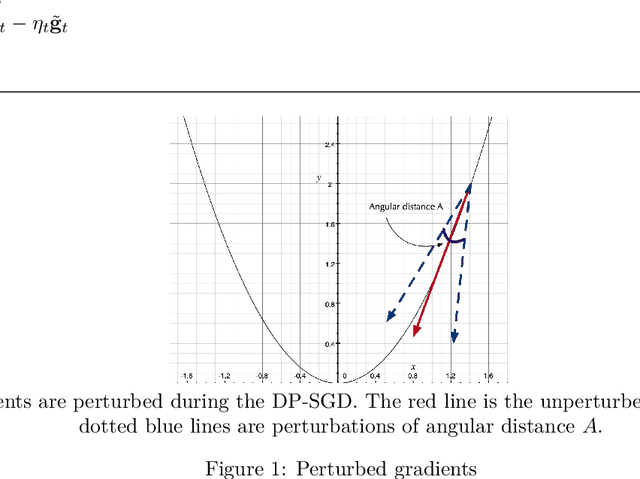
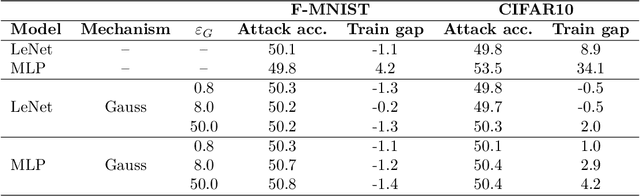
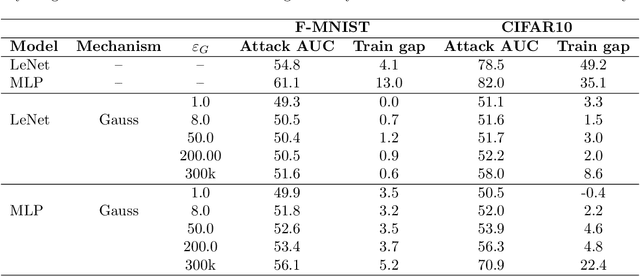

Differentially Private Stochastic Gradient Descent (DP-SGD) is a key method for applying privacy in the training of deep learning models. This applies isotropic Gaussian noise to gradients during training, which can perturb these gradients in any direction, damaging utility. Metric DP, however, can provide alternative mechanisms based on arbitrary metrics that might be more suitable. In this paper we apply \textit{directional privacy}, via a mechanism based on the von Mises-Fisher (VMF) distribution, to perturb gradients in terms of \textit{angular distance} so that gradient direction is broadly preserved. We show that this provides $\epsilon d$-privacy for deep learning training, rather than the $(\epsilon, \delta)$-privacy of the Gaussian mechanism; and that experimentally, on key datasets, the VMF mechanism can outperform the Gaussian in the utility-privacy trade-off.