 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic Learning: A Framework for Decentralized Learning with Model Fragmentation
Feb 04, 2026Decentralized learning (DL) enables collaborative machine learning (ML) without a central server, making it suitable for settings where training data cannot be centrally hosted. We introduce Mosaic Learning, a DL framework that decomposes models into fragments and disseminates them independently across the network. Fragmentation reduces redundant communication across correlated parameters and enables more diverse information propagation without increasing communication cost. We theoretically show that Mosaic Learning (i) shows state-of-the-art worst-case convergence rate, and (ii) leverages parameter correlation in an ML model, improving contraction by reducing the highest eigenvalue of a simplified system. We empirically evaluate Mosaic Learning on four learning tasks and observe up to 12 percentage points higher node-level test accuracy compared to epidemic learning (EL), a state-of-the-art baseline. In summary, Mosaic Learning improves DL performance without sacrificing its utility or efficiency, and positions itself as a new DL standard.
Robust ML Auditing using Prior Knowledge
May 07, 2025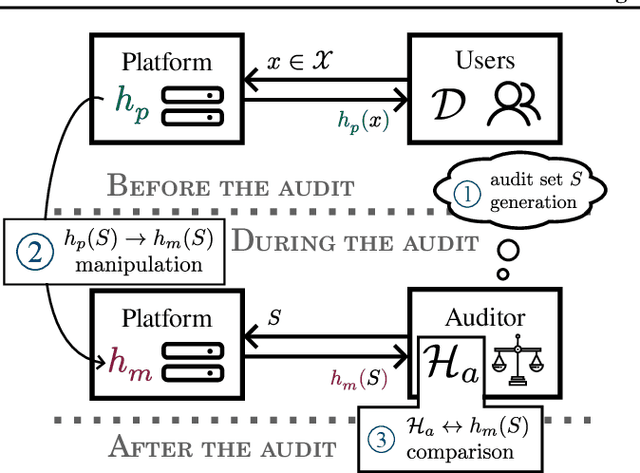

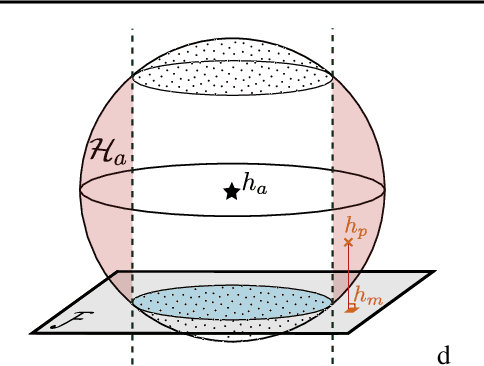
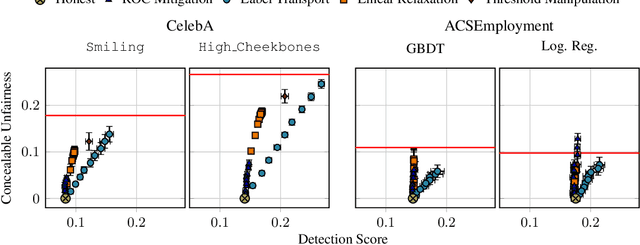
The rapid adoption of ML decision-making systems across products and services has led to a set of regulations on how such systems should behave and be built. Among all the technical challenges to enforcing these regulations, one crucial, yet under-explored problem is the risk of manipulation while these systems are being audited for fairness. This manipulation occurs when a platform deliberately alters its answers to a regulator to pass an audit without modifying its answers to other users. In this paper, we introduce a novel approach to manipulation-proof auditing by taking into account the auditor's prior knowledge of the task solved by the platform. We first demonstrate that regulators must not rely on public priors (e.g. a public dataset), as platforms could easily fool the auditor in such cases. We then formally establish the conditions under which an auditor can prevent audit manipulations using prior knowledge about the ground truth. Finally, our experiments with two standard datasets exemplify the maximum level of unfairness a platform can hide before being detected as malicious. Our formalization and generalization of manipulation-proof auditing with a prior opens up new research directions for more robust fairness audits.
Mitigating Membership Inference Vulnerability in Personalized Federated Learning
Mar 12, 2025Federated Learning (FL) has emerged as a promising paradigm for collaborative model training without the need to share clients' personal data, thereby preserving privacy. However, the non-IID nature of the clients' data introduces major challenges for FL, highlighting the importance of personalized federated learning (PFL) methods. In PFL, models are trained to cater to specific feature distributions present in the population data. A notable method for PFL is the Iterative Federated Clustering Algorithm (IFCA), which mitigates the concerns associated with the non-IID-ness by grouping clients with similar data distributions. While it has been shown that IFCA enhances both accuracy and fairness, its strategy of dividing the population into smaller clusters increases vulnerability to Membership Inference Attacks (MIA), particularly among minorities with limited training samples. In this paper, we introduce IFCA-MIR, an improved version of IFCA that integrates MIA risk assessment into the clustering process. Allowing clients to select clusters based on both model performance and MIA vulnerability, IFCA-MIR achieves an improved performance with respect to accuracy, fairness, and privacy. We demonstrate that IFCA-MIR significantly reduces MIA risk while maintaining comparable model accuracy and fairness as the original IFCA.
Comparing privacy notions for protection against reconstruction attacks in machine learning
Feb 06, 2025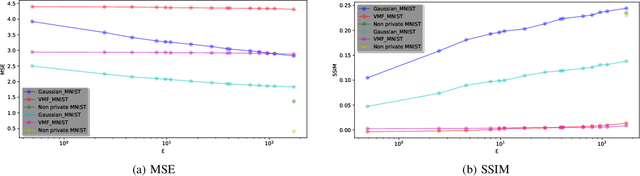



Within the machine learning community, reconstruction attacks are a principal concern and have been identified even in federated learning (FL), which was designed with privacy preservation in mind. In response to these threats, the privacy community recommends the use of differential privacy (DP) in the stochastic gradient descent algorithm, termed DP-SGD. However, the proliferation of variants of DP in recent years\textemdash such as metric privacy\textemdash has made it challenging to conduct a fair comparison between different mechanisms due to the different meanings of the privacy parameters $\epsilon$ and $\delta$ across different variants. Thus, interpreting the practical implications of $\epsilon$ and $\delta$ in the FL context and amongst variants of DP remains ambiguous. In this paper, we lay a foundational framework for comparing mechanisms with differing notions of privacy guarantees, namely $(\epsilon,\delta)$-DP and metric privacy. We provide two foundational means of comparison: firstly, via the well-established $(\epsilon,\delta)$-DP guarantees, made possible through the R\'enyi differential privacy framework; and secondly, via Bayes' capacity, which we identify as an appropriate measure for reconstruction threats.
Distributed, communication-efficient, and differentially private estimation of KL divergence
Nov 25, 2024



A key task in managing distributed, sensitive data is to measure the extent to which a distribution changes. Understanding this drift can effectively support a variety of federated learning and analytics tasks. However, in many practical settings sharing such information can be undesirable (e.g., for privacy concerns) or infeasible (e.g., for high communication costs). In this work, we describe novel algorithmic approaches for estimating the KL divergence of data across federated models of computation, under differential privacy. We analyze their theoretical properties and present an empirical study of their performance. We explore parameter settings that optimize the accuracy of the algorithm catering to each of the settings; these provide sub-variations that are applicable to real-world tasks, addressing different context- and application-specific trust level requirements. Our experimental results confirm that our private estimators achieve accuracy comparable to a baseline algorithm without differential privacy guarantees.
Boosting Asynchronous Decentralized Learning with Model Fragmentation
Oct 16, 2024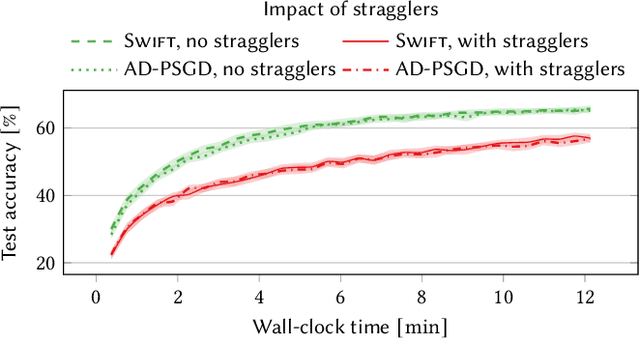

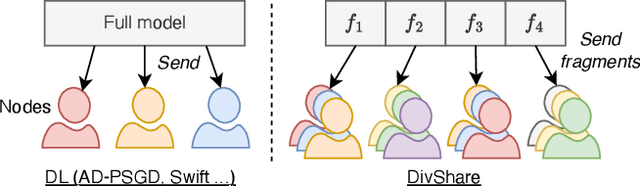
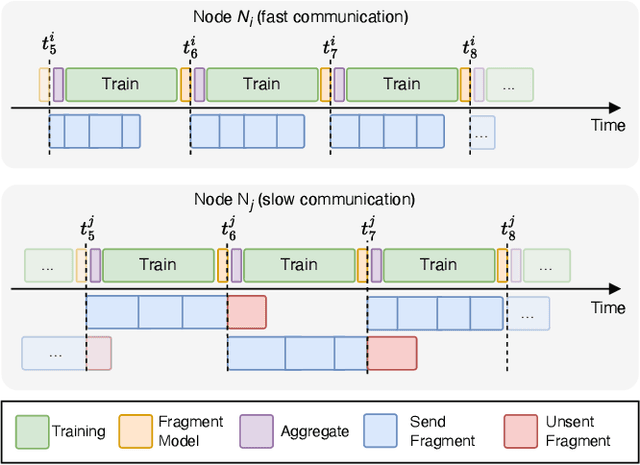
Decentralized learning (DL) is an emerging technique that allows nodes on the web to collaboratively train machine learning models without sharing raw data. Dealing with stragglers, i.e., nodes with slower compute or communication than others, is a key challenge in DL. We present DivShare, a novel asynchronous DL algorithm that achieves fast model convergence in the presence of communication stragglers. DivShare achieves this by having nodes fragment their models into parameter subsets and send, in parallel to computation, each subset to a random sample of other nodes instead of sequentially exchanging full models. The transfer of smaller fragments allows more efficient usage of the collective bandwidth and enables nodes with slow network links to quickly contribute with at least some of their model parameters. By theoretically proving the convergence of DivShare, we provide, to the best of our knowledge, the first formal proof of convergence for a DL algorithm that accounts for the effects of asynchronous communication with delays. We experimentally evaluate DivShare against two state-of-the-art DL baselines, AD-PSGD and Swift, and with two standard datasets, CIFAR-10 and MovieLens. We find that DivShare with communication stragglers lowers time-to-accuracy by up to 3.9x compared to AD-PSGD on the CIFAR-10 dataset. Compared to baselines, DivShare also achieves up to 19.4% better accuracy and 9.5% lower test loss on the CIFAR-10 and MovieLens datasets, respectively.
Fair Decentralized Learning
Oct 03, 2024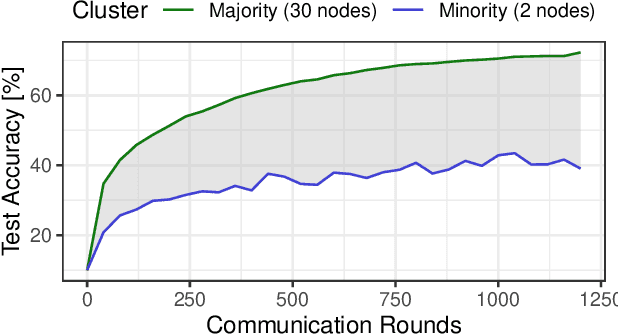


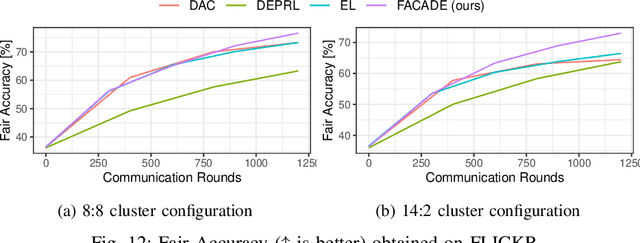
Decentralized learning (DL) is an emerging approach that enables nodes to collaboratively train a machine learning model without sharing raw data. In many application domains, such as healthcare, this approach faces challenges due to the high level of heterogeneity in the training data's feature space. Such feature heterogeneity lowers model utility and negatively impacts fairness, particularly for nodes with under-represented training data. In this paper, we introduce \textsc{Facade}, a clustering-based DL algorithm specifically designed for fair model training when the training data exhibits several distinct features. The challenge of \textsc{Facade} is to assign nodes to clusters, one for each feature, based on the similarity in the features of their local data, without requiring individual nodes to know apriori which cluster they belong to. \textsc{Facade} (1) dynamically assigns nodes to their appropriate clusters over time, and (2) enables nodes to collaboratively train a specialized model for each cluster in a fully decentralized manner. We theoretically prove the convergence of \textsc{Facade}, implement our algorithm, and compare it against three state-of-the-art baselines. Our experimental results on three datasets demonstrate the superiority of our approach in terms of model accuracy and fairness compared to all three competitors. Compared to the best-performing baseline, \textsc{Facade} on the CIFAR-10 dataset also reduces communication costs by 32.3\% to reach a target accuracy when cluster sizes are imbalanced.
Bayes' capacity as a measure for reconstruction attacks in federated learning
Jun 19, 2024

Within the machine learning community, reconstruction attacks are a principal attack of concern and have been identified even in federated learning, which was designed with privacy preservation in mind. In federated learning, it has been shown that an adversary with knowledge of the machine learning architecture is able to infer the exact value of a training element given an observation of the weight updates performed during stochastic gradient descent. In response to these threats, the privacy community recommends the use of differential privacy in the stochastic gradient descent algorithm, termed DP-SGD. However, DP has not yet been formally established as an effective countermeasure against reconstruction attacks. In this paper, we formalise the reconstruction threat model using the information-theoretic framework of quantitative information flow. We show that the Bayes' capacity, related to the Sibson mutual information of order infinity, represents a tight upper bound on the leakage of the DP-SGD algorithm to an adversary interested in performing a reconstruction attack. We provide empirical results demonstrating the effectiveness of this measure for comparing mechanisms against reconstruction threats.
Secure Aggregation Meets Sparsification in Decentralized Learning
May 14, 2024Decentralized learning (DL) faces increased vulnerability to privacy breaches due to sophisticated attacks on machine learning (ML) models. Secure aggregation is a computationally efficient cryptographic technique that enables multiple parties to compute an aggregate of their private data while keeping their individual inputs concealed from each other and from any central aggregator. To enhance communication efficiency in DL, sparsification techniques are used, selectively sharing only the most crucial parameters or gradients in a model, thereby maintaining efficiency without notably compromising accuracy. However, applying secure aggregation to sparsified models in DL is challenging due to the transmission of disjoint parameter sets by distinct nodes, which can prevent masks from canceling out effectively. This paper introduces CESAR, a novel secure aggregation protocol for DL designed to be compatible with existing sparsification mechanisms. CESAR provably defends against honest-but-curious adversaries and can be formally adapted to counteract collusion between them. We provide a foundational understanding of the interaction between the sparsification carried out by the nodes and the proportion of the parameters shared under CESAR in both colluding and non-colluding environments, offering analytical insight into the working and applicability of the protocol. Experiments on a network with 48 nodes in a 3-regular topology show that with random subsampling, CESAR is always within 0.5% accuracy of decentralized parallel stochastic gradient descent (D-PSGD), while adding only 11% of data overhead. Moreover, it surpasses the accuracy on TopK by up to 0.3% on independent and identically distributed (IID) data.
Beyond Noise: Privacy-Preserving Decentralized Learning with Virtual Nodes
Apr 15, 2024Decentralized learning (DL) enables collaborative learning without a server and without training data leaving the users' devices. However, the models shared in DL can still be used to infer training data. Conventional privacy defenses such as differential privacy and secure aggregation fall short in effectively safeguarding user privacy in DL. We introduce Shatter, a novel DL approach in which nodes create virtual nodes (VNs) to disseminate chunks of their full model on their behalf. This enhances privacy by (i) preventing attackers from collecting full models from other nodes, and (ii) hiding the identity of the original node that produced a given model chunk. We theoretically prove the convergence of Shatter and provide a formal analysis demonstrating how Shatter reduces the efficacy of attacks compared to when exchanging full models between participating nodes. We evaluate the convergence and attack resilience of Shatter with existing DL algorithms, with heterogeneous datasets, and against three standard privacy attacks, including gradient inversion. Our evaluation shows that Shatter not only renders these privacy attacks infeasible when each node operates 16 VNs but also exhibits a positive impact on model convergence compared to standard DL. This enhanced privacy comes with a manageable increase in communication volume.