 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic Learning: A Framework for Decentralized Learning with Model Fragmentation
Feb 04, 2026Decentralized learning (DL) enables collaborative machine learning (ML) without a central server, making it suitable for settings where training data cannot be centrally hosted. We introduce Mosaic Learning, a DL framework that decomposes models into fragments and disseminates them independently across the network. Fragmentation reduces redundant communication across correlated parameters and enables more diverse information propagation without increasing communication cost. We theoretically show that Mosaic Learning (i) shows state-of-the-art worst-case convergence rate, and (ii) leverages parameter correlation in an ML model, improving contraction by reducing the highest eigenvalue of a simplified system. We empirically evaluate Mosaic Learning on four learning tasks and observe up to 12 percentage points higher node-level test accuracy compared to epidemic learning (EL), a state-of-the-art baseline. In summary, Mosaic Learning improves DL performance without sacrificing its utility or efficiency, and positions itself as a new DL standard.
Optimizing Agentic Workflows using Meta-tools
Jan 29, 2026Agentic AI enables LLM to dynamically reason, plan, and interact with tools to solve complex tasks. However, agentic workflows often require many iterative reasoning steps and tool invocations, leading to significant operational expense, end-to-end latency and failures due to hallucinations. This work introduces Agent Workflow Optimization (AWO), a framework that identifies and optimizes redundant tool execution patterns to improve the efficiency and robustness of agentic workflows. AWO analyzes existing workflow traces to discover recurring sequences of tool calls and transforms them into meta-tools, which are deterministic, composite tools that bundle multiple agent actions into a single invocation. Meta-tools bypass unnecessary intermediate LLM reasoning steps and reduce operational cost while also shortening execution paths, leading to fewer failures. Experiments on two agentic AI benchmarks show that AWO reduces the number of LLM calls up to 11.9% while also increasing the task success rate by up to 4.2 percent points.
Collaborative Agentic AI Needs Interoperability Across Ecosystems
May 25, 2025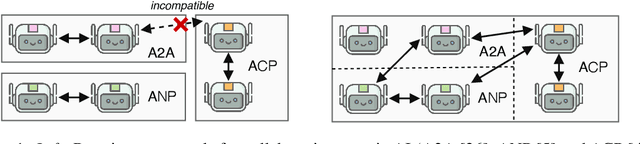
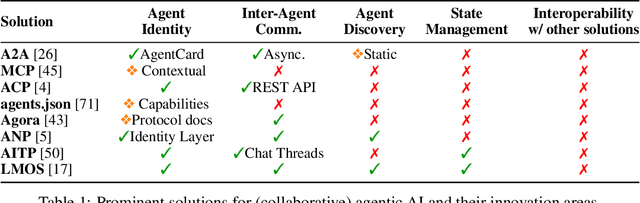
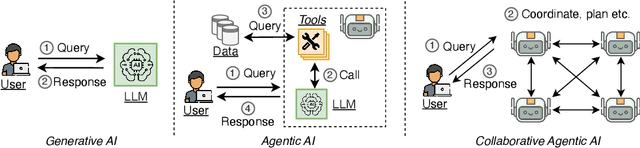
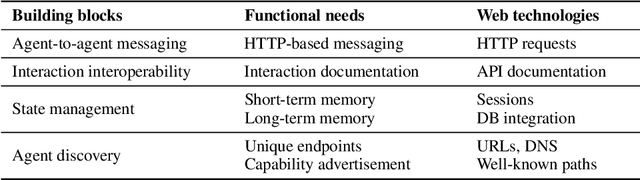
Collaborative agentic AI is projected to transform entire industries by enabling AI-powered agents to autonomously perceive, plan, and act within digital environments. Yet, current solutions in this field are all built in isolation, and we are rapidly heading toward a landscape of fragmented, incompatible ecosystems. In this position paper, we argue that interoperability, achieved by the adoption of minimal standards, is essential to ensure open, secure, web-scale, and widely-adopted agentic ecosystems. To this end, we devise a minimal architectural foundation for collaborative agentic AI, named Web of Agents, which is composed of four components: agent-to-agent messaging, interaction interoperability, state management, and agent discovery. Web of Agents adopts existing standards and reuses existing infrastructure where possible. With Web of Agents, we take the first but critical step toward interoperable agentic systems and offer a pragmatic path forward before ecosystem fragmentation becomes the norm.
Revisiting Ensembling in One-Shot Federated Learning
Nov 11, 2024
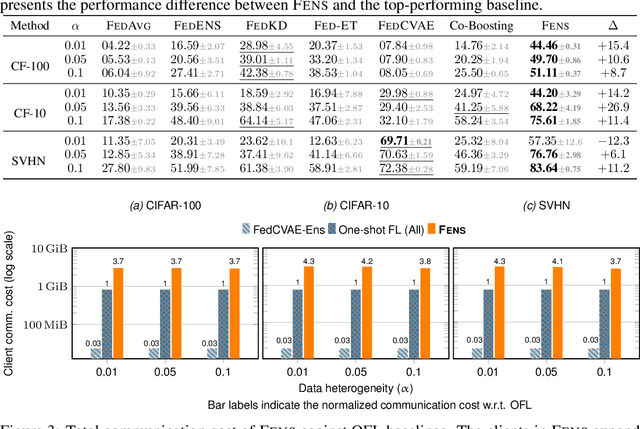
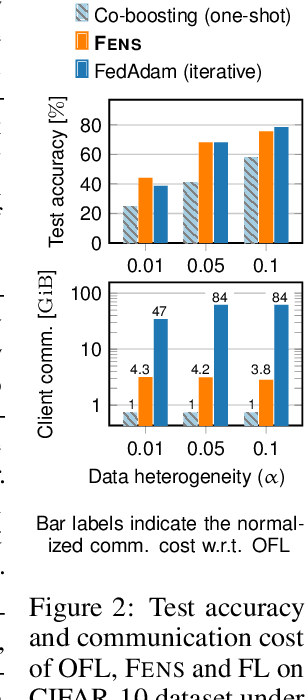

Federated learning (FL) is an appealing approach to training machine learning models without sharing raw data. However, standard FL algorithms are iterative and thus induce a significant communication cost. One-shot federated learning (OFL) trades the iterative exchange of models between clients and the server with a single round of communication, thereby saving substantially on communication costs. Not surprisingly, OFL exhibits a performance gap in terms of accuracy with respect to FL, especially under high data heterogeneity. We introduce FENS, a novel federated ensembling scheme that approaches the accuracy of FL with the communication efficiency of OFL. Learning in FENS proceeds in two phases: first, clients train models locally and send them to the server, similar to OFL; second, clients collaboratively train a lightweight prediction aggregator model using FL. We showcase the effectiveness of FENS through exhaustive experiments spanning several datasets and heterogeneity levels. In the particular case of heterogeneously distributed CIFAR-10 dataset, FENS achieves up to a 26.9% higher accuracy over state-of-the-art (SOTA) OFL, being only 3.1% lower than FL. At the same time, FENS incurs at most 4.3x more communication than OFL, whereas FL is at least 10.9x more communication-intensive than FENS.
Boosting Asynchronous Decentralized Learning with Model Fragmentation
Oct 16, 2024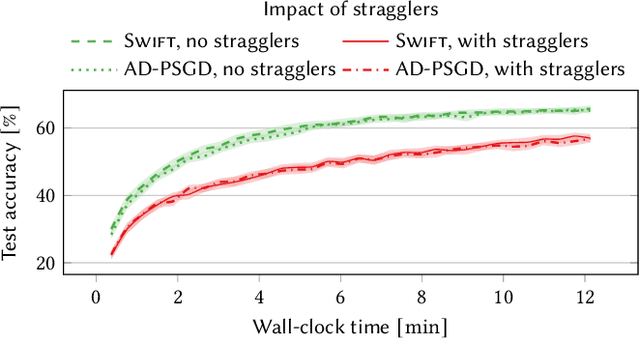

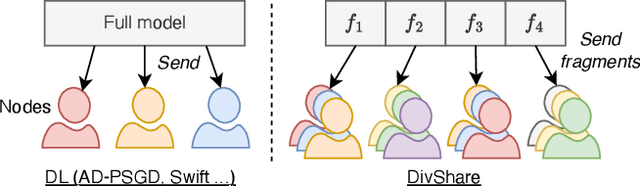
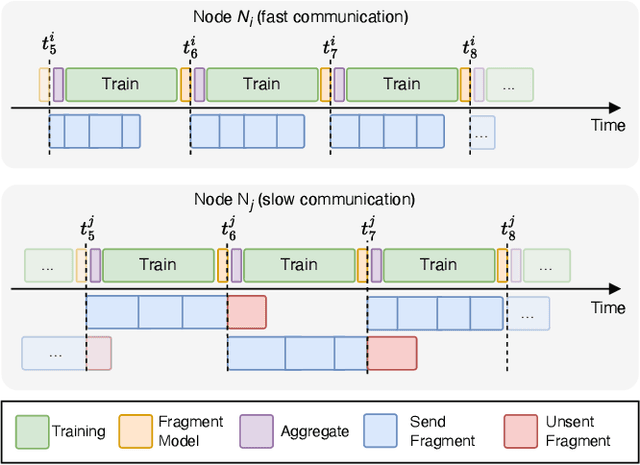
Decentralized learning (DL) is an emerging technique that allows nodes on the web to collaboratively train machine learning models without sharing raw data. Dealing with stragglers, i.e., nodes with slower compute or communication than others, is a key challenge in DL. We present DivShare, a novel asynchronous DL algorithm that achieves fast model convergence in the presence of communication stragglers. DivShare achieves this by having nodes fragment their models into parameter subsets and send, in parallel to computation, each subset to a random sample of other nodes instead of sequentially exchanging full models. The transfer of smaller fragments allows more efficient usage of the collective bandwidth and enables nodes with slow network links to quickly contribute with at least some of their model parameters. By theoretically proving the convergence of DivShare, we provide, to the best of our knowledge, the first formal proof of convergence for a DL algorithm that accounts for the effects of asynchronous communication with delays. We experimentally evaluate DivShare against two state-of-the-art DL baselines, AD-PSGD and Swift, and with two standard datasets, CIFAR-10 and MovieLens. We find that DivShare with communication stragglers lowers time-to-accuracy by up to 3.9x compared to AD-PSGD on the CIFAR-10 dataset. Compared to baselines, DivShare also achieves up to 19.4% better accuracy and 9.5% lower test loss on the CIFAR-10 and MovieLens datasets, respectively.
Fair Decentralized Learning
Oct 03, 2024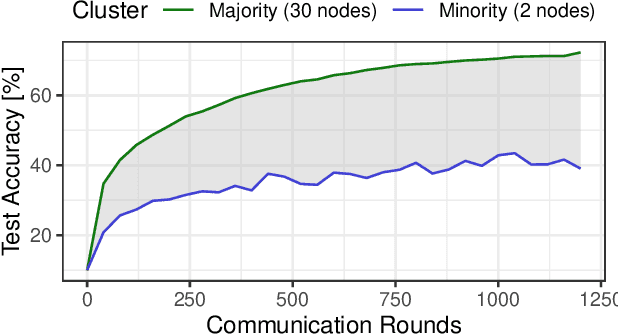


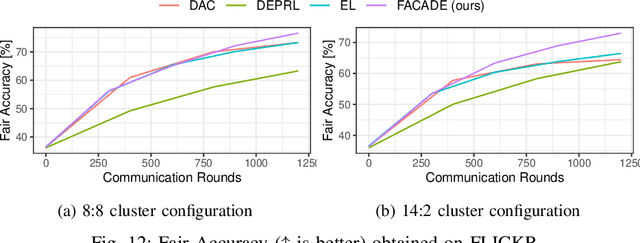
Decentralized learning (DL) is an emerging approach that enables nodes to collaboratively train a machine learning model without sharing raw data. In many application domains, such as healthcare, this approach faces challenges due to the high level of heterogeneity in the training data's feature space. Such feature heterogeneity lowers model utility and negatively impacts fairness, particularly for nodes with under-represented training data. In this paper, we introduce \textsc{Facade}, a clustering-based DL algorithm specifically designed for fair model training when the training data exhibits several distinct features. The challenge of \textsc{Facade} is to assign nodes to clusters, one for each feature, based on the similarity in the features of their local data, without requiring individual nodes to know apriori which cluster they belong to. \textsc{Facade} (1) dynamically assigns nodes to their appropriate clusters over time, and (2) enables nodes to collaboratively train a specialized model for each cluster in a fully decentralized manner. We theoretically prove the convergence of \textsc{Facade}, implement our algorithm, and compare it against three state-of-the-art baselines. Our experimental results on three datasets demonstrate the superiority of our approach in terms of model accuracy and fairness compared to all three competitors. Compared to the best-performing baseline, \textsc{Facade} on the CIFAR-10 dataset also reduces communication costs by 32.3\% to reach a target accuracy when cluster sizes are imbalanced.
Energy-Aware Decentralized Learning with Intermittent Model Training
Jul 01, 2024



Decentralized learning (DL) offers a powerful framework where nodes collaboratively train models without sharing raw data and without the coordination of a central server. In the iterative rounds of DL, models are trained locally, shared with neighbors in the topology, and aggregated with other models received from neighbors. Sharing and merging models contribute to convergence towards a consensus model that generalizes better across the collective data captured at training time. In addition, the energy consumption while sharing and merging model parameters is negligible compared to the energy spent during the training phase. Leveraging this fact, we present SkipTrain, a novel DL algorithm, which minimizes energy consumption in decentralized learning by strategically skipping some training rounds and substituting them with synchronization rounds. These training-silent periods, besides saving energy, also allow models to better mix and finally produce models with superior accuracy than typical DL algorithms that train at every round. Our empirical evaluations with 256 nodes demonstrate that SkipTrain reduces energy consumption by 50% and increases model accuracy by up to 12% compared to D-PSGD, the conventional DL algorithm.
Secure Aggregation Meets Sparsification in Decentralized Learning
May 14, 2024Decentralized learning (DL) faces increased vulnerability to privacy breaches due to sophisticated attacks on machine learning (ML) models. Secure aggregation is a computationally efficient cryptographic technique that enables multiple parties to compute an aggregate of their private data while keeping their individual inputs concealed from each other and from any central aggregator. To enhance communication efficiency in DL, sparsification techniques are used, selectively sharing only the most crucial parameters or gradients in a model, thereby maintaining efficiency without notably compromising accuracy. However, applying secure aggregation to sparsified models in DL is challenging due to the transmission of disjoint parameter sets by distinct nodes, which can prevent masks from canceling out effectively. This paper introduces CESAR, a novel secure aggregation protocol for DL designed to be compatible with existing sparsification mechanisms. CESAR provably defends against honest-but-curious adversaries and can be formally adapted to counteract collusion between them. We provide a foundational understanding of the interaction between the sparsification carried out by the nodes and the proportion of the parameters shared under CESAR in both colluding and non-colluding environments, offering analytical insight into the working and applicability of the protocol. Experiments on a network with 48 nodes in a 3-regular topology show that with random subsampling, CESAR is always within 0.5% accuracy of decentralized parallel stochastic gradient descent (D-PSGD), while adding only 11% of data overhead. Moreover, it surpasses the accuracy on TopK by up to 0.3% on independent and identically distributed (IID) data.
Beyond Noise: Privacy-Preserving Decentralized Learning with Virtual Nodes
Apr 15, 2024Decentralized learning (DL) enables collaborative learning without a server and without training data leaving the users' devices. However, the models shared in DL can still be used to infer training data. Conventional privacy defenses such as differential privacy and secure aggregation fall short in effectively safeguarding user privacy in DL. We introduce Shatter, a novel DL approach in which nodes create virtual nodes (VNs) to disseminate chunks of their full model on their behalf. This enhances privacy by (i) preventing attackers from collecting full models from other nodes, and (ii) hiding the identity of the original node that produced a given model chunk. We theoretically prove the convergence of Shatter and provide a formal analysis demonstrating how Shatter reduces the efficacy of attacks compared to when exchanging full models between participating nodes. We evaluate the convergence and attack resilience of Shatter with existing DL algorithms, with heterogeneous datasets, and against three standard privacy attacks, including gradient inversion. Our evaluation shows that Shatter not only renders these privacy attacks infeasible when each node operates 16 VNs but also exhibits a positive impact on model convergence compared to standard DL. This enhanced privacy comes with a manageable increase in communication volume.
Low-Cost Privacy-Aware Decentralized Learning
Mar 18, 2024
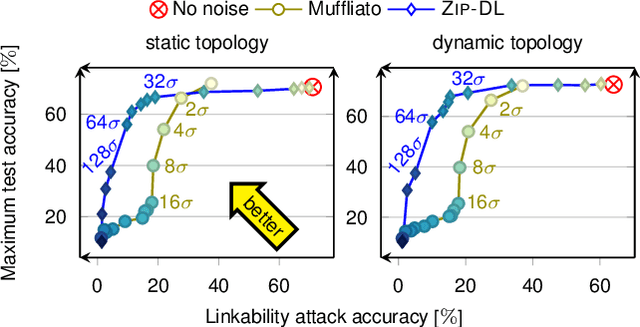
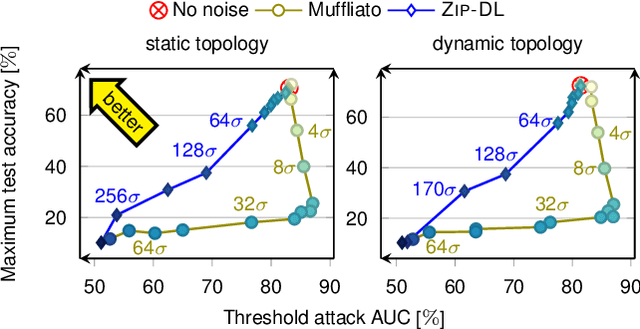
This paper introduces ZIP-DL, a novel privacy-aware decentralized learning (DL) algorithm that relies on adding correlated noise to each model update during the model training process. This technique ensures that the added noise almost neutralizes itself during the aggregation process due to its correlation, thus minimizing the impact on model accuracy. In addition, ZIP-DL does not require multiple communication rounds for noise cancellation, addressing the common trade-off between privacy protection and communication overhead. We provide theoretical guarantees for both convergence speed and privacy guarantees, thereby making ZIP-DL applicable to practical scenarios. Our extensive experimental study shows that ZIP-DL achieves the best trade-off between vulnerability and accuracy. In particular, ZIP-DL (i) reduces the effectiveness of a linkability attack by up to 52 points compared to baseline DL, and (ii) achieves up to 37 more accuracy points for the same vulnerability under membership inference attacks against a privacy-preserving competitor