 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Neighbors Know: Leveraging Local Neighborhoods for Backdoor Detection in Decentralized Learning
May 19, 2026Decentralized learning (DL) is an emerging machine learning paradigm where nodes collaboratively train models without a central server. However, the collaborative nature of DL makes it vulnerable to backdoor attacks, where a model is taught to behave normally on standard inputs while executing hidden, malicious actions when encountering data with specific triggers. Backdoor attacks in DL remain understudied and existing defenses often overlook DL constraints. We introduce Argus, a novel backdoor detection framework native to DL that requires neither a central coordinator nor prior knowledge of the trigger. In Argus, honest nodes locally analyze received model updates to identify potential backdoor triggers. Nodes then collectively share their triggers with their neighbors and use a structural similarity metric to separate true backdoors from false alarms induced by data heterogeneity. A key insight is that false positive triggers exhibit inconsistencies across participants while true positive ones show consistent patterns. Model updates that fail this collaborative test are rejected, and persistently malicious senders are eventually evicted. We provide the first theoretical convergence guarantees for a DL-specific backdoor detection mechanism, showing that filtering out suspicious model updates with high probability preserves a convergence rate comparable to standard DL. We implement and evaluate Argus on three standard datasets and against three state-of-the-art baselines. Across settings, Argus reduces attack success rates by up to 90 points compared to no defense, while preserving model utility within 5 percentage points of an omniscient oracle. Furthermore, the effectiveness of Argus compared to baselines improves as data heterogeneity increases.
Certified Unlearning for Neural Networks
Jun 08, 2025
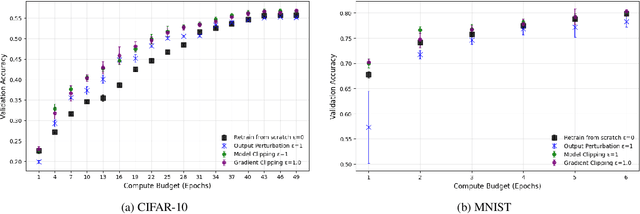
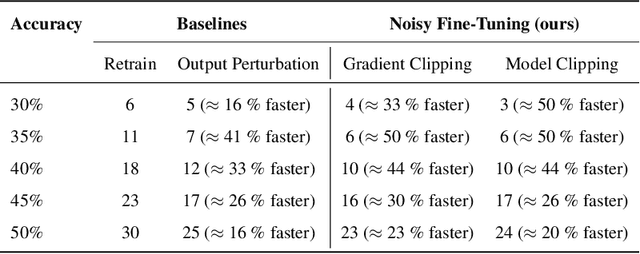
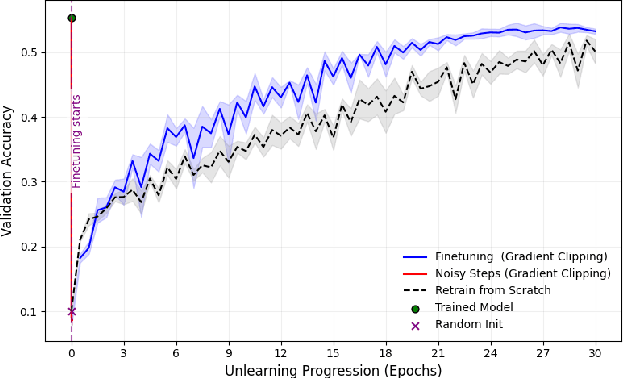
We address the problem of machine unlearning, where the goal is to remove the influence of specific training data from a model upon request, motivated by privacy concerns and regulatory requirements such as the "right to be forgotten." Unfortunately, existing methods rely on restrictive assumptions or lack formal guarantees. To this end, we propose a novel method for certified machine unlearning, leveraging the connection between unlearning and privacy amplification by stochastic post-processing. Our method uses noisy fine-tuning on the retain data, i.e., data that does not need to be removed, to ensure provable unlearning guarantees. This approach requires no assumptions about the underlying loss function, making it broadly applicable across diverse settings. We analyze the theoretical trade-offs in efficiency and accuracy and demonstrate empirically that our method not only achieves formal unlearning guarantees but also performs effectively in practice, outperforming existing baselines. Our code is available at https://github.com/stair-lab/certified-unlearningneural-networks-icml-2025
ByzFL: Research Framework for Robust Federated Learning
May 30, 2025We present ByzFL, an open-source Python library for developing and benchmarking robust federated learning (FL) algorithms. ByzFL provides a unified and extensible framework that includes implementations of state-of-the-art robust aggregators, a suite of configurable attacks, and tools for simulating a variety of FL scenarios, including heterogeneous data distributions, multiple training algorithms, and adversarial threat models. The library enables systematic experimentation via a single JSON-based configuration file and includes built-in utilities for result visualization. Compatible with PyTorch tensors and NumPy arrays, ByzFL is designed to facilitate reproducible research and rapid prototyping of robust FL solutions. ByzFL is available at https://byzfl.epfl.ch/, with source code hosted on GitHub: https://github.com/LPD-EPFL/byzfl.
Towards Trustworthy Federated Learning with Untrusted Participants
May 03, 2025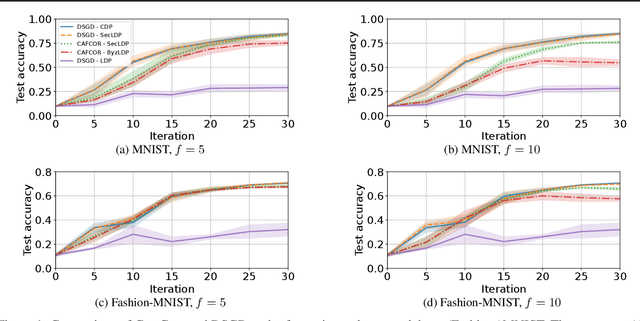
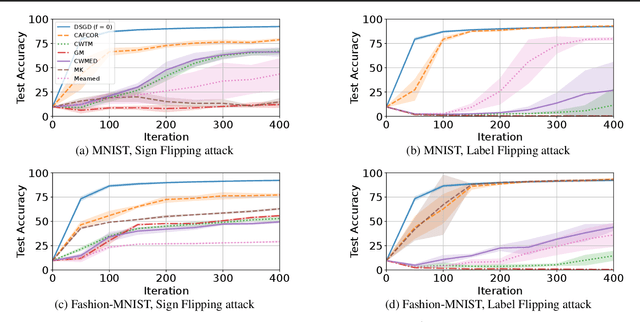
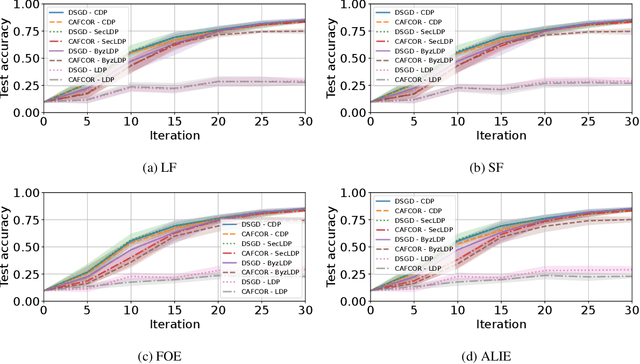
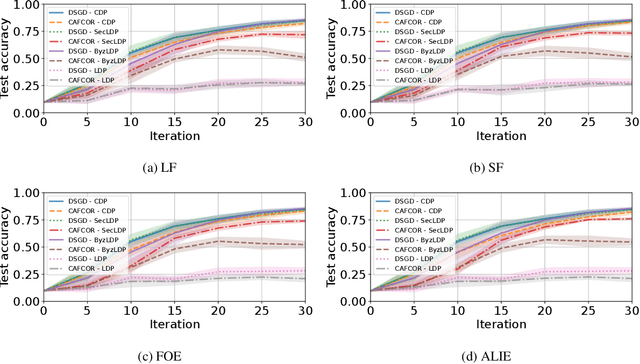
Resilience against malicious parties and data privacy are essential for trustworthy distributed learning, yet achieving both with good utility typically requires the strong assumption of a trusted central server. This paper shows that a significantly weaker assumption suffices: each pair of workers shares a randomness seed unknown to others. In a setting where malicious workers may collude with an untrusted server, we propose CafCor, an algorithm that integrates robust gradient aggregation with correlated noise injection, leveraging shared randomness between workers. We prove that CafCor achieves strong privacy-utility trade-offs, significantly outperforming local differential privacy (DP) methods, which do not make any trust assumption, while approaching central DP utility, where the server is fully trusted. Empirical results on standard benchmarks validate CafCor's practicality, showing that privacy and robustness can coexist in distributed systems without sacrificing utility or trusting the server.
Efficient Federated Search for Retrieval-Augmented Generation
Feb 26, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various domains but remain susceptible to hallucinations and inconsistencies, limiting their reliability. Retrieval-augmented generation (RAG) mitigates these issues by grounding model responses in external knowledge sources. Existing RAG workflows often leverage a single vector database, which is impractical in the common setting where information is distributed across multiple repositories. We introduce RAGRoute, a novel mechanism for federated RAG search. RAGRoute dynamically selects relevant data sources at query time using a lightweight neural network classifier. By not querying every data source, this approach significantly reduces query overhead, improves retrieval efficiency, and minimizes the retrieval of irrelevant information. We evaluate RAGRoute using the MIRAGE and MMLU benchmarks and demonstrate its effectiveness in retrieving relevant documents while reducing the number of queries. RAGRoute reduces the total number of queries up to 77.5% and communication volume up to 76.2%.
The Utility and Complexity of In- and Out-of-Distribution Machine Unlearning
Dec 12, 2024



Machine unlearning, the process of selectively removing data from trained models, is increasingly crucial for addressing privacy concerns and knowledge gaps post-deployment. Despite this importance, existing approaches are often heuristic and lack formal guarantees. In this paper, we analyze the fundamental utility, time, and space complexity trade-offs of approximate unlearning, providing rigorous certification analogous to differential privacy. For in-distribution forget data -- data similar to the retain set -- we show that a surprisingly simple and general procedure, empirical risk minimization with output perturbation, achieves tight unlearning-utility-complexity trade-offs, addressing a previous theoretical gap on the separation from unlearning "for free" via differential privacy, which inherently facilitates the removal of such data. However, such techniques fail with out-of-distribution forget data -- data significantly different from the retain set -- where unlearning time complexity can exceed that of retraining, even for a single sample. To address this, we propose a new robust and noisy gradient descent variant that provably amortizes unlearning time complexity without compromising utility.
Revisiting Ensembling in One-Shot Federated Learning
Nov 11, 2024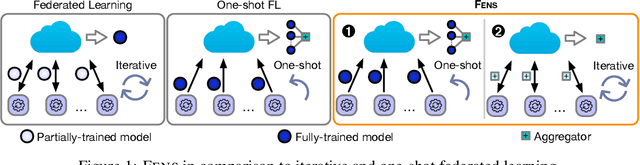
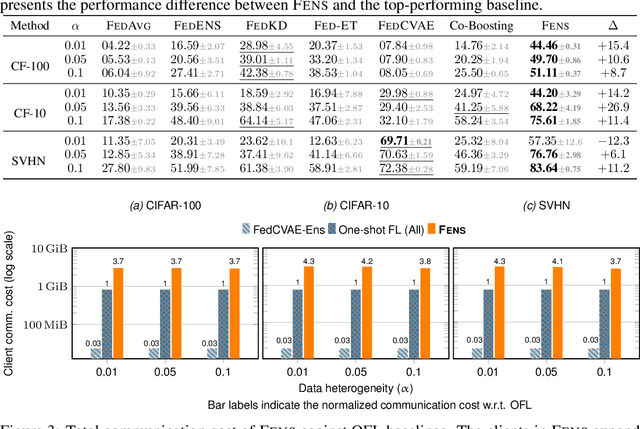
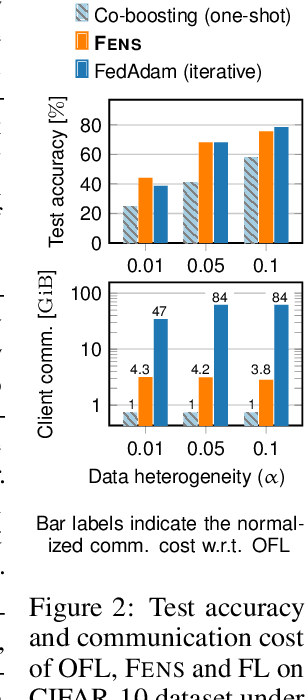

Federated learning (FL) is an appealing approach to training machine learning models without sharing raw data. However, standard FL algorithms are iterative and thus induce a significant communication cost. One-shot federated learning (OFL) trades the iterative exchange of models between clients and the server with a single round of communication, thereby saving substantially on communication costs. Not surprisingly, OFL exhibits a performance gap in terms of accuracy with respect to FL, especially under high data heterogeneity. We introduce FENS, a novel federated ensembling scheme that approaches the accuracy of FL with the communication efficiency of OFL. Learning in FENS proceeds in two phases: first, clients train models locally and send them to the server, similar to OFL; second, clients collaboratively train a lightweight prediction aggregator model using FL. We showcase the effectiveness of FENS through exhaustive experiments spanning several datasets and heterogeneity levels. In the particular case of heterogeneously distributed CIFAR-10 dataset, FENS achieves up to a 26.9% higher accuracy over state-of-the-art (SOTA) OFL, being only 3.1% lower than FL. At the same time, FENS incurs at most 4.3x more communication than OFL, whereas FL is at least 10.9x more communication-intensive than FENS.
Fine-Tuning Personalization in Federated Learning to Mitigate Adversarial Clients
Sep 30, 2024

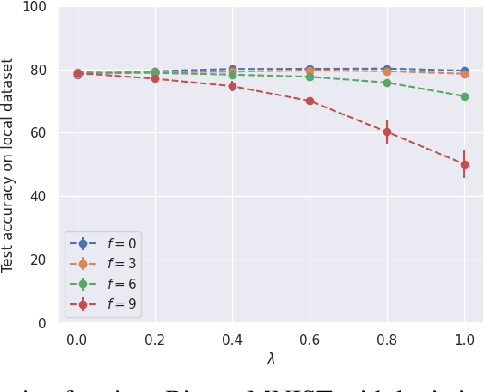

Federated learning (FL) is an appealing paradigm that allows a group of machines (a.k.a. clients) to learn collectively while keeping their data local. However, due to the heterogeneity between the clients' data distributions, the model obtained through the use of FL algorithms may perform poorly on some client's data. Personalization addresses this issue by enabling each client to have a different model tailored to their own data while simultaneously benefiting from the other clients' data. We consider an FL setting where some clients can be adversarial, and we derive conditions under which full collaboration fails. Specifically, we analyze the generalization performance of an interpolated personalized FL framework in the presence of adversarial clients, and we precisely characterize situations when full collaboration performs strictly worse than fine-tuned personalization. Our analysis determines how much we should scale down the level of collaboration, according to data heterogeneity and the tolerable fraction of adversarial clients. We support our findings with empirical results on mean estimation and binary classification problems, considering synthetic and benchmark image classification datasets.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Overcoming the Challenges of Batch Normalization in Federated Learning
May 23, 2024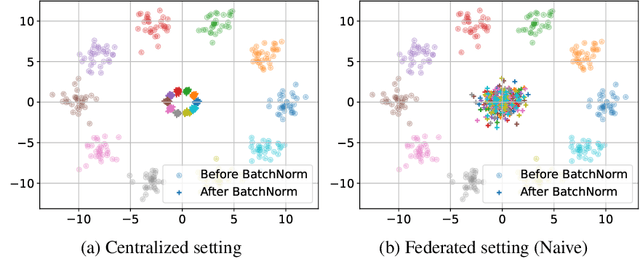
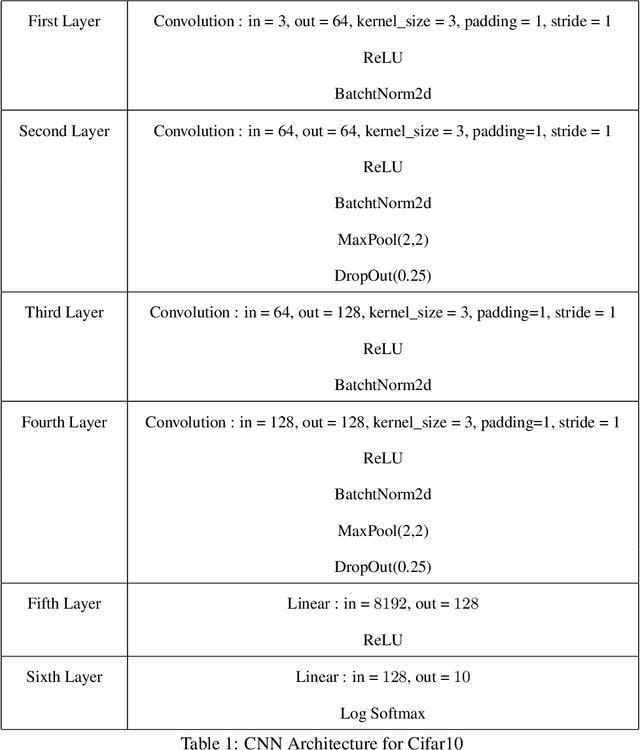
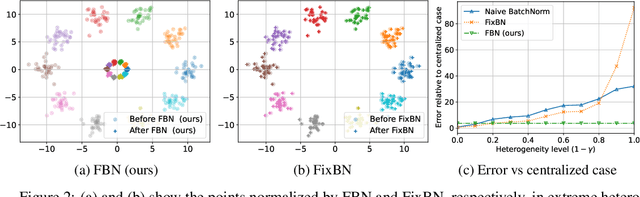
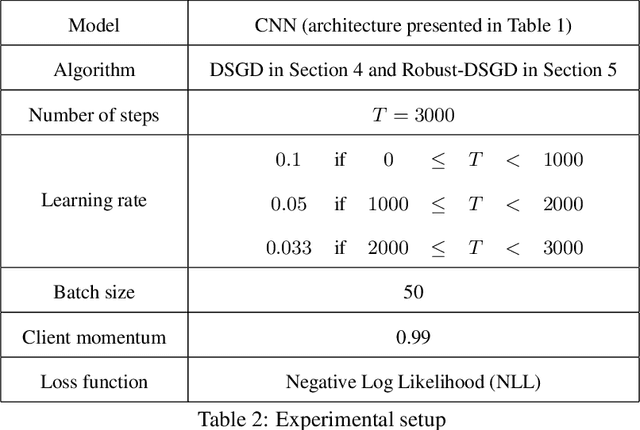
Batch normalization has proven to be a very beneficial mechanism to accelerate the training and improve the accuracy of deep neural networks in centralized environments. Yet, the scheme faces significant challenges in federated learning, especially under high data heterogeneity. Essentially, the main challenges arise from external covariate shifts and inconsistent statistics across clients. We introduce in this paper Federated BatchNorm (FBN), a novel scheme that restores the benefits of batch normalization in federated learning. Essentially, FBN ensures that the batch normalization during training is consistent with what would be achieved in a centralized execution, hence preserving the distribution of the data, and providing running statistics that accurately approximate the global statistics. FBN thereby reduces the external covariate shift and matches the evaluation performance of the centralized setting. We also show that, with a slight increase in complexity, we can robustify FBN to mitigate erroneous statistics and potentially adversarial attacks.