 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective LoRA Adapter Routing using Task Representations
Jan 29, 2026Low-rank adaptation (LoRA) enables parameter efficient specialization of large language models (LLMs) through modular adapters, resulting in rapidly growing public adapter pools spanning diverse tasks. Effectively using these adapters requires routing: selecting and composing the appropriate adapters for a query. We introduce LORAUTER, a novel routing framework that selects and composes LoRA adapters using task representations rather than adapter characteristics. Unlike existing approaches that map queries directly to adapters, LORAUTER routes queries via task embeddings derived from small validation sets and does not require adapter training data. By operating at the task level, LORAUTER achieves efficient routing that scales with the number of tasks rather than the number of adapters. Experiments across multiple tasks show that LORAUTER consistently outperforms baseline routing approaches, matching Oracle performance (101.2%) when task-aligned adapters exist and achieving state-of-the-art results on unseen tasks (+5.2 points). We further demonstrate the robustness of LORAUTER to very large, noisy adapter pools by scaling it to over 1500 adapters.
Leveraging Approximate Caching for Faster Retrieval-Augmented Generation
Mar 07, 2025Retrieval-augmented generation (RAG) enhances the reliability of large language model (LLM) answers by integrating external knowledge. However, RAG increases the end-to-end inference time since looking for relevant documents from large vector databases is computationally expensive. To address this, we introduce Proximity, an approximate key-value cache that optimizes the RAG workflow by leveraging similarities in user queries. Instead of treating each query independently, Proximity reuses previously retrieved documents when similar queries appear, reducing reliance on expensive vector database lookups. We evaluate Proximity on the MMLU and MedRAG benchmarks, demonstrating that it significantly improves retrieval efficiency while maintaining response accuracy. Proximity reduces retrieval latency by up to 59% while maintaining accuracy and lowers the computational burden on the vector database. We also experiment with different similarity thresholds and quantify the trade-off between speed and recall. Our work shows that approximate caching is a viable and effective strategy for optimizing RAG-based systems.
Efficient Federated Search for Retrieval-Augmented Generation
Feb 26, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various domains but remain susceptible to hallucinations and inconsistencies, limiting their reliability. Retrieval-augmented generation (RAG) mitigates these issues by grounding model responses in external knowledge sources. Existing RAG workflows often leverage a single vector database, which is impractical in the common setting where information is distributed across multiple repositories. We introduce RAGRoute, a novel mechanism for federated RAG search. RAGRoute dynamically selects relevant data sources at query time using a lightweight neural network classifier. By not querying every data source, this approach significantly reduces query overhead, improves retrieval efficiency, and minimizes the retrieval of irrelevant information. We evaluate RAGRoute using the MIRAGE and MMLU benchmarks and demonstrate its effectiveness in retrieving relevant documents while reducing the number of queries. RAGRoute reduces the total number of queries up to 77.5% and communication volume up to 76.2%.
Accelerating Transfer Learning with Near-Data Computation on Cloud Object Stores
Oct 16, 2022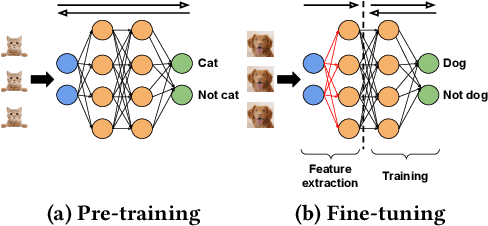
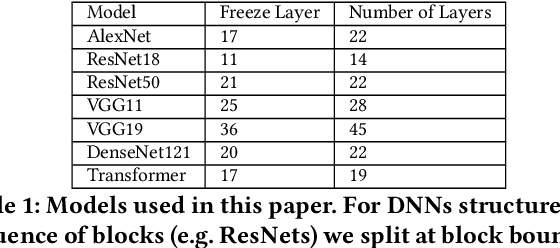
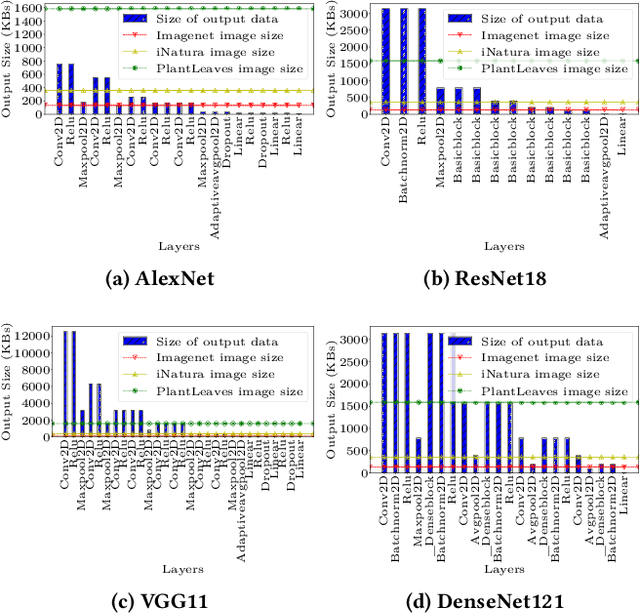
Storage disaggregation is fundamental to today's cloud due to cost and scalability benefits. Unfortunately, this design must cope with an inherent network bottleneck between the storage and the compute tiers. The widely deployed mitigation strategy is to provide computational resources next to storage to push down a part of an application and thus reduce the amount of data transferred to the compute tier. Overall, users of disaggregated storage need to consider two main constraints: the network may remain a bottleneck, and the storage-side computational resources are limited. This paper identifies transfer learning (TL) as a natural fit for the disaggregated cloud. TL, famously described as the next driver of ML commercial success, is widely popular and has broad-range applications. We show how to leverage the unique structure of TL's fine-tuning phase (i.e., a combination of feature extraction and training) to flexibly address the aforementioned constraints and improve both user and operator-centric metrics. The key to improving user-perceived performance is to mitigate the network bottleneck by carefully splitting the TL deep neural network (DNN) such that feature extraction is, partially or entirely, executed next to storage. Crucially, such splitting enables decoupling the batch size of feature extraction from the training batch size, facilitating efficient storage-side batch size adaptation to increase concurrency in the storage tier while avoiding out-of-memory errors. Guided by these insights, we present HAPI, a processing system for TL that spans the compute and storage tiers while remaining transparent to the user. Our evaluation with several DNNs, such as ResNet, VGG, and Transformer, shows up to 11x improvement in application runtime and up to 8.3x reduction in the data transferred from the storage to the compute tier compared to running the computation in the compute tier.
Multi-Step Critiquing User Interface for Recommender Systems
Aug 05, 2021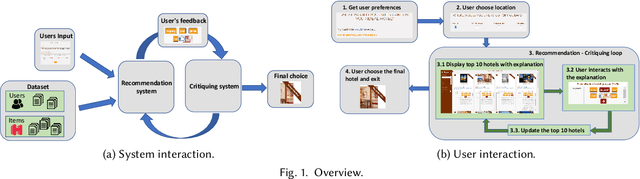
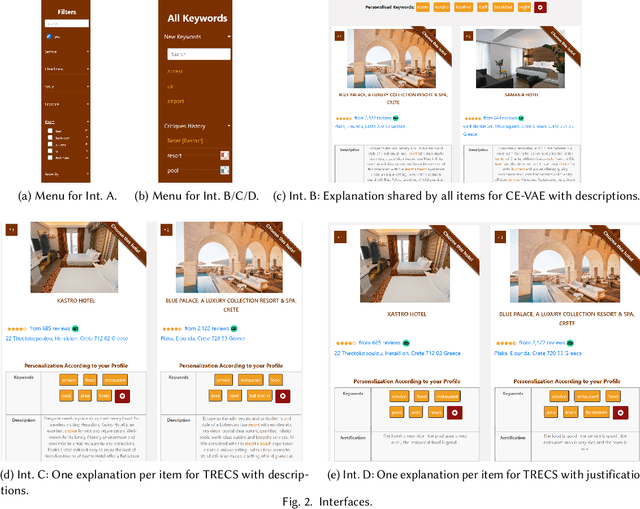
Recommendations with personalized explanations have been shown to increase user trust and perceived quality and help users make better decisions. Moreover, such explanations allow users to provide feedback by critiquing them. Several algorithms for recommender systems with multi-step critiquing have therefore been developed. However, providing a user-friendly interface based on personalized explanations and critiquing has not been addressed in the last decade. In this paper, we introduce four different web interfaces (available under https://lia.epfl.ch/critiquing/) helping users making decisions and finding their ideal item. We have chosen the hotel recommendation domain as a use case even though our approach is trivially adaptable for other domains. Moreover, our system is model-agnostic (for both recommender systems and critiquing models) allowing a great flexibility and further extensions. Our interfaces are above all a useful tool to help research in recommendation with critiquing. They allow to test such systems on a real use case and also to highlight some limitations of these approaches to find solutions to overcome them.
Clasificarea distribuita a mesajelor de e-mail
Jun 27, 2011A basic component in Internet applications is the electronic mail and its various implications. The paper proposes a mechanism for automatically classifying emails and create dynamic groups that belong to these messages. Proposed mechanisms will be based on natural language processing techniques and will be designed to facilitate human-machine interaction in this direction.
* ISSN 1453-1305