 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Transfer Learning with Near-Data Computation on Cloud Object Stores
Oct 16, 2022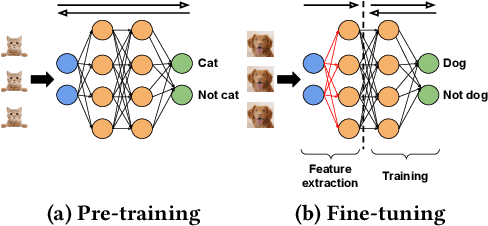
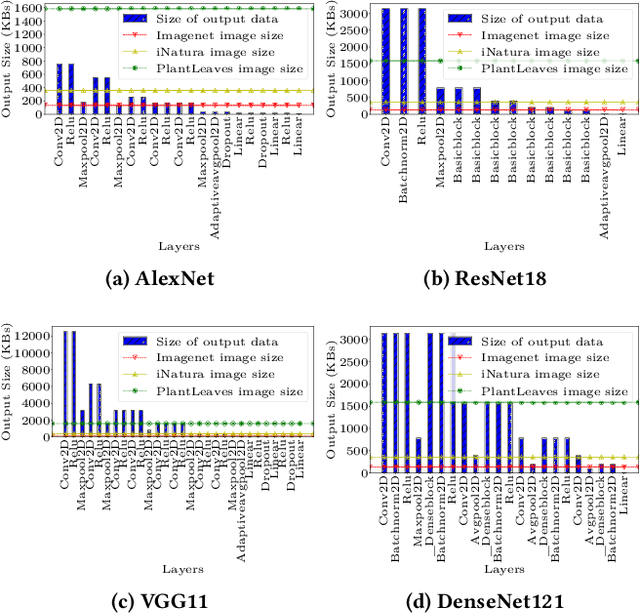
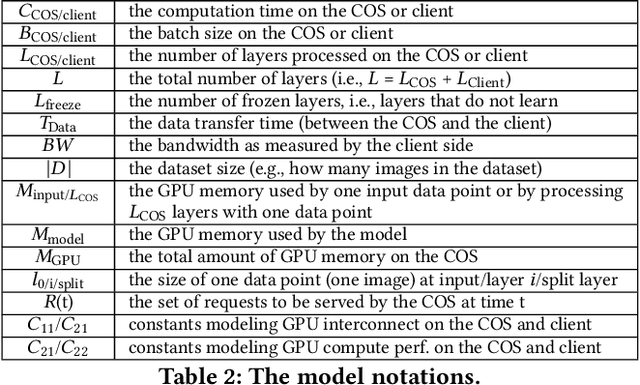
Storage disaggregation is fundamental to today's cloud due to cost and scalability benefits. Unfortunately, this design must cope with an inherent network bottleneck between the storage and the compute tiers. The widely deployed mitigation strategy is to provide computational resources next to storage to push down a part of an application and thus reduce the amount of data transferred to the compute tier. Overall, users of disaggregated storage need to consider two main constraints: the network may remain a bottleneck, and the storage-side computational resources are limited. This paper identifies transfer learning (TL) as a natural fit for the disaggregated cloud. TL, famously described as the next driver of ML commercial success, is widely popular and has broad-range applications. We show how to leverage the unique structure of TL's fine-tuning phase (i.e., a combination of feature extraction and training) to flexibly address the aforementioned constraints and improve both user and operator-centric metrics. The key to improving user-perceived performance is to mitigate the network bottleneck by carefully splitting the TL deep neural network (DNN) such that feature extraction is, partially or entirely, executed next to storage. Crucially, such splitting enables decoupling the batch size of feature extraction from the training batch size, facilitating efficient storage-side batch size adaptation to increase concurrency in the storage tier while avoiding out-of-memory errors. Guided by these insights, we present HAPI, a processing system for TL that spans the compute and storage tiers while remaining transparent to the user. Our evaluation with several DNNs, such as ResNet, VGG, and Transformer, shows up to 11x improvement in application runtime and up to 8.3x reduction in the data transferred from the storage to the compute tier compared to running the computation in the compute tier.
SecFL: Confidential Federated Learning using TEEs
Oct 07, 2021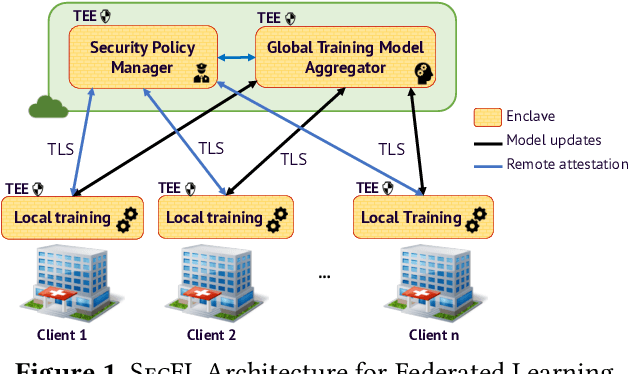
Federated Learning (FL) is an emerging machine learning paradigm that enables multiple clients to jointly train a model to take benefits from diverse datasets from the clients without sharing their local training datasets. FL helps reduce data privacy risks. Unfortunately, FL still exist several issues regarding privacy and security. First, it is possible to leak sensitive information from the shared training parameters. Second, malicious clients can collude with each other to steal data, models from regular clients or corrupt the global training model. To tackle these challenges, we propose SecFL - a confidential federated learning framework that leverages Trusted Execution Environments (TEEs). SecFL performs the global and local training inside TEE enclaves to ensure the confidentiality and integrity of the computations against powerful adversaries with privileged access. SecFL provides a transparent remote attestation mechanism, relying on the remote attestation provided by TEEs, to allow clients to attest the global training computation as well as the local training computation of each other. Thus, all malicious clients can be detected using the remote attestation mechanisms.
Perun: Secure Multi-Stakeholder Machine Learning Framework with GPU Support
Mar 31, 2021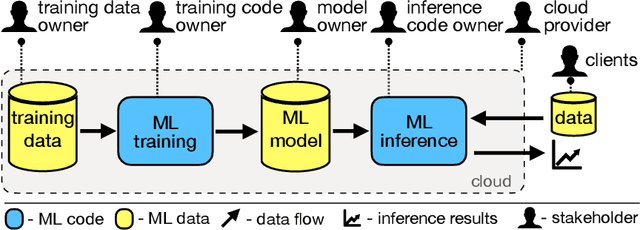

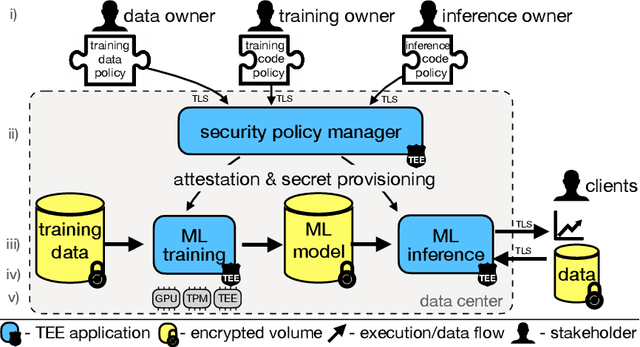
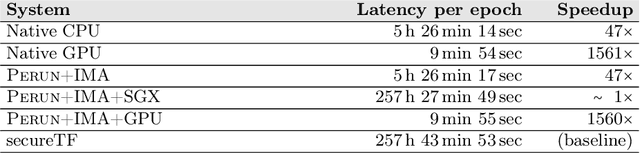
Confidential multi-stakeholder machine learning (ML) allows multiple parties to perform collaborative data analytics while not revealing their intellectual property, such as ML source code, model, or datasets. State-of-the-art solutions based on homomorphic encryption incur a large performance overhead. Hardware-based solutions, such as trusted execution environments (TEEs), significantly improve the performance in inference computations but still suffer from low performance in training computations, e.g., deep neural networks model training, because of limited availability of protected memory and lack of GPU support. To address this problem, we designed and implemented Perun, a framework for confidential multi-stakeholder machine learning that allows users to make a trade-off between security and performance. Perun executes ML training on hardware accelerators (e.g., GPU) while providing security guarantees using trusted computing technologies, such as trusted platform module and integrity measurement architecture. Less compute-intensive workloads, such as inference, execute only inside TEE, thus at a lower trusted computing base. The evaluation shows that during the ML training on CIFAR-10 and real-world medical datasets, Perun achieved a 161x to 1560x speedup compared to a pure TEE-based approach.
secureTF: A Secure TensorFlow Framework
Jan 20, 2021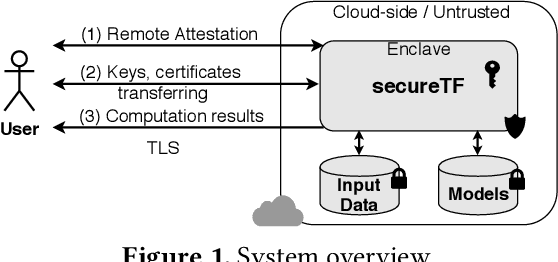

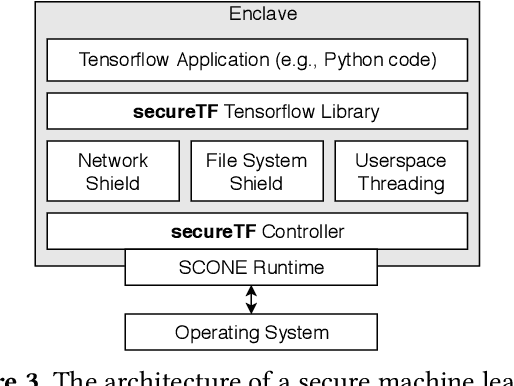
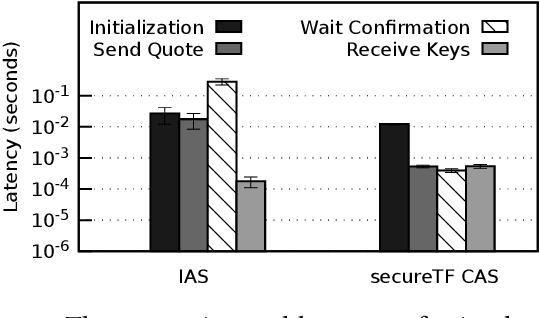
Data-driven intelligent applications in modern online services have become ubiquitous. These applications are usually hosted in the untrusted cloud computing infrastructure. This poses significant security risks since these applications rely on applying machine learning algorithms on large datasets which may contain private and sensitive information. To tackle this challenge, we designed secureTF, a distributed secure machine learning framework based on Tensorflow for the untrusted cloud infrastructure. secureTF is a generic platform to support unmodified TensorFlow applications, while providing end-to-end security for the input data, ML model, and application code. secureTF is built from ground-up based on the security properties provided by Trusted Execution Environments (TEEs). However, it extends the trust of a volatile memory region (or secure enclave) provided by the single node TEE to secure a distributed infrastructure required for supporting unmodified stateful machine learning applications running in the cloud. The paper reports on our experiences about the system design choices and the system deployment in production use-cases. We conclude with the lessons learned based on the limitations of our commercially available platform, and discuss open research problems for the future work.
* arXiv admin note: text overlap with arXiv:1902.04413
TensorSCONE: A Secure TensorFlow Framework using Intel SGX
Feb 12, 2019



Machine learning has become a critical component of modern data-driven online services. Typically, the training phase of machine learning techniques requires to process large-scale datasets which may contain private and sensitive information of customers. This imposes significant security risks since modern online services rely on cloud computing to store and process the sensitive data. In the untrusted computing infrastructure, security is becoming a paramount concern since the customers need to trust the thirdparty cloud provider. Unfortunately, this trust has been violated multiple times in the past. To overcome the potential security risks in the cloud, we answer the following research question: how to enable secure executions of machine learning computations in the untrusted infrastructure? To achieve this goal, we propose a hardware-assisted approach based on Trusted Execution Environments (TEEs), specifically Intel SGX, to enable secure execution of the machine learning computations over the private and sensitive datasets. More specifically, we propose a generic and secure machine learning framework based on Tensorflow, which enables secure execution of existing applications on the commodity untrusted infrastructure. In particular, we have built our system called TensorSCONE from ground-up by integrating TensorFlow with SCONE, a shielded execution framework based on Intel SGX. The main challenge of this work is to overcome the architectural limitations of Intel SGX in the context of building a secure TensorFlow system. Our evaluation shows that we achieve reasonable performance overheads while providing strong security properties with low TCB.