 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Transfer Learning with Near-Data Computation on Cloud Object Stores
Paper and Code
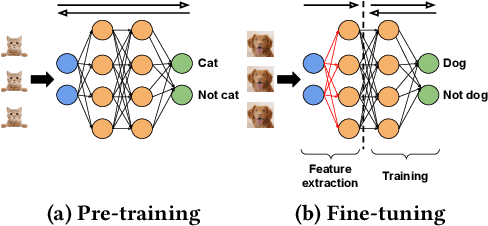
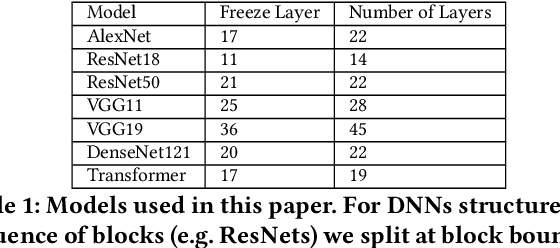
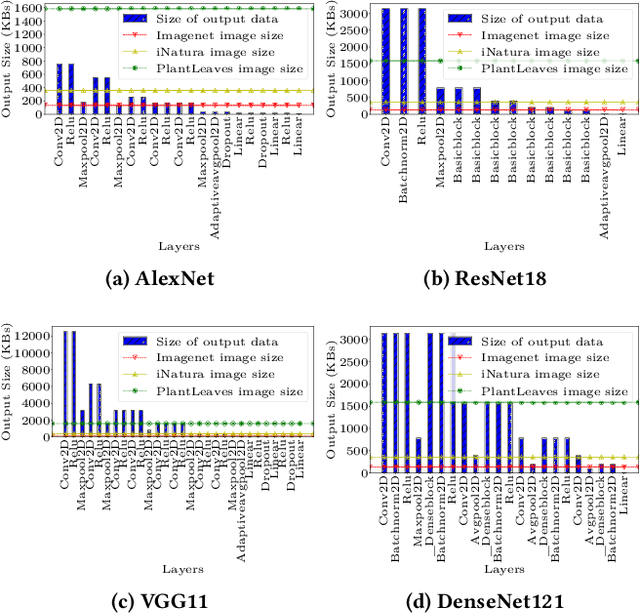
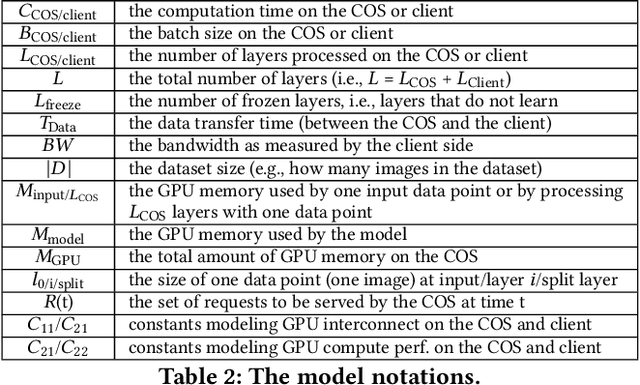
Storage disaggregation is fundamental to today's cloud due to cost and scalability benefits. Unfortunately, this design must cope with an inherent network bottleneck between the storage and the compute tiers. The widely deployed mitigation strategy is to provide computational resources next to storage to push down a part of an application and thus reduce the amount of data transferred to the compute tier. Overall, users of disaggregated storage need to consider two main constraints: the network may remain a bottleneck, and the storage-side computational resources are limited. This paper identifies transfer learning (TL) as a natural fit for the disaggregated cloud. TL, famously described as the next driver of ML commercial success, is widely popular and has broad-range applications. We show how to leverage the unique structure of TL's fine-tuning phase (i.e., a combination of feature extraction and training) to flexibly address the aforementioned constraints and improve both user and operator-centric metrics. The key to improving user-perceived performance is to mitigate the network bottleneck by carefully splitting the TL deep neural network (DNN) such that feature extraction is, partially or entirely, executed next to storage. Crucially, such splitting enables decoupling the batch size of feature extraction from the training batch size, facilitating efficient storage-side batch size adaptation to increase concurrency in the storage tier while avoiding out-of-memory errors. Guided by these insights, we present HAPI, a processing system for TL that spans the compute and storage tiers while remaining transparent to the user. Our evaluation with several DNNs, such as ResNet, VGG, and Transformer, shows up to 11x improvement in application runtime and up to 8.3x reduction in the data transferred from the storage to the compute tier compared to running the computation in the compute tier.