 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInkFM: A Foundational Model for Full-Page Online Handwritten Note Understanding
Mar 29, 2025



Tablets and styluses are increasingly popular for taking notes. To optimize this experience and ensure a smooth and efficient workflow, it's important to develop methods for accurately interpreting and understanding the content of handwritten digital notes. We introduce a foundational model called InkFM for analyzing full pages of handwritten content. Trained on a diverse mixture of tasks, this model offers a unique combination of capabilities: recognizing text in 28 different scripts, mathematical expressions recognition, and segmenting pages into distinct elements like text and drawings. Our results demonstrate that these tasks can be effectively unified within a single model, achieving SoTA text line segmentation out-of-the-box quality surpassing public baselines like docTR. Fine- or LoRA-tuning our base model on public datasets further improves the quality of page segmentation, achieves state-of the art text recognition (DeepWriting, CASIA, SCUT, and Mathwriting datasets) and sketch classification (QuickDraw). This adaptability of InkFM provides a powerful starting point for developing applications with handwritten input.
$\textit{Trans-LoRA}$: towards data-free Transferable Parameter Efficient Finetuning
May 27, 2024



Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters. These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model. This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose $\textit{Trans-LoRA}$ -- a novel method for lossless, nearly data-free transfer of LoRAs across base models. Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the $\textit{observed}$ task data subset. Training on the resulting synthetic dataset transfers LoRA modules to new models. We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.
Paraphrase and Solve: Exploring and Exploiting the Impact of Surface Form on Mathematical Reasoning in Large Language Models
Apr 17, 2024



This paper studies the relationship between the surface form of a mathematical problem and its solvability by large language models. We find that subtle alterations in the surface form can significantly impact the answer distribution and the solve rate, exposing the language model's lack of robustness and sensitivity to the surface form in reasoning through complex problems. To improve mathematical reasoning performance, we propose Self-Consistency-over-Paraphrases (SCoP), which diversifies reasoning paths from specific surface forms of the problem. We evaluate our approach on four mathematics reasoning benchmarks over three large language models and show that SCoP improves mathematical reasoning performance over vanilla self-consistency, particularly for problems initially deemed unsolvable. Finally, we provide additional experiments and discussion regarding problem difficulty and surface forms, including cross-model difficulty agreement and paraphrasing transferability, and Variance of Variations (VOV) for language model evaluation.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023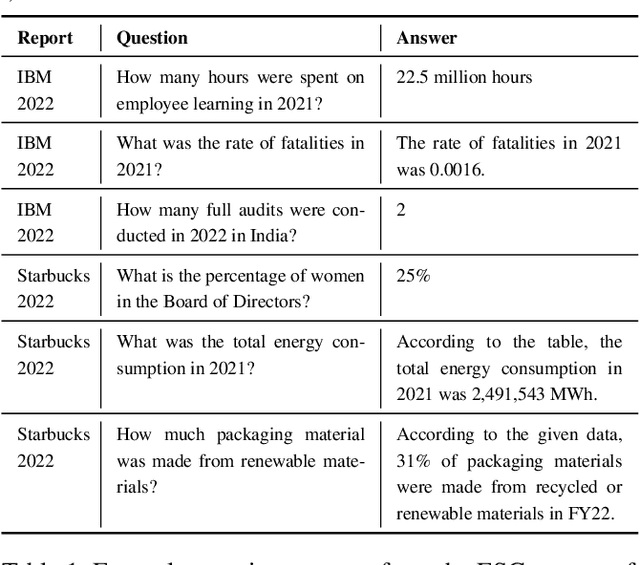
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.
Extracting Text Representations for Terms and Phrases in Technical Domains
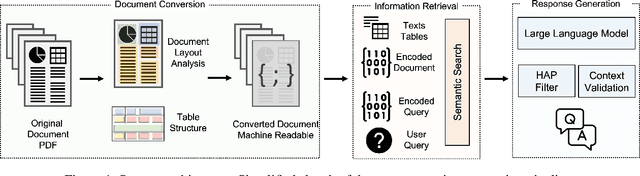
May 25, 2023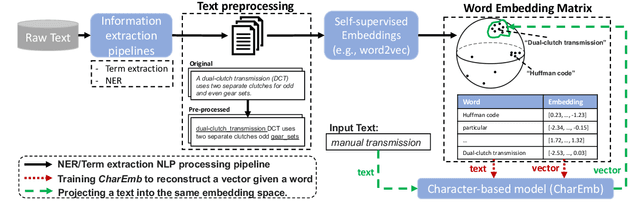
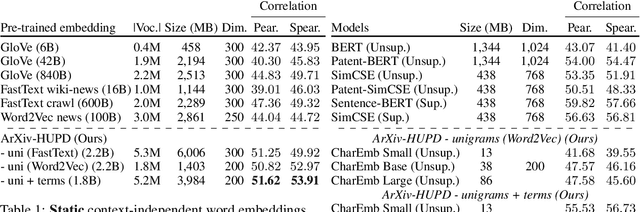
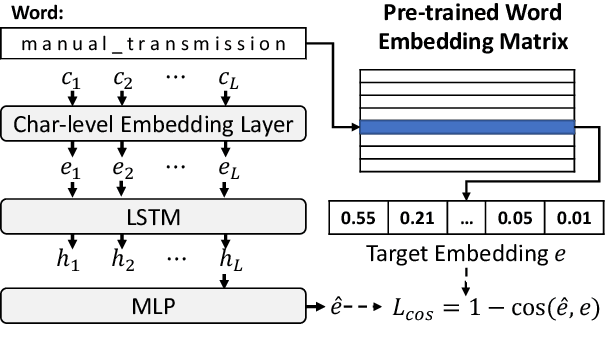

Extracting dense representations for terms and phrases is a task of great importance for knowledge discovery platforms targeting highly-technical fields. Dense representations are used as features for downstream components and have multiple applications ranging from ranking results in search to summarization. Common approaches to create dense representations include training domain-specific embeddings with self-supervised setups or using sentence encoder models trained over similarity tasks. In contrast to static embeddings, sentence encoders do not suffer from the out-of-vocabulary (OOV) problem, but impose significant computational costs. In this paper, we propose a fully unsupervised approach to text encoding that consists of training small character-based models with the objective of reconstructing large pre-trained embedding matrices. Models trained with this approach can not only match the quality of sentence encoders in technical domains, but are 5 times smaller and up to 10 times faster, even on high-end GPUs.
Unsupervised Term Extraction for Highly Technical Domains
Oct 24, 2022
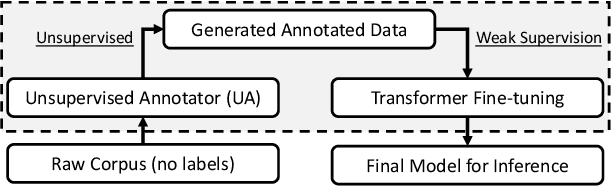

Term extraction is an information extraction task at the root of knowledge discovery platforms. Developing term extractors that are able to generalize across very diverse and potentially highly technical domains is challenging, as annotations for domains requiring in-depth expertise are scarce and expensive to obtain. In this paper, we describe the term extraction subsystem of a commercial knowledge discovery platform that targets highly technical fields such as pharma, medical, and material science. To be able to generalize across domains, we introduce a fully unsupervised annotator (UA). It extracts terms by combining novel morphological signals from sub-word tokenization with term-to-topic and intra-term similarity metrics, computed using general-domain pre-trained sentence-encoders. The annotator is used to implement a weakly-supervised setup, where transformer-models are fine-tuned (or pre-trained) over the training data generated by running the UA over large unlabeled corpora. Our experiments demonstrate that our setup can improve the predictive performance while decreasing the inference latency on both CPUs and GPUs. Our annotators provide a very competitive baseline for all the cases where annotations are not available.
Active Learning for Imbalanced Civil Infrastructure Data
Oct 19, 2022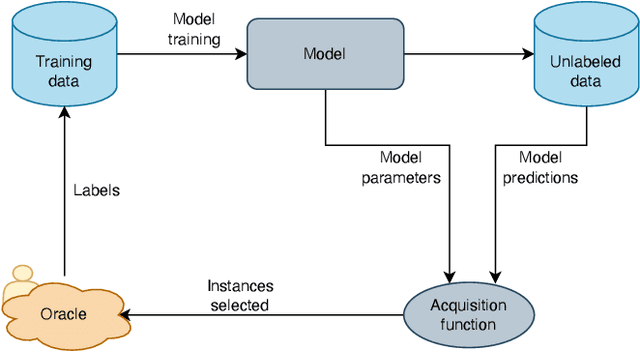


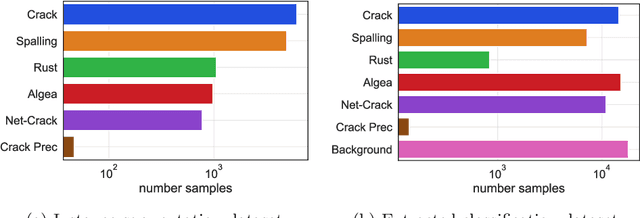
Aging civil infrastructures are closely monitored by engineers for damage and critical defects. As the manual inspection of such large structures is costly and time-consuming, we are working towards fully automating the visual inspections to support the prioritization of maintenance activities. To that end we combine recent advances in drone technology and deep learning. Unfortunately, annotation costs are incredibly high as our proprietary civil engineering dataset must be annotated by highly trained engineers. Active learning is, therefore, a valuable tool to optimize the trade-off between model performance and annotation costs. Our use-case differs from the classical active learning setting as our dataset suffers from heavy class imbalance and consists of a much larger already labeled data pool than other active learning research. We present a novel method capable of operating in this challenging setting by replacing the traditional active learning acquisition function with an auxiliary binary discriminator. We experimentally show that our novel method outperforms the best-performing traditional active learning method (BALD) by 5% and 38% accuracy on CIFAR-10 and our proprietary dataset respectively.
Textual Explanations and Critiques in Recommendation Systems
May 15, 2022



Artificial intelligence and machine learning algorithms have become ubiquitous. Although they offer a wide range of benefits, their adoption in decision-critical fields is limited by their lack of interpretability, particularly with textual data. Moreover, with more data available than ever before, it has become increasingly important to explain automated predictions. Generally, users find it difficult to understand the underlying computational processes and interact with the models, especially when the models fail to generate the outcomes or explanations, or both, correctly. This problem highlights the growing need for users to better understand the models' inner workings and gain control over their actions. This dissertation focuses on two fundamental challenges of addressing this need. The first involves explanation generation: inferring high-quality explanations from text documents in a scalable and data-driven manner. The second challenge consists in making explanations actionable, and we refer to it as critiquing. This dissertation examines two important applications in natural language processing and recommendation tasks. Overall, we demonstrate that interpretability does not come at the cost of reduced performance in two consequential applications. Our framework is applicable to other fields as well. This dissertation presents an effective means of closing the gap between promise and practice in artificial intelligence.
Interlock-Free Multi-Aspect Rationalization for Text Classification
May 13, 2022


Explanation is important for text classification tasks. One prevalent type of explanation is rationales, which are text snippets of input text that suffice to yield the prediction and are meaningful to humans. A lot of research on rationalization has been based on the selective rationalization framework, which has recently been shown to be problematic due to the interlocking dynamics. In this paper, we show that we address the interlocking problem in the multi-aspect setting, where we aim to generate multiple rationales for multiple outputs. More specifically, we propose a multi-stage training method incorporating an additional self-supervised contrastive loss that helps to generate more semantically diverse rationales. Empirical results on the beer review dataset show that our method improves significantly the rationalization performance.
Assistive Recipe Editing through Critiquing
May 05, 2022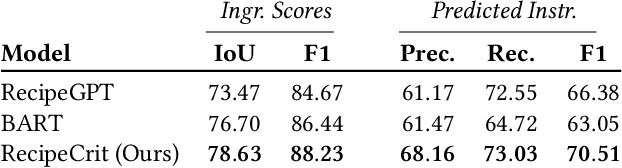
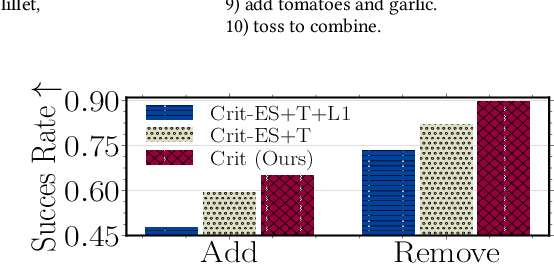
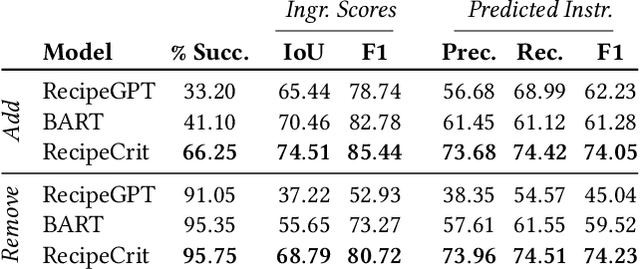

There has recently been growing interest in the automatic generation of cooking recipes that satisfy some form of dietary restrictions, thanks in part to the availability of online recipe data. Prior studies have used pre-trained language models, or relied on small paired recipe data (e.g., a recipe paired with a similar one that satisfies a dietary constraint). However, pre-trained language models generate inconsistent or incoherent recipes, and paired datasets are not available at scale. We address these deficiencies with RecipeCrit, a hierarchical denoising auto-encoder that edits recipes given ingredient-level critiques. The model is trained for recipe completion to learn semantic relationships within recipes. Our work's main innovation is our unsupervised critiquing module that allows users to edit recipes by interacting with the predicted ingredients; the system iteratively rewrites recipes to satisfy users' feedback. Experiments on the Recipe1M recipe dataset show that our model can more effectively edit recipes compared to strong language-modeling baselines, creating recipes that satisfy user constraints and are more correct, serendipitous, coherent, and relevant as measured by human judges.