 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your RAG: Dataset Taxonomy and Generation Strategies for Evaluating RAG Systems
Nov 29, 2024
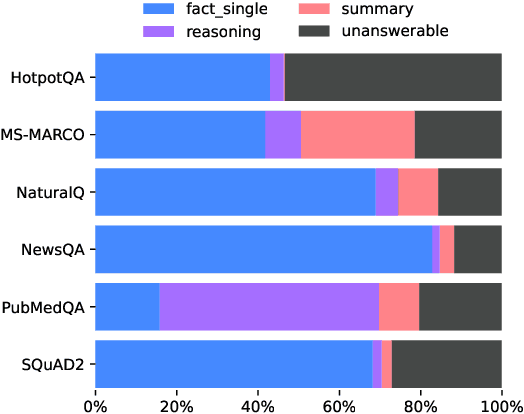
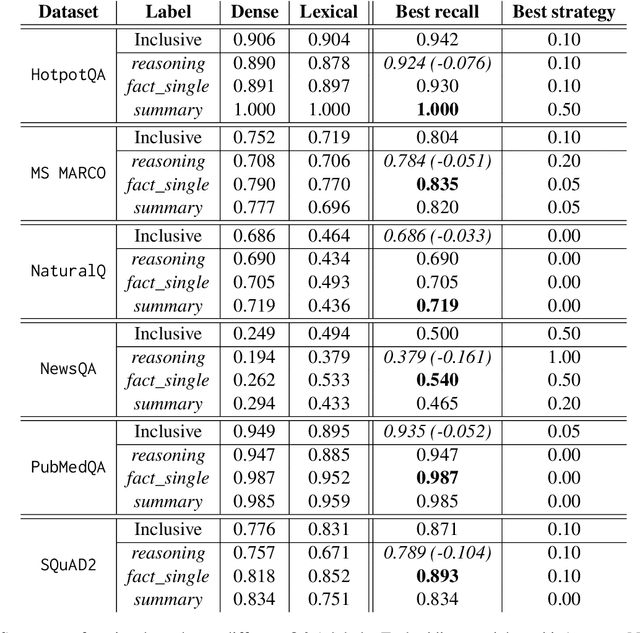
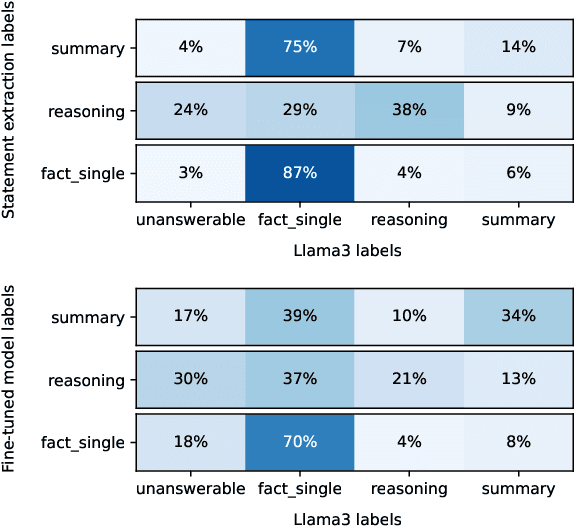
Retrieval Augmented Generation (RAG) systems are a widespread application of Large Language Models (LLMs) in the industry. While many tools exist empowering developers to build their own systems, measuring their performance locally, with datasets reflective of the system's use cases, is a technological challenge. Solutions to this problem range from non-specific and cheap (most public datasets) to specific and costly (generating data from local documents). In this paper, we show that using public question and answer (Q&A) datasets to assess retrieval performance can lead to non-optimal systems design, and that common tools for RAG dataset generation can lead to unbalanced data. We propose solutions to these issues based on the characterization of RAG datasets through labels and through label-targeted data generation. Finally, we show that fine-tuned small LLMs can efficiently generate Q&A datasets. We believe that these observations are invaluable to the know-your-data step of RAG systems development.
MaterioMiner -- An ontology-based text mining dataset for extraction of process-structure-property entities
Aug 05, 2024



While large language models learn sound statistical representations of the language and information therein, ontologies are symbolic knowledge representations that can complement the former ideally. Research at this critical intersection relies on datasets that intertwine ontologies and text corpora to enable training and comprehensive benchmarking of neurosymbolic models. We present the MaterioMiner dataset and the linked materials mechanics ontology where ontological concepts from the mechanics of materials domain are associated with textual entities within the literature corpus. Another distinctive feature of the dataset is its eminently fine-granular annotation. Specifically, 179 distinct classes are manually annotated by three raters within four publications, amounting to a total of 2191 entities that were annotated and curated. Conceptual work is presented for the symbolic representation of causal composition-process-microstructure-property relationships. We explore the annotation consistency between the three raters and perform fine-tuning of pre-trained models to showcase the feasibility of named-entity recognition model training. Reusing the dataset can foster training and benchmarking of materials language models, automated ontology construction, and knowledge graph generation from textual data.
Statements: Universal Information Extraction from Tables with Large Language Models for ESG KPIs
Jun 27, 2024Environment, Social, and Governance (ESG) KPIs assess an organization's performance on issues such as climate change, greenhouse gas emissions, water consumption, waste management, human rights, diversity, and policies. ESG reports convey this valuable quantitative information through tables. Unfortunately, extracting this information is difficult due to high variability in the table structure as well as content. We propose Statements, a novel domain agnostic data structure for extracting quantitative facts and related information. We propose translating tables to statements as a new supervised deep-learning universal information extraction task. We introduce SemTabNet - a dataset of over 100K annotated tables. Investigating a family of T5-based Statement Extraction Models, our best model generates statements which are 82% similar to the ground-truth (compared to baseline of 21%). We demonstrate the advantages of statements by applying our model to over 2700 tables from ESG reports. The homogeneous nature of statements permits exploratory data analysis on expansive information found in large collections of ESG reports.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023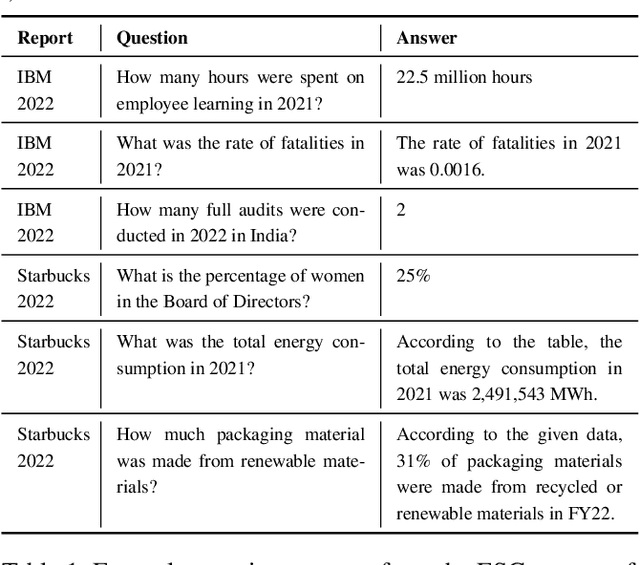
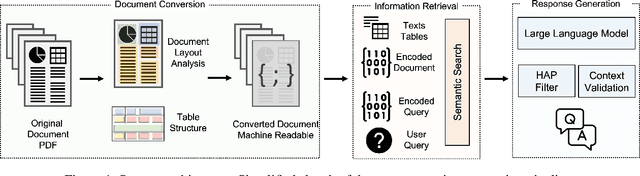
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.