 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion
Mar 14, 2025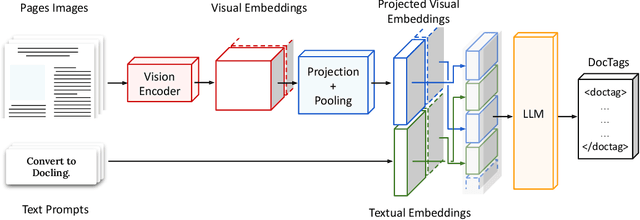
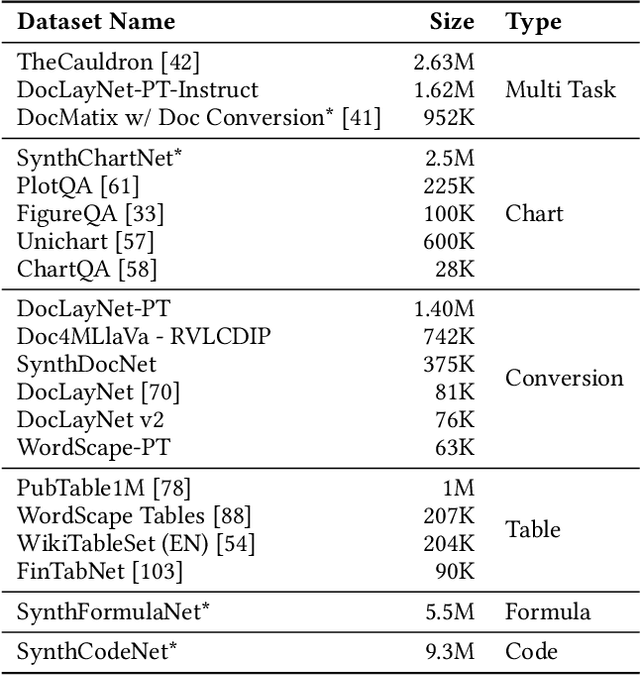
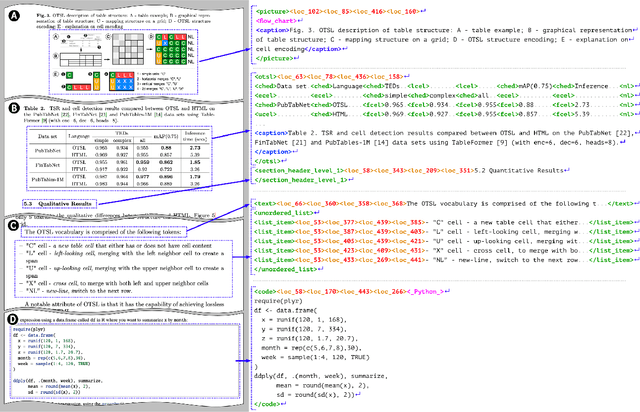
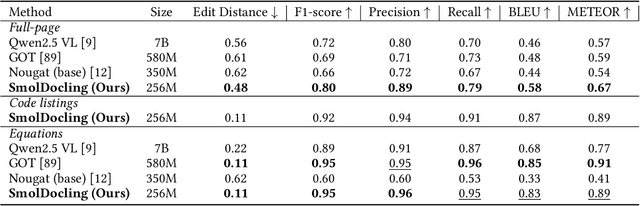
We introduce SmolDocling, an ultra-compact vision-language model targeting end-to-end document conversion. Our model comprehensively processes entire pages by generating DocTags, a new universal markup format that captures all page elements in their full context with location. Unlike existing approaches that rely on large foundational models, or ensemble solutions that rely on handcrafted pipelines of multiple specialized models, SmolDocling offers an end-to-end conversion for accurately capturing content, structure and spatial location of document elements in a 256M parameters vision-language model. SmolDocling exhibits robust performance in correctly reproducing document features such as code listings, tables, equations, charts, lists, and more across a diverse range of document types including business documents, academic papers, technical reports, patents, and forms -- significantly extending beyond the commonly observed focus on scientific papers. Additionally, we contribute novel publicly sourced datasets for charts, tables, equations, and code recognition. Experimental results demonstrate that SmolDocling competes with other Vision Language Models that are up to 27 times larger in size, while reducing computational requirements substantially. The model is currently available, datasets will be publicly available soon.
Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion
Jan 27, 2025



We introduce Docling, an easy-to-use, self-contained, MIT-licensed, open-source toolkit for document conversion, that can parse several types of popular document formats into a unified, richly structured representation. It is powered by state-of-the-art specialized AI models for layout analysis (DocLayNet) and table structure recognition (TableFormer), and runs efficiently on commodity hardware in a small resource budget. Docling is released as a Python package and can be used as a Python API or as a CLI tool. Docling's modular architecture and efficient document representation make it easy to implement extensions, new features, models, and customizations. Docling has been already integrated in other popular open-source frameworks (e.g., LangChain, LlamaIndex, spaCy), making it a natural fit for the processing of documents and the development of high-end applications. The open-source community has fully engaged in using, promoting, and developing for Docling, which gathered 10k stars on GitHub in less than a month and was reported as the No. 1 trending repository in GitHub worldwide in November 2024.
Statements: Universal Information Extraction from Tables with Large Language Models for ESG KPIs
Jun 27, 2024Environment, Social, and Governance (ESG) KPIs assess an organization's performance on issues such as climate change, greenhouse gas emissions, water consumption, waste management, human rights, diversity, and policies. ESG reports convey this valuable quantitative information through tables. Unfortunately, extracting this information is difficult due to high variability in the table structure as well as content. We propose Statements, a novel domain agnostic data structure for extracting quantitative facts and related information. We propose translating tables to statements as a new supervised deep-learning universal information extraction task. We introduce SemTabNet - a dataset of over 100K annotated tables. Investigating a family of T5-based Statement Extraction Models, our best model generates statements which are 82% similar to the ground-truth (compared to baseline of 21%). We demonstrate the advantages of statements by applying our model to over 2700 tables from ESG reports. The homogeneous nature of statements permits exploratory data analysis on expansive information found in large collections of ESG reports.
Uncertainty Quantification for Rule-Based Models
Nov 03, 2022

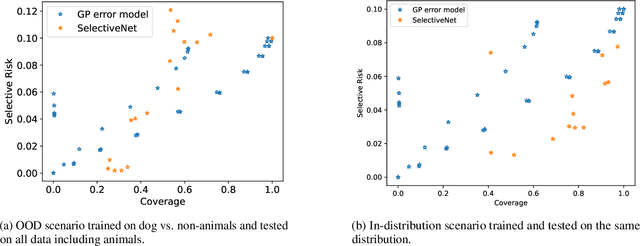
Rule-based classification models described in the language of logic directly predict boolean values, rather than modeling a probability and translating it into a prediction as done in statistical models. The vast majority of existing uncertainty quantification approaches rely on models providing continuous output not available to rule-based models. In this work, we propose an uncertainty quantification framework in the form of a meta-model that takes any binary classifier with binary output as a black box and estimates the prediction accuracy of that base model at a given input along with a level of confidence on that estimation. The confidence is based on how well that input region is explored and is designed to work in any OOD scenario. We demonstrate the usefulness of this uncertainty model by building an abstaining classifier powered by it and observing its performance in various scenarios.
Differentiable Rule Induction with Learned Relational Features
Jan 17, 2022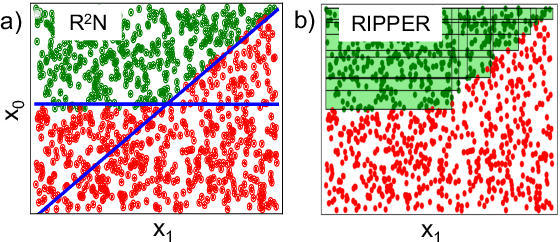
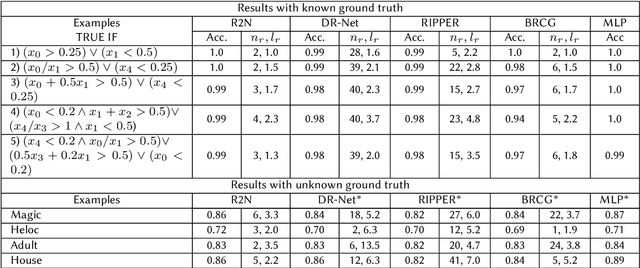
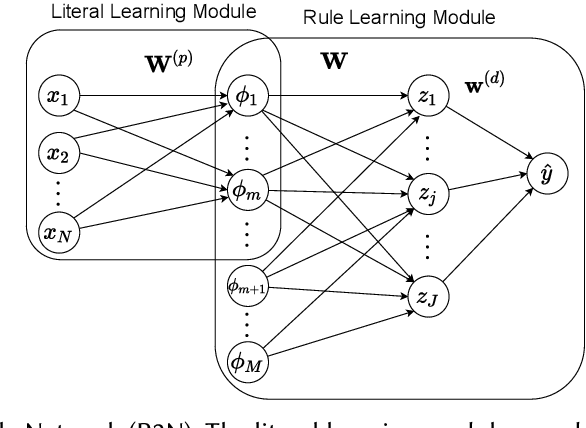

Rule-based decision models are attractive due to their interpretability. However, existing rule induction methods often results in long and consequently less interpretable set of rules. This problem can, in many cases, be attributed to the rule learner's lack of appropriately expressive vocabulary, i.e., relevant predicates. Most existing rule induction algorithms presume the availability of predicates used to represent the rules, naturally decoupling the predicate definition and the rule learning phases. In contrast, we propose the Relational Rule Network (RRN), a neural architecture that learns relational predicates that represent a linear relationship among attributes along with the rules that use them. This approach opens the door to increasing the expressiveness of induced decision models by coupling predicate learning directly with rule learning in an end to end differentiable fashion. On benchmark tasks, we show that these relational predicates are simple enough to retain interpretability, yet improve prediction accuracy and provide sets of rules that are more concise compared to state of the art rule induction algorithms.