 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkushGrapher-2: End-to-end Multimodal Recognition of Chemical Structures
Mar 30, 2026Automatically extracting chemical structures from documents is essential for the large-scale analysis of the literature in chemistry. Automatic pipelines have been developed to recognize molecules represented either in figures or in text independently. However, methods for recognizing chemical structures from multimodal descriptions (Markush structures) lag behind in precision and cannot be used for automatic large-scale processing. In this work, we present MarkushGrapher-2, an end-to-end approach for the multimodal recognition of chemical structures in documents. First, our method employs a dedicated OCR model to extract text from chemical images. Second, the text, image, and layout information are jointly encoded through a Vision-Text-Layout encoder and an Optical Chemical Structure Recognition vision encoder. Finally, the resulting encodings are effectively fused through a two-stage training strategy and used to auto-regressively generate a representation of the Markush structure. To address the lack of training data, we introduce an automatic pipeline for constructing a large-scale dataset of real-world Markush structures. In addition, we present IP5-M, a large manually-annotated benchmark of real-world Markush structures, designed to advance research on this challenging task. Extensive experiments show that our approach substantially outperforms state-of-the-art models in multimodal Markush structure recognition, while maintaining strong performance in molecule structure recognition. Code, models, and datasets are released publicly.
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Moving Beyond Sparse Grounding with Complete Screen Parsing Supervision
Feb 15, 2026Modern computer-use agents (CUA) must perceive a screen as a structured state, what elements are visible, where they are, and what text they contain, before they can reliably ground instructions and act. Yet, most available grounding datasets provide sparse supervision, with insufficient and low-diversity labels that annotate only a small subset of task-relevant elements per screen, which limits both coverage and generalization; moreover, practical deployment requires efficiency to enable low-latency, on-device use. We introduce ScreenParse, a large-scale dataset for complete screen parsing, with dense annotations of all visible UI elements (boxes, 55-class types, and text) across 771K web screenshots (21M elements). ScreenParse is generated by Webshot, an automated, scalable pipeline that renders diverse urls, extracts annotations and applies VLM-based relabeling and quality filtering. Using ScreenParse, we train ScreenVLM, a compact, 316M-parameter vision language model (VLM) that decodes a compact ScreenTag markup representation with a structure-aware loss that upweights structure-critical tokens. ScreenVLM substantially outperforms much larger foundation VLMs on dense parsing (e.g., 0.592 vs. 0.294 PageIoU on ScreenParse) and shows strong transfer to public benchmarks. Moreover, finetuning foundation VLMs on ScreenParse consistently improves their grounding performance, suggesting that dense screen supervision provides transferable structural priors for UI understanding. Project page: https://saidgurbuz.github.io/screenparse/.
MarkushGrapher: Joint Visual and Textual Recognition of Markush Structures
Mar 20, 2025The automated analysis of chemical literature holds promise to accelerate discovery in fields such as material science and drug development. In particular, search capabilities for chemical structures and Markush structures (chemical structure templates) within patent documents are valuable, e.g., for prior-art search. Advancements have been made in the automatic extraction of chemical structures from text and images, yet the Markush structures remain largely unexplored due to their complex multi-modal nature. In this work, we present MarkushGrapher, a multi-modal approach for recognizing Markush structures in documents. Our method jointly encodes text, image, and layout information through a Vision-Text-Layout encoder and an Optical Chemical Structure Recognition vision encoder. These representations are merged and used to auto-regressively generate a sequential graph representation of the Markush structure along with a table defining its variable groups. To overcome the lack of real-world training data, we propose a synthetic data generation pipeline that produces a wide range of realistic Markush structures. Additionally, we present M2S, the first annotated benchmark of real-world Markush structures, to advance research on this challenging task. Extensive experiments demonstrate that our approach outperforms state-of-the-art chemistry-specific and general-purpose vision-language models in most evaluation settings. Code, models, and datasets will be available.
Know Your RAG: Dataset Taxonomy and Generation Strategies for Evaluating RAG Systems
Nov 29, 2024
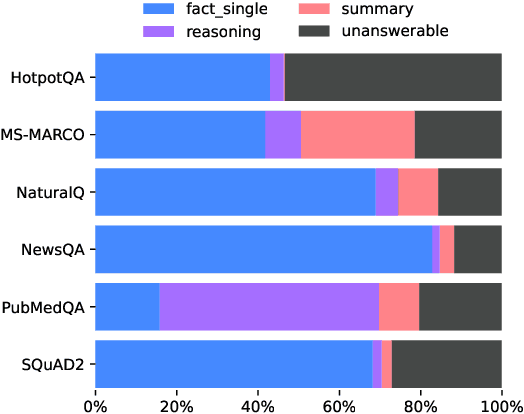
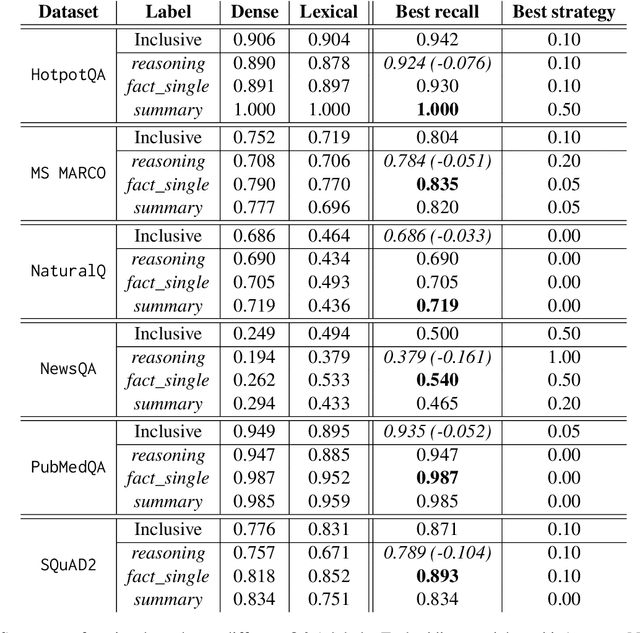
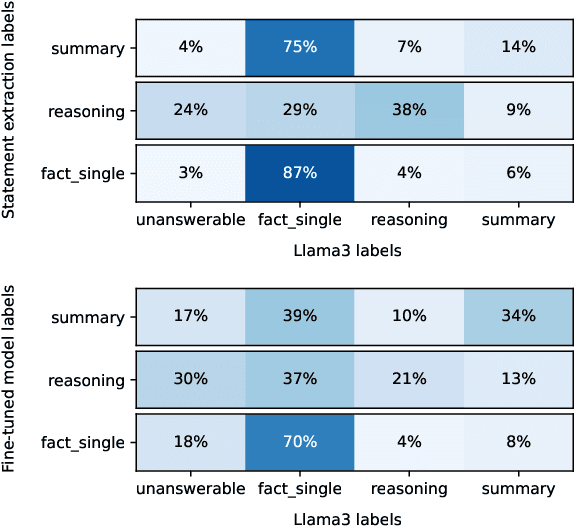
Retrieval Augmented Generation (RAG) systems are a widespread application of Large Language Models (LLMs) in the industry. While many tools exist empowering developers to build their own systems, measuring their performance locally, with datasets reflective of the system's use cases, is a technological challenge. Solutions to this problem range from non-specific and cheap (most public datasets) to specific and costly (generating data from local documents). In this paper, we show that using public question and answer (Q&A) datasets to assess retrieval performance can lead to non-optimal systems design, and that common tools for RAG dataset generation can lead to unbalanced data. We propose solutions to these issues based on the characterization of RAG datasets through labels and through label-targeted data generation. Finally, we show that fine-tuned small LLMs can efficiently generate Q&A datasets. We believe that these observations are invaluable to the know-your-data step of RAG systems development.
Statements: Universal Information Extraction from Tables with Large Language Models for ESG KPIs
Jun 27, 2024Environment, Social, and Governance (ESG) KPIs assess an organization's performance on issues such as climate change, greenhouse gas emissions, water consumption, waste management, human rights, diversity, and policies. ESG reports convey this valuable quantitative information through tables. Unfortunately, extracting this information is difficult due to high variability in the table structure as well as content. We propose Statements, a novel domain agnostic data structure for extracting quantitative facts and related information. We propose translating tables to statements as a new supervised deep-learning universal information extraction task. We introduce SemTabNet - a dataset of over 100K annotated tables. Investigating a family of T5-based Statement Extraction Models, our best model generates statements which are 82% similar to the ground-truth (compared to baseline of 21%). We demonstrate the advantages of statements by applying our model to over 2700 tables from ESG reports. The homogeneous nature of statements permits exploratory data analysis on expansive information found in large collections of ESG reports.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
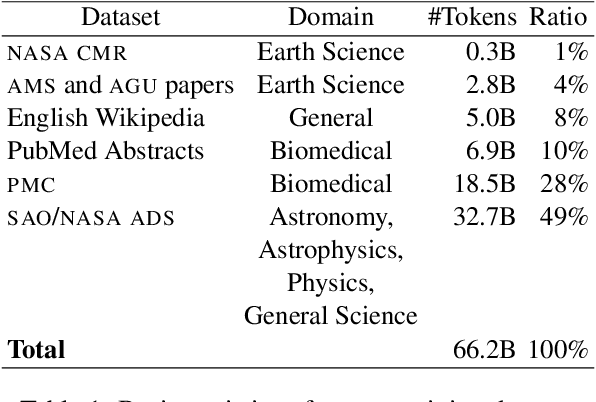
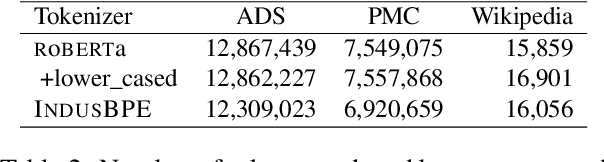

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024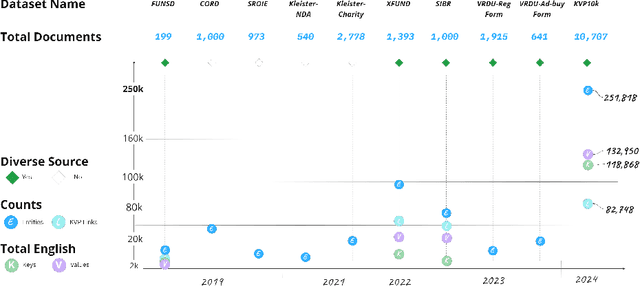
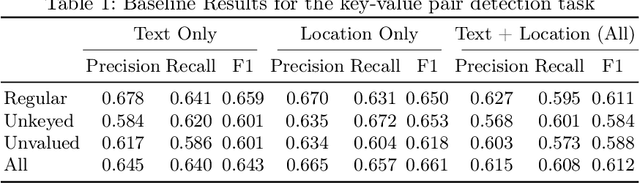
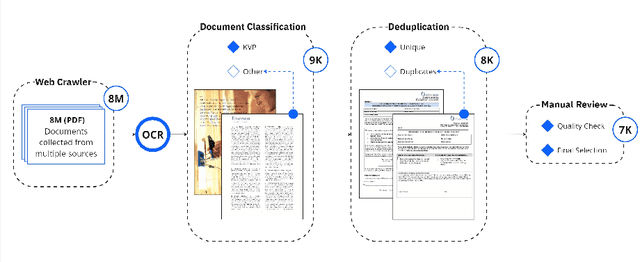

In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023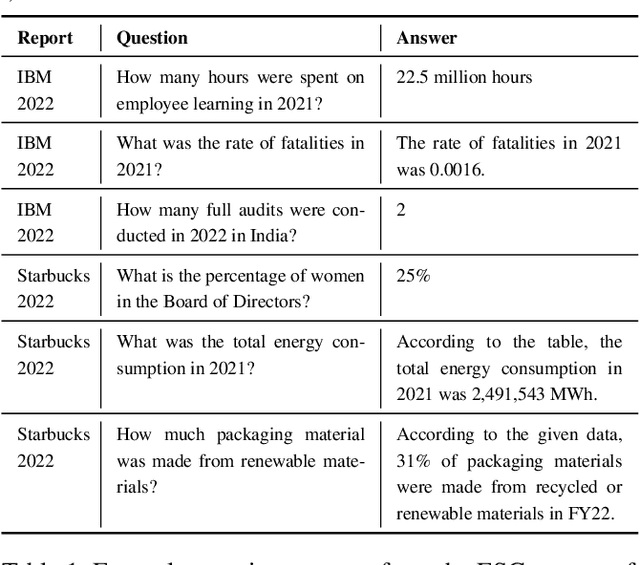
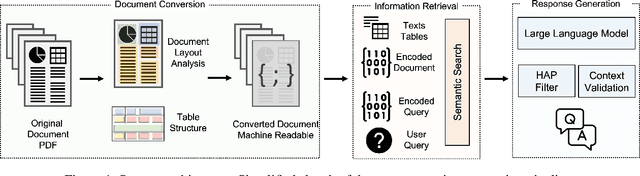
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.
MolGrapher: Graph-based Visual Recognition of Chemical Structures
Aug 23, 2023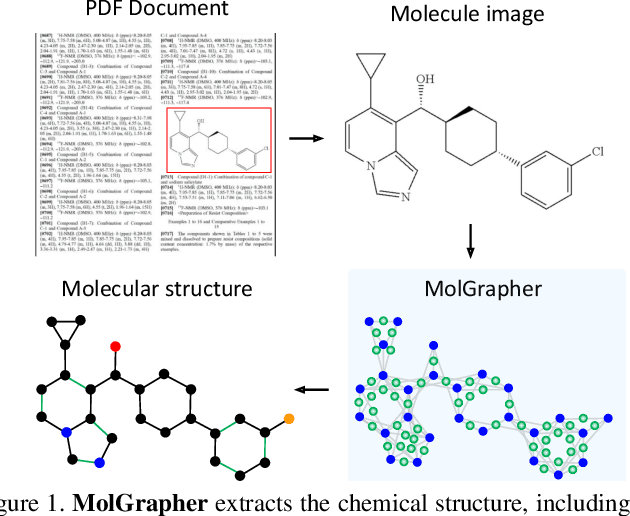
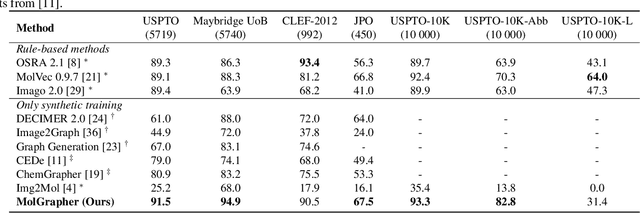
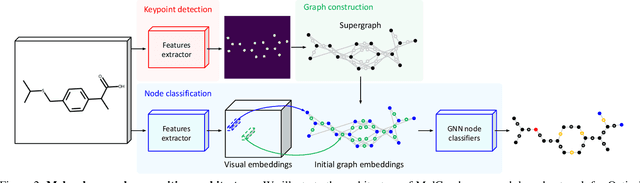
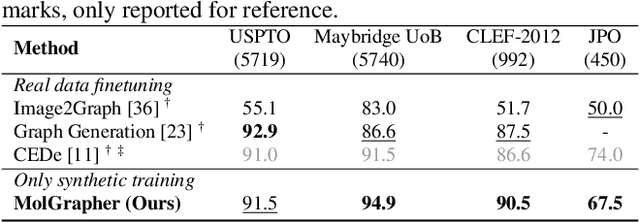
The automatic analysis of chemical literature has immense potential to accelerate the discovery of new materials and drugs. Much of the critical information in patent documents and scientific articles is contained in figures, depicting the molecule structures. However, automatically parsing the exact chemical structure is a formidable challenge, due to the amount of detailed information, the diversity of drawing styles, and the need for training data. In this work, we introduce MolGrapher to recognize chemical structures visually. First, a deep keypoint detector detects the atoms. Second, we treat all candidate atoms and bonds as nodes and put them in a graph. This construct allows a natural graph representation of the molecule. Last, we classify atom and bond nodes in the graph with a Graph Neural Network. To address the lack of real training data, we propose a synthetic data generation pipeline producing diverse and realistic results. In addition, we introduce a large-scale benchmark of annotated real molecule images, USPTO-30K, to spur research on this critical topic. Extensive experiments on five datasets show that our approach significantly outperforms classical and learning-based methods in most settings. Code, models, and datasets are available.