 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting In-Context-Learning in LLMs via Automatic Data Labeling and Refinement
Oct 14, 2024It has been shown that Large Language Models' (LLMs) performance can be improved for many tasks using Chain of Thought (CoT) or In-Context Learning (ICL), which involve demonstrating the steps needed to solve a task using a few examples. However, while datasets with input-output pairs are relatively easy to produce, providing demonstrations which include intermediate steps requires cumbersome manual work. These steps may be executable programs, as in agentic flows, or step-by-step reasoning as in CoT. In this work, we propose Automatic Data Labeling and Refinement (ADLR), a method to automatically generate and filter demonstrations which include the above intermediate steps, starting from a small seed of manually crafted examples. We demonstrate the advantage of ADLR in code-based table QA and mathematical reasoning, achieving up to a 5.5% gain. The code implementing our method is provided in the Supplementary material and will be made available.
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024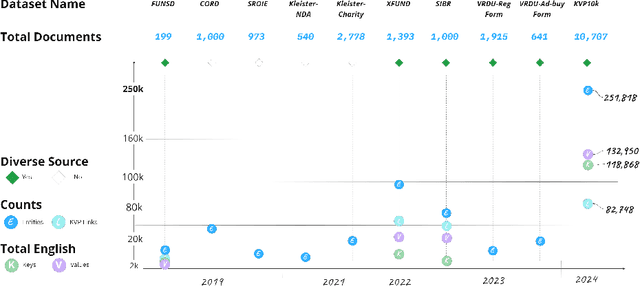
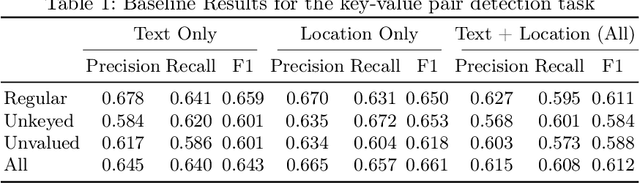
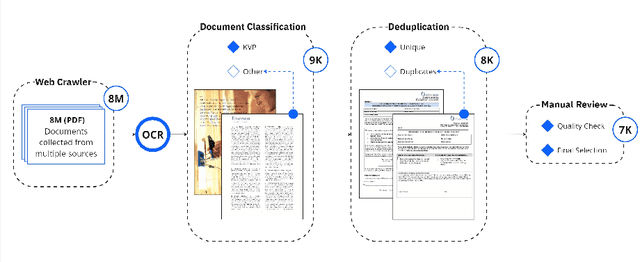

In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.