 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024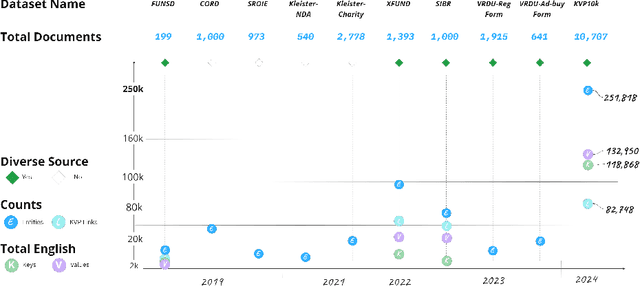
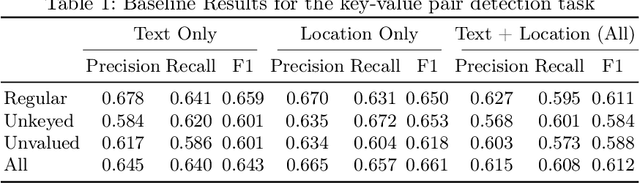
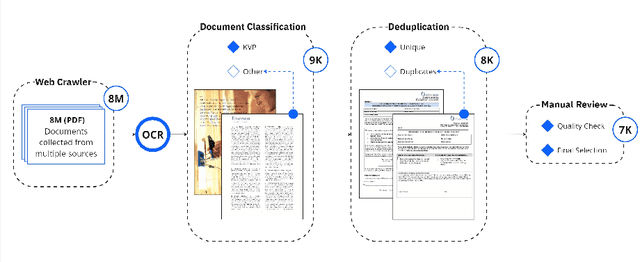

In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
Learnable Optimal Sequential Grouping for Video Scene Detection
May 17, 2022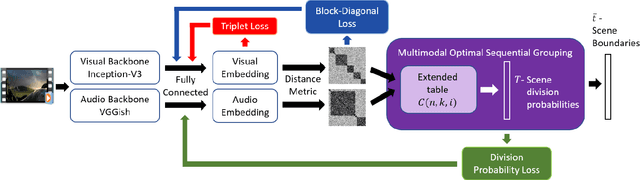
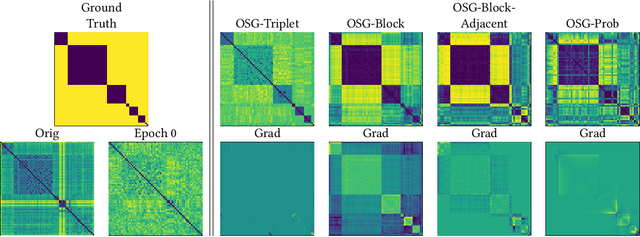
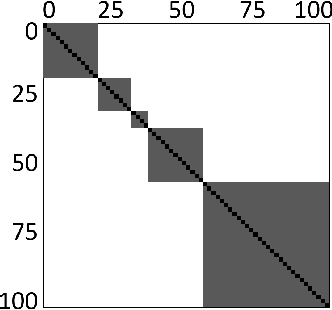
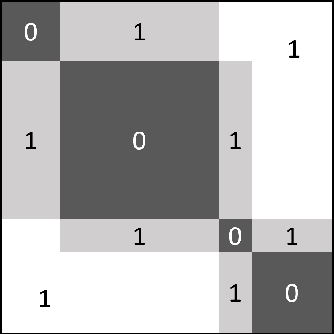
Video scene detection is the task of dividing videos into temporal semantic chapters. This is an important preliminary step before attempting to analyze heterogeneous video content. Recently, Optimal Sequential Grouping (OSG) was proposed as a powerful unsupervised solution to solve a formulation of the video scene detection problem. In this work, we extend the capabilities of OSG to the learning regime. By giving the capability to both learn from examples and leverage a robust optimization formulation, we can boost performance and enhance the versatility of the technology. We present a comprehensive analysis of incorporating OSG into deep learning neural networks under various configurations. These configurations include learning an embedding in a straight-forward manner, a tailored loss designed to guide the solution of OSG, and an integrated model where the learning is performed through the OSG pipeline. With thorough evaluation and analysis, we assess the benefits and behavior of the various configurations, and show that our learnable OSG approach exhibits desirable behavior and enhanced performance compared to the state of the art.