 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCol-Bandit: Zero-Shot Query-Time Pruning for Late-Interaction Retrieval
Feb 02, 2026Multi-vector late-interaction retrievers such as ColBERT achieve state-of-the-art retrieval quality, but their query-time cost is dominated by exhaustively computing token-level MaxSim interactions for every candidate document. While approximating late interaction with single-vector representations reduces cost, it often incurs substantial accuracy loss. We introduce Col-Bandit, a query-time pruning algorithm that reduces this computational burden by casting reranking as a finite-population Top-$K$ identification problem. Col-Bandit maintains uncertainty-aware bounds over partially observed document scores and adaptively reveals only the (document, query token) MaxSim entries needed to determine the top results under statistical decision bounds with a tunable relaxation. Unlike coarse-grained approaches that prune entire documents or tokens offline, Col-Bandit sparsifies the interaction matrix on the fly. It operates as a zero-shot, drop-in layer over standard multi-vector systems, requiring no index modifications, offline preprocessing, or model retraining. Experiments on textual (BEIR) and multimodal (REAL-MM-RAG) benchmarks show that Col-Bandit preserves ranking fidelity while reducing MaxSim FLOPs by up to 5$\times$, indicating that dense late-interaction scoring contains substantial redundancy that can be identified and pruned efficiently at query time.
REAL-MM-RAG: A Real-World Multi-Modal Retrieval Benchmark
Feb 17, 2025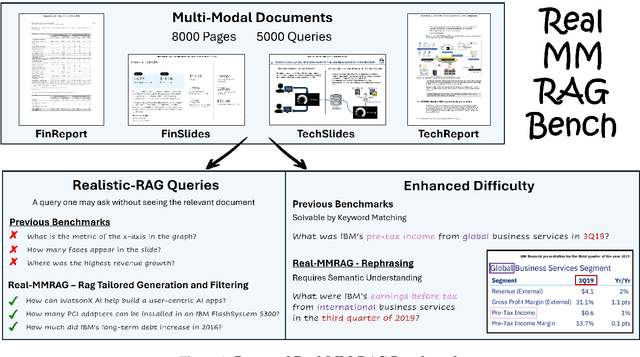
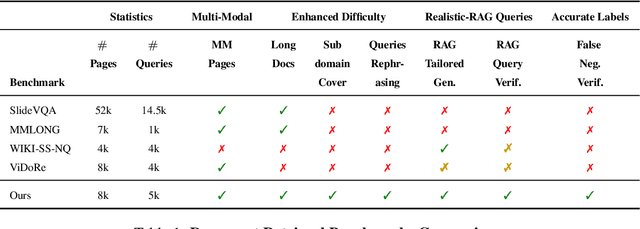

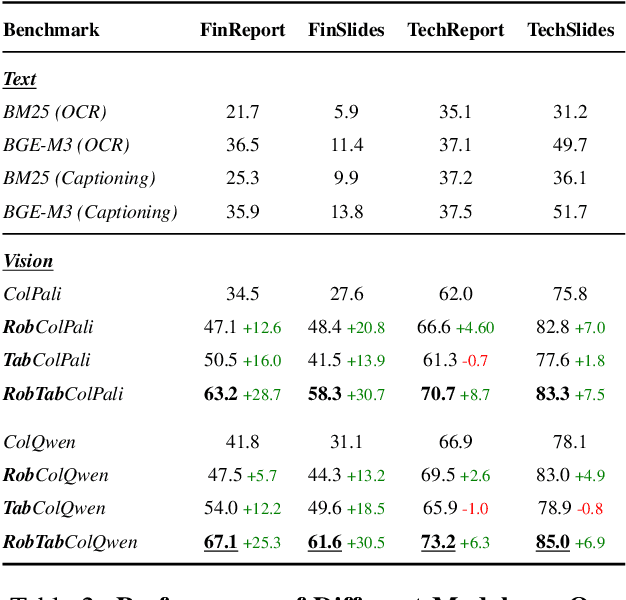
Accurate multi-modal document retrieval is crucial for Retrieval-Augmented Generation (RAG), yet existing benchmarks do not fully capture real-world challenges with their current design. We introduce REAL-MM-RAG, an automatically generated benchmark designed to address four key properties essential for real-world retrieval: (i) multi-modal documents, (ii) enhanced difficulty, (iii) Realistic-RAG queries and (iv) accurate labeling. Additionally, we propose a multi-difficulty-level scheme based on query rephrasing to evaluate models' semantic understanding beyond keyword matching. Our benchmark reveals significant model weaknesses, particularly in handling table-heavy documents and robustness to query rephrasing. To mitigate these shortcomings, we curate a rephrased training set and introduce a new finance-focused, table-heavy dataset. Fine-tuning on these datasets enables models to achieve state-of-the-art retrieval performance on REAL-MM-RAG benchmark. Our work offers a better way to evaluate and improve retrieval in multi-modal RAG systems while also providing training data and models that address current limitations.
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024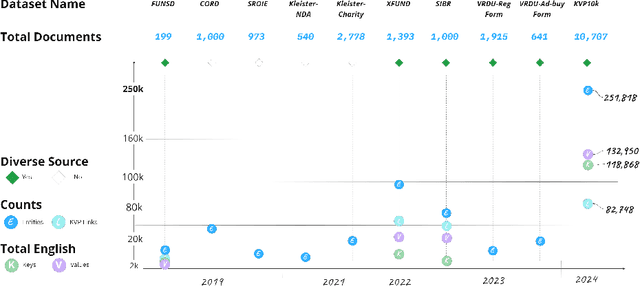
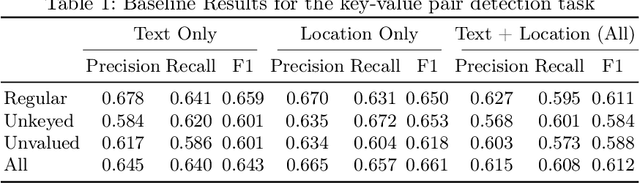
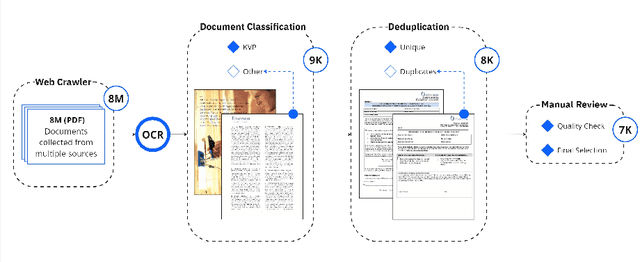

In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
BusiNet -- a Light and Fast Text Detection Network for Business Documents
Jul 04, 2022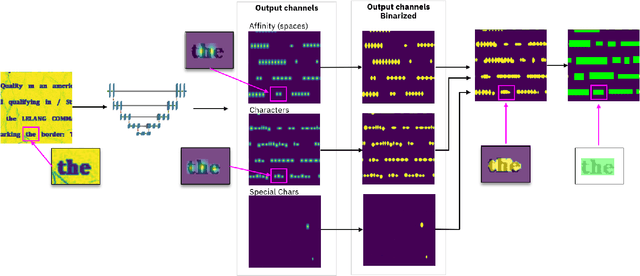
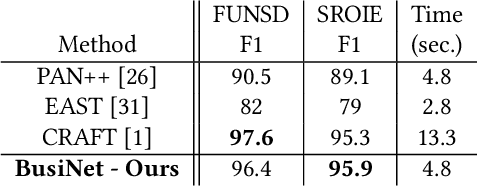

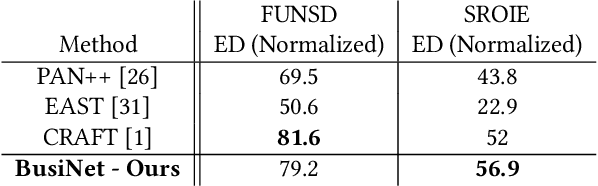
For digitizing or indexing physical documents, Optical Character Recognition (OCR), the process of extracting textual information from scanned documents, is a vital technology. When a document is visually damaged or contains non-textual elements, existing technologies can yield poor results, as erroneous detection results can greatly affect the quality of OCR. In this paper we present a detection network dubbed BusiNet aimed at OCR of business documents. Business documents often include sensitive information and as such they cannot be uploaded to a cloud service for OCR. BusiNet was designed to be fast and light so it could run locally preventing privacy issues. Furthermore, BusiNet is built to handle scanned document corruption and noise using a specialized synthetic dataset. The model is made robust to unseen noise by employing adversarial training strategies. We perform an evaluation on publicly available datasets demonstrating the usefulness and broad applicability of our model.
Detection Masking for Improved OCR on Noisy Documents
May 17, 2022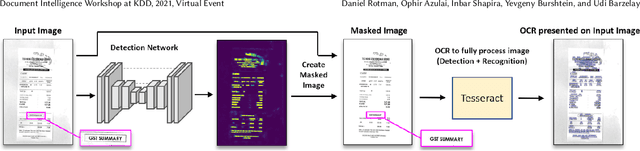
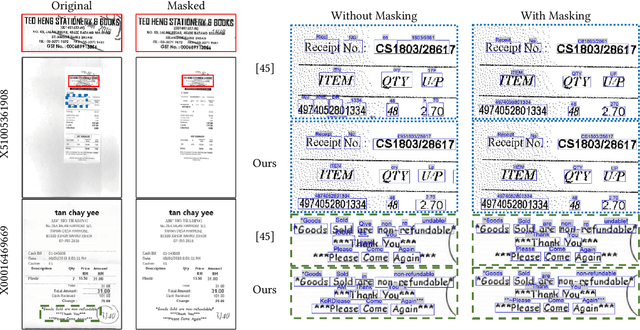

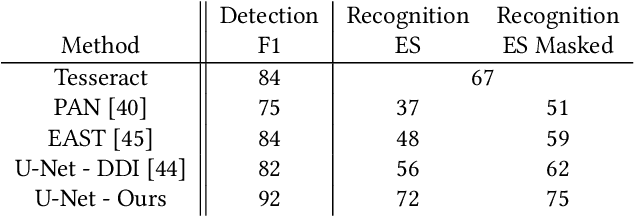
Optical Character Recognition (OCR), the task of extracting textual information from scanned documents is a vital and broadly used technology for digitizing and indexing physical documents. Existing technologies perform well for clean documents, but when the document is visually degraded, or when there are non-textual elements, OCR quality can be greatly impacted, specifically due to erroneous detections. In this paper we present an improved detection network with a masking system to improve the quality of OCR performed on documents. By filtering non-textual elements from the image we can utilize document-level OCR to incorporate contextual information to improve OCR results. We perform a unified evaluation on a publicly available dataset demonstrating the usefulness and broad applicability of our method. Additionally, we present and make publicly available our synthetic dataset with a unique hard-negative component specifically tuned to improve detection results, and evaluate the benefits that can be gained from its usage
Learnable Optimal Sequential Grouping for Video Scene Detection
May 17, 2022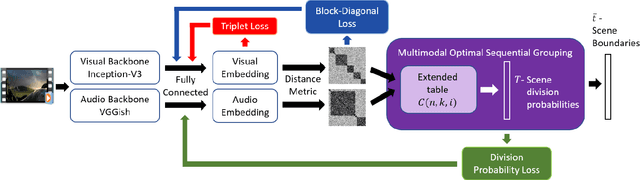
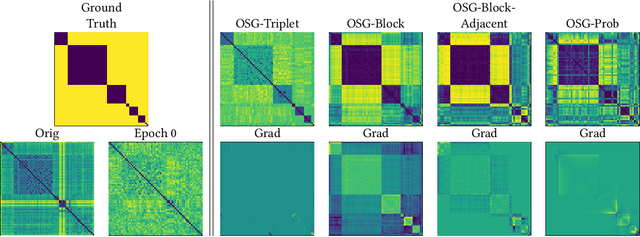
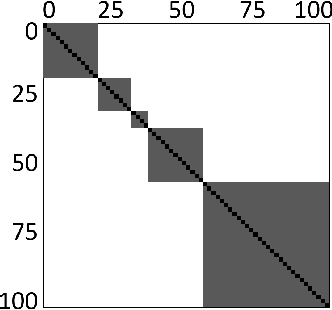
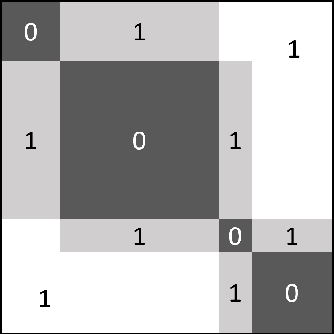
Video scene detection is the task of dividing videos into temporal semantic chapters. This is an important preliminary step before attempting to analyze heterogeneous video content. Recently, Optimal Sequential Grouping (OSG) was proposed as a powerful unsupervised solution to solve a formulation of the video scene detection problem. In this work, we extend the capabilities of OSG to the learning regime. By giving the capability to both learn from examples and leverage a robust optimization formulation, we can boost performance and enhance the versatility of the technology. We present a comprehensive analysis of incorporating OSG into deep learning neural networks under various configurations. These configurations include learning an embedding in a straight-forward manner, a tailored loss designed to guide the solution of OSG, and an integrated model where the learning is performed through the OSG pipeline. With thorough evaluation and analysis, we assess the benefits and behavior of the various configurations, and show that our learnable OSG approach exhibits desirable behavior and enhanced performance compared to the state of the art.
TAEN: Temporal Aware Embedding Network for Few-Shot Action Recognition
Apr 21, 2020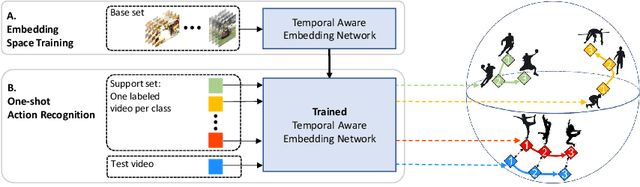
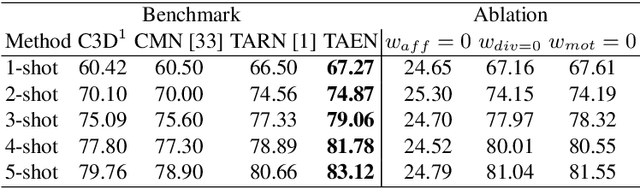
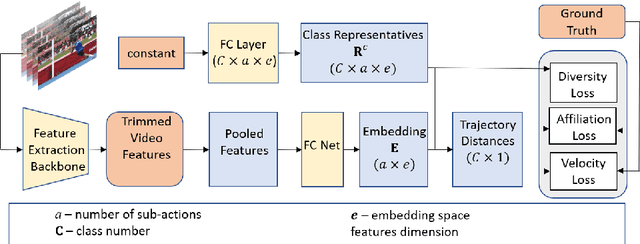
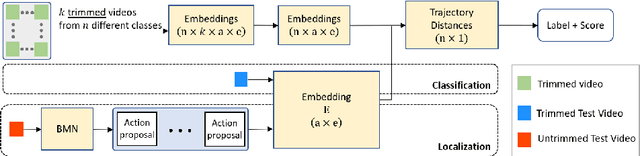
Classification of a new class entities requires collecting and annotating hundreds or thousands of samples that is often prohibitively time consuming and costly. Few-shot learning (FSL) suggests learning to classify new classes using just a few examples. Only a small number of studies address the challenge of using just a few labeled samples to learn a new spatio-temporal pattern such as videos. In this paper, we present a Temporal Aware Embedding Network (TAEN) for few-shot action recognition, that learns to represent actions, in a metric space as a trajectory, conveying both short term semantics and longer term connectivity between sub-actions. We demonstrate the effectiveness of TAEN on two few shot tasks, video classification and temporal action detection. We achieve state-of-the-art results on the Kinetics few-shot benchmark and on the ActivityNet 1.2 few-shot temporal action detection task. Code will be released upon acceptance of the paper.