 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIMP: Contrastive Language-Image Mamba Pretraining
Jan 11, 2026Contrastive Language-Image Pre-training (CLIP) relies on Vision Transformers whose attention mechanism is susceptible to spurious correlations, and scales quadratically with resolution. To address these limitations, We present CLIMP, the first fully Mamba-based contrastive vision-language model that replaces both the vision and text encoders with Mamba. The new architecture encodes sequential structure in both vision and language, with VMamba capturing visual spatial inductive biases, reducing reliance on spurious correlations and producing an embedding space favorable for cross-modal retrieval and out-of-distribution robustness-surpassing OpenAI's CLIP-ViT-B by 7.5% on ImageNet-O. CLIMP naturally supports variable input resolutions without positional encoding interpolation or specialized training, achieving up to 6.6% higher retrieval accuracy at 16x training resolution while using 5x less memory and 1.8x fewer FLOPs. The autoregressive text encoder further overcomes CLIP's fixed context limitation, enabling dense captioning retrieval. Our findings suggest that Mamba exhibits advantageous properties for vision-language learning, making it a compelling alternative to Transformer-based CLIP.
DocReRank: Single-Page Hard Negative Query Generation for Training Multi-Modal RAG Rerankers
May 28, 2025



Rerankers play a critical role in multimodal Retrieval-Augmented Generation (RAG) by refining ranking of an initial set of retrieved documents. Rerankers are typically trained using hard negative mining, whose goal is to select pages for each query which rank high, but are actually irrelevant. However, this selection process is typically passive and restricted to what the retriever can find in the available corpus, leading to several inherent limitations. These include: limited diversity, negative examples which are often not hard enough, low controllability, and frequent false negatives which harm training. Our paper proposes an alternative approach: Single-Page Hard Negative Query Generation, which goes the other way around. Instead of retrieving negative pages per query, we generate hard negative queries per page. Using an automated LLM-VLM pipeline, and given a page and its positive query, we create hard negatives by rephrasing the query to be as similar as possible in form and context, yet not answerable from the page. This paradigm enables fine-grained control over the generated queries, resulting in diverse, hard, and targeted negatives. It also supports efficient false negative verification. Our experiments show that rerankers trained with data generated using our approach outperform existing models and significantly improve retrieval performance.
REAL-MM-RAG: A Real-World Multi-Modal Retrieval Benchmark
Feb 17, 2025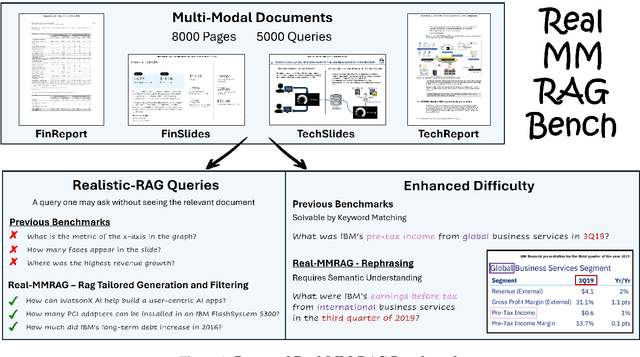
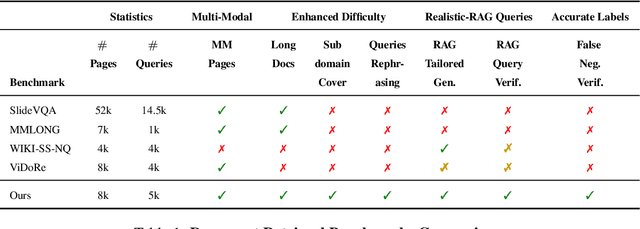

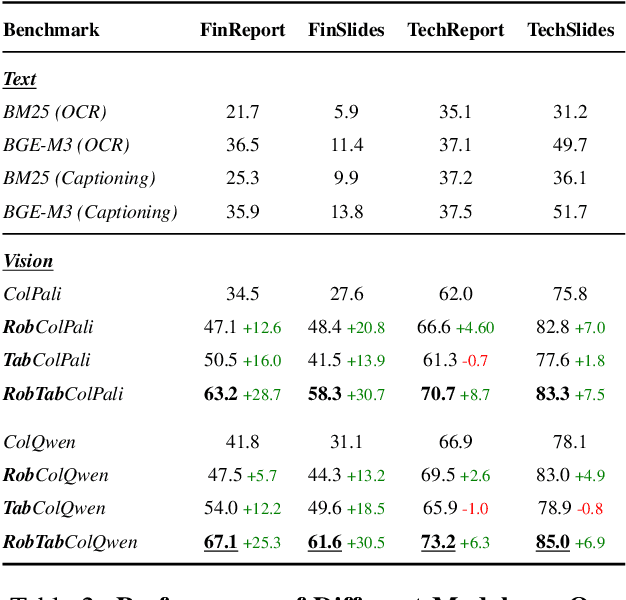
Accurate multi-modal document retrieval is crucial for Retrieval-Augmented Generation (RAG), yet existing benchmarks do not fully capture real-world challenges with their current design. We introduce REAL-MM-RAG, an automatically generated benchmark designed to address four key properties essential for real-world retrieval: (i) multi-modal documents, (ii) enhanced difficulty, (iii) Realistic-RAG queries and (iv) accurate labeling. Additionally, we propose a multi-difficulty-level scheme based on query rephrasing to evaluate models' semantic understanding beyond keyword matching. Our benchmark reveals significant model weaknesses, particularly in handling table-heavy documents and robustness to query rephrasing. To mitigate these shortcomings, we curate a rephrased training set and introduce a new finance-focused, table-heavy dataset. Fine-tuning on these datasets enables models to achieve state-of-the-art retrieval performance on REAL-MM-RAG benchmark. Our work offers a better way to evaluate and improve retrieval in multi-modal RAG systems while also providing training data and models that address current limitations.
Teaching VLMs to Localize Specific Objects from In-context Examples
Nov 20, 2024



Vision-Language Models (VLMs) have shown remarkable capabilities across diverse visual tasks, including image recognition, video understanding, and Visual Question Answering (VQA) when explicitly trained for these tasks. Despite these advances, we find that current VLMs lack a fundamental cognitive ability: learning to localize objects in a scene by taking into account the context. In this work, we focus on the task of few-shot personalized localization, where a model is given a small set of annotated images (in-context examples) -- each with a category label and bounding box -- and is tasked with localizing the same object type in a query image. To provoke personalized localization abilities in models, we present a data-centric solution that fine-tunes them using carefully curated data from video object tracking datasets. By leveraging sequences of frames tracking the same object across multiple shots, we simulate instruction-tuning dialogues that promote context awareness. To reinforce this, we introduce a novel regularization technique that replaces object labels with pseudo-names, ensuring the model relies on visual context rather than prior knowledge. Our method significantly enhances few-shot localization performance without sacrificing generalization, as demonstrated on several benchmarks tailored to personalized localization. This work is the first to explore and benchmark personalized few-shot localization for VLMs, laying a foundation for future research in context-driven vision-language applications. The code for our project is available at https://github.com/SivanDoveh/IPLoc
Deep Phase Coded Image Prior
Apr 05, 2024



Phase-coded imaging is a computational imaging method designed to tackle tasks such as passive depth estimation and extended depth of field (EDOF) using depth cues inserted during image capture. Most of the current deep learning-based methods for depth estimation or all-in-focus imaging require a training dataset with high-quality depth maps and an optimal focus point at infinity for all-in-focus images. Such datasets are difficult to create, usually synthetic, and require external graphic programs. We propose a new method named "Deep Phase Coded Image Prior" (DPCIP) for jointly recovering the depth map and all-in-focus image from a coded-phase image using solely the captured image and the optical information of the imaging system. Our approach does not depend on any specific dataset and surpasses prior supervised techniques utilizing the same imaging system. This improvement is achieved through the utilization of a problem formulation based on implicit neural representation (INR) and deep image prior (DIP). Due to our zero-shot method, we overcome the barrier of acquiring accurate ground-truth data of depth maps and all-in-focus images for each new phase-coded system introduced. This allows focusing mainly on developing the imaging system, and not on ground-truth data collection.
NumeroLogic: Number Encoding for Enhanced LLMs' Numerical Reasoning
Mar 30, 2024



Language models struggle with handling numerical data and performing arithmetic operations. We hypothesize that this limitation can be partially attributed to non-intuitive textual numbers representation. When a digit is read or generated by a causal language model it does not know its place value (e.g. thousands vs. hundreds) until the entire number is processed. To address this issue, we propose a simple adjustment to how numbers are represented by including the count of digits before each number. For instance, instead of "42", we suggest using "{2:42}" as the new format. This approach, which we term NumeroLogic, offers an added advantage in number generation by serving as a Chain of Thought (CoT). By requiring the model to consider the number of digits first, it enhances the reasoning process before generating the actual number. We use arithmetic tasks to demonstrate the effectiveness of the NumeroLogic formatting. We further demonstrate NumeroLogic applicability to general natural language modeling, improving language understanding performance in the MMLU benchmark.
3D Masked Autoencoders with Application to Anomaly Detection in Non-Contrast Enhanced Breast MRI
Mar 10, 2023Self-supervised models allow (pre-)training on unlabeled data and therefore have the potential to overcome the need for large annotated cohorts. One leading self-supervised model is the masked autoencoder (MAE) which was developed on natural imaging data. The MAE is masking out a high fraction of visual transformer (ViT) input patches, to then recover the uncorrupted images as a pretraining task. In this work, we extend MAE to perform anomaly detection on breast magnetic resonance imaging (MRI). This new model, coined masked autoencoder for medical imaging (MAEMI) is trained on two non-contrast enhanced MRI sequences, aiming at lesion detection without the need for intravenous injection of contrast media and temporal image acquisition. During training, only non-cancerous images are presented to the model, with the purpose of localizing anomalous tumor regions during test time. We use a public dataset for model development. Performance of the architecture is evaluated in reference to subtraction images created from dynamic contrast enhanced (DCE)-MRI.
PIP: Positional-encoding Image Prior
Nov 25, 2022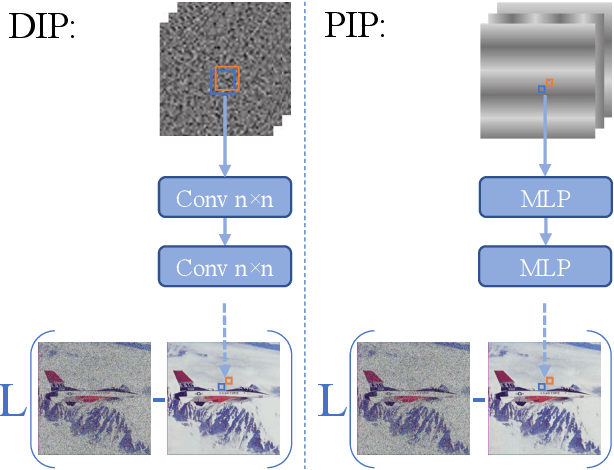

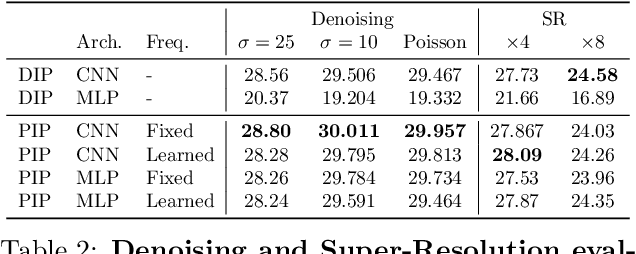

In Deep Image Prior (DIP), a Convolutional Neural Network (CNN) is fitted to map a latent space to a degraded (e.g. noisy) image but in the process learns to reconstruct the clean image. This phenomenon is attributed to CNN's internal image-prior. We revisit the DIP framework, examining it from the perspective of a neural implicit representation. Motivated by this perspective, we replace the random or learned latent with Fourier-Features (Positional Encoding). We show that thanks to the Fourier features properties, we can replace the convolution layers with simple pixel-level MLPs. We name this scheme ``Positional Encoding Image Prior" (PIP) and exhibit that it performs very similarly to DIP on various image-reconstruction tasks with much less parameters required. Additionally, we demonstrate that PIP can be easily extended to videos, where 3D-DIP struggles and suffers from instability. Code and additional examples for all tasks, including videos, are available on the project page https://nimrodshabtay.github.io/PIP/
MAEDAY: MAE for few and zero shot AnomalY-Detection
Nov 25, 2022



The goal of Anomaly-Detection (AD) is to identify outliers, or outlying regions, from some unknown distribution given only a set of positive (good) examples. Few-Shot AD (FSAD) aims to solve the same task with a minimal amount of normal examples. Recent embedding-based methods, that compare the embedding vectors of queries to a set of reference embeddings, have demonstrated impressive results for FSAD, where as little as one good example is provided. A different approach, image-reconstruction-based, has been historically used for AD. The idea is to train a model to recover normal images from corrupted observations, assuming that the model will fail to recover regions when encountered with an out-of-distribution image. However, image-reconstruction-based methods were not yet used in the low-shot regime as they need to be trained on a diverse set of normal images in order to properly perform. We suggest using Masked Auto-Encoder (MAE), a self-supervised transformer model trained for recovering missing image regions based on their surroundings for FSAD. We show that MAE performs well by pre-training on an arbitrary set of natural images (ImageNet) and only fine-tuning on a small set of normal images. We name this method MAEDAY. We further find that MAEDAY provides an orthogonal signal to the embedding-based methods and the ensemble of the two approaches achieves very strong SOTA results. We also present a novel task of Zero-Shot AD (ZSAD) where no normal samples are available at training time. We show that MAEDAY performs surprisingly well at this task. Finally, we provide a new dataset for detecting foreign objects on the ground and demonstrate superior results for this task as well. Code is available at https://github.com/EliSchwartz/MAEDAY .
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022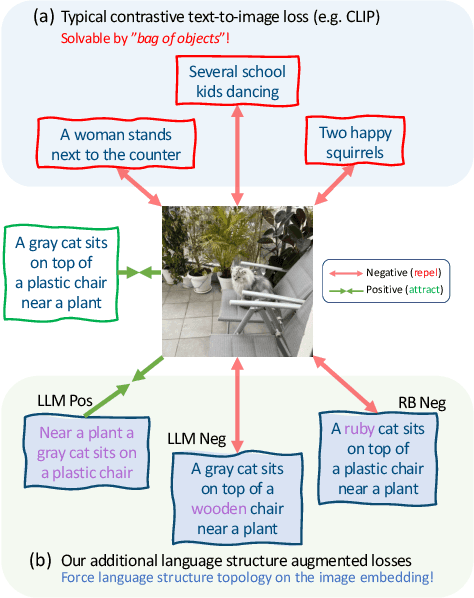
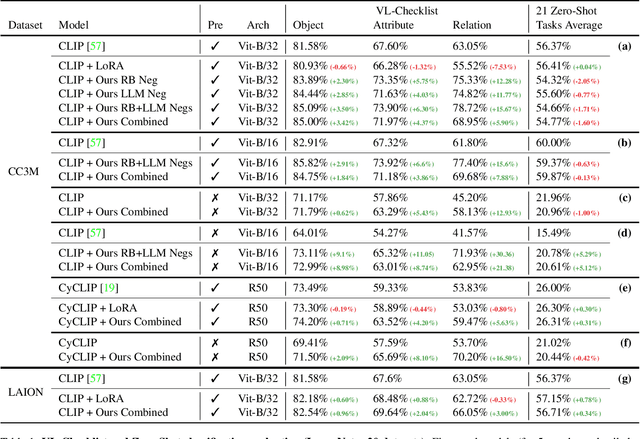
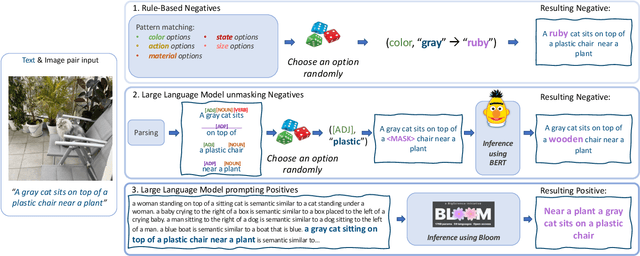

Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.