 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Reward Models for Few-Shot Model Alignment
Jul 02, 2025Aligning Large Language Models (LLMs) and Large Multimodal Models (LMMs) to human preferences is a central challenge in improving the quality of the models' generative outputs for real-world applications. A common approach is to use reward modeling to encode preferences, enabling alignment via post-training using reinforcement learning. However, traditional reward modeling is not easily adaptable to new preferences because it requires a separate reward model, commonly trained on large preference datasets. To address this, we introduce Activation Reward Models (Activation RMs) -- a novel few-shot reward modeling method that leverages activation steering to construct well-aligned reward signals using minimal supervision and no additional model finetuning. Activation RMs outperform existing few-shot reward modeling approaches such as LLM-as-a-judge with in-context learning, voting-based scoring, and token probability scoring on standard reward modeling benchmarks. Furthermore, we demonstrate the effectiveness of Activation RMs in mitigating reward hacking behaviors, highlighting their utility for safety-critical applications. Toward this end, we propose PreferenceHack, a novel few-shot setting benchmark, the first to test reward models on reward hacking in a paired preference format. Finally, we show that Activation RM achieves state-of-the-art performance on this benchmark, surpassing even GPT-4o.
Spoken question answering for visual queries
May 29, 2025Question answering (QA) systems are designed to answer natural language questions. Visual QA (VQA) and Spoken QA (SQA) systems extend the textual QA system to accept visual and spoken input respectively. This work aims to create a system that enables user interaction through both speech and images. That is achieved through the fusion of text, speech, and image modalities to tackle the task of spoken VQA (SVQA). The resulting multi-modal model has textual, visual, and spoken inputs and can answer spoken questions on images. Training and evaluating SVQA models requires a dataset for all three modalities, but no such dataset currently exists. We address this problem by synthesizing VQA datasets using two zero-shot TTS models. Our initial findings indicate that a model trained only with synthesized speech nearly reaches the performance of the upper-bounding model trained on textual QAs. In addition, we show that the choice of the TTS model has a minor impact on accuracy.
Sparse Attention Vectors: Generative Multimodal Model Features Are Discriminative Vision-Language Classifiers
Nov 28, 2024



Generative Large Multimodal Models (LMMs) like LLaVA and Qwen-VL excel at a wide variety of vision-language (VL) tasks such as image captioning or visual question answering. Despite strong performance, LMMs are not directly suited for foundational discriminative vision-language tasks (i.e., tasks requiring discrete label predictions) such as image classification and multiple-choice VQA. One key challenge in utilizing LMMs for discriminative tasks is the extraction of useful features from generative models. To overcome this issue, we propose an approach for finding features in the model's latent space to more effectively leverage LMMs for discriminative tasks. Toward this end, we present Sparse Attention Vectors (SAVs) -- a finetuning-free method that leverages sparse attention head activations (fewer than 1\% of the heads) in LMMs as strong features for VL tasks. With only few-shot examples, SAVs demonstrate state-of-the-art performance compared to a variety of few-shot and finetuned baselines on a collection of discriminative tasks. Our experiments also imply that SAVs can scale in performance with additional examples and generalize to similar tasks, establishing SAVs as both effective and robust multimodal feature representations.
Teaching VLMs to Localize Specific Objects from In-context Examples
Nov 20, 2024



Vision-Language Models (VLMs) have shown remarkable capabilities across diverse visual tasks, including image recognition, video understanding, and Visual Question Answering (VQA) when explicitly trained for these tasks. Despite these advances, we find that current VLMs lack a fundamental cognitive ability: learning to localize objects in a scene by taking into account the context. In this work, we focus on the task of few-shot personalized localization, where a model is given a small set of annotated images (in-context examples) -- each with a category label and bounding box -- and is tasked with localizing the same object type in a query image. To provoke personalized localization abilities in models, we present a data-centric solution that fine-tunes them using carefully curated data from video object tracking datasets. By leveraging sequences of frames tracking the same object across multiple shots, we simulate instruction-tuning dialogues that promote context awareness. To reinforce this, we introduce a novel regularization technique that replaces object labels with pseudo-names, ensuring the model relies on visual context rather than prior knowledge. Our method significantly enhances few-shot localization performance without sacrificing generalization, as demonstrated on several benchmarks tailored to personalized localization. This work is the first to explore and benchmark personalized few-shot localization for VLMs, laying a foundation for future research in context-driven vision-language applications. The code for our project is available at https://github.com/SivanDoveh/IPLoc
LiveXiv -- A Multi-Modal Live Benchmark Based on Arxiv Papers Content
Oct 15, 2024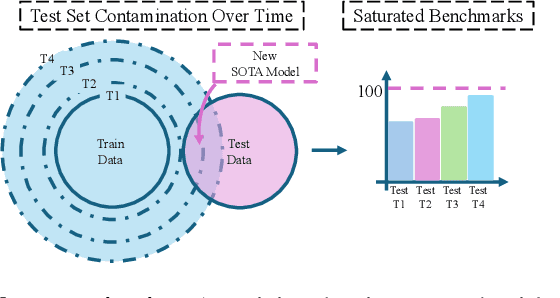



The large-scale training of multi-modal models on data scraped from the web has shown outstanding utility in infusing these models with the required world knowledge to perform effectively on multiple downstream tasks. However, one downside of scraping data from the web can be the potential sacrifice of the benchmarks on which the abilities of these models are often evaluated. To safeguard against test data contamination and to truly test the abilities of these foundation models we propose LiveXiv: A scalable evolving live benchmark based on scientific ArXiv papers. LiveXiv accesses domain-specific manuscripts at any given timestamp and proposes to automatically generate visual question-answer pairs (VQA). This is done without any human-in-the-loop, using the multi-modal content in the manuscripts, like graphs, charts, and tables. Moreover, we introduce an efficient evaluation approach that estimates the performance of all models on the evolving benchmark using evaluations of only a subset of models. This significantly reduces the overall evaluation cost. We benchmark multiple open and proprietary Large Multi-modal Models (LMMs) on the first version of our benchmark, showing its challenging nature and exposing the models true abilities, avoiding contamination. Lastly, in our commitment to high quality, we have collected and evaluated a manually verified subset. By comparing its overall results to our automatic annotations, we have found that the performance variance is indeed minimal (<2.5%). Our dataset is available online on HuggingFace, and our code will be available here.
Augmenting In-Context-Learning in LLMs via Automatic Data Labeling and Refinement
Oct 14, 2024It has been shown that Large Language Models' (LLMs) performance can be improved for many tasks using Chain of Thought (CoT) or In-Context Learning (ICL), which involve demonstrating the steps needed to solve a task using a few examples. However, while datasets with input-output pairs are relatively easy to produce, providing demonstrations which include intermediate steps requires cumbersome manual work. These steps may be executable programs, as in agentic flows, or step-by-step reasoning as in CoT. In this work, we propose Automatic Data Labeling and Refinement (ADLR), a method to automatically generate and filter demonstrations which include the above intermediate steps, starting from a small seed of manually crafted examples. We demonstrate the advantage of ADLR in code-based table QA and mathematical reasoning, achieving up to a 5.5% gain. The code implementing our method is provided in the Supplementary material and will be made available.
Multimodal Task Vectors Enable Many-Shot Multimodal In-Context Learning
Jun 21, 2024The recent success of interleaved Large Multimodal Models (LMMs) in few-shot learning suggests that in-context learning (ICL) with many examples can be promising for learning new tasks. However, this many-shot multimodal ICL setting has one crucial problem: it is fundamentally limited by the model's context length set at pretraining. The problem is especially prominent in the multimodal domain, which processes both text and images, requiring additional tokens. This motivates the need for a multimodal method to compress many shots into fewer tokens without finetuning. In this work, we enable LMMs to perform multimodal, many-shot in-context learning by leveraging Multimodal Task Vectors (MTV)--compact implicit representations of in-context examples compressed in the model's attention heads. Specifically, we first demonstrate the existence of such MTV in LMMs and then leverage these extracted MTV to enable many-shot in-context learning for various vision-and-language tasks. Our experiments suggest that MTV can scale in performance with the number of compressed shots and generalize to similar out-of-domain tasks without additional context length for inference.
ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs
Jun 12, 2024



Compositional Reasoning (CR) entails grasping the significance of attributes, relations, and word order. Recent Vision-Language Models (VLMs), comprising a visual encoder and a Large Language Model (LLM) decoder, have demonstrated remarkable proficiency in such reasoning tasks. This prompts a crucial question: have VLMs effectively tackled the CR challenge? We conjecture that existing CR benchmarks may not adequately push the boundaries of modern VLMs due to the reliance on an LLM-only negative text generation pipeline. Consequently, the negatives produced either appear as outliers from the natural language distribution learned by VLMs' LLM decoders or as improbable within the corresponding image context. To address these limitations, we introduce ConMe -- a compositional reasoning benchmark and a novel data generation pipeline leveraging VLMs to produce `hard CR Q&A'. Through a new concept of VLMs conversing with each other to collaboratively expose their weaknesses, our pipeline autonomously generates, evaluates, and selects challenging compositional reasoning questions, establishing a robust CR benchmark, also subsequently validated manually. Our benchmark provokes a noteworthy, up to 33%, decrease in CR performance compared to preceding benchmarks, reinstating the CR challenge even for state-of-the-art VLMs.
NumeroLogic: Number Encoding for Enhanced LLMs' Numerical Reasoning
Mar 30, 2024



Language models struggle with handling numerical data and performing arithmetic operations. We hypothesize that this limitation can be partially attributed to non-intuitive textual numbers representation. When a digit is read or generated by a causal language model it does not know its place value (e.g. thousands vs. hundreds) until the entire number is processed. To address this issue, we propose a simple adjustment to how numbers are represented by including the count of digits before each number. For instance, instead of "42", we suggest using "{2:42}" as the new format. This approach, which we term NumeroLogic, offers an added advantage in number generation by serving as a Chain of Thought (CoT). By requiring the model to consider the number of digits first, it enhances the reasoning process before generating the actual number. We use arithmetic tasks to demonstrate the effectiveness of the NumeroLogic formatting. We further demonstrate NumeroLogic applicability to general natural language modeling, improving language understanding performance in the MMLU benchmark.
Towards Multimodal In-Context Learning for Vision & Language Models
Mar 19, 2024



Inspired by the emergence of Large Language Models (LLMs) that can truly understand human language, significant progress has been made in aligning other, non-language, modalities to be `understandable' by an LLM, primarily via converting their samples into a sequence of embedded language-like tokens directly fed into the LLM (decoder) input stream. However, so far limited attention has been given to transferring (and evaluating) one of the core LLM capabilities to the emerging VLMs, namely the In-Context Learning (ICL) ability, or in other words to guide VLMs to desired target downstream tasks or output structure using in-context image+text demonstrations. In this work, we dive deeper into analyzing the capabilities of some of the state-of-the-art VLMs to follow ICL instructions, discovering them to be somewhat lacking. We discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot (ICL) demonstrations, likely due to their lack of `direct' ICL instruction tuning. To test this conjecture, we propose a simple, yet surprisingly effective, strategy of extending a common VLM alignment framework with ICL support, methodology, and curriculum. We explore, analyze, and provide insights into effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. We also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.