 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTA-Vid: Generalized Test-Time Adaptation for Video Reasoning
Apr 01, 2026Recent video reasoning models have shown strong results on temporal and multimodal understanding, yet they depend on large-scale supervised data and multi-stage training pipelines, making them costly to train and difficult to adapt to new domains. In this work, we leverage the paradigm of Test-Time Reinforcement Learning on video-language data to allow for adapting a pretrained model to incoming video samples at test-time without explicit labels. The proposed test-time adaptation for video approach (TTA-Vid) combines two components that work simultaneously: (1) a test-time adaptation that performs step-by-step reasoning at inference time on multiple frame subsets. We then use a batch-aware frequency-based reward computed across different frame subsets as pseudo ground truth to update the model. It shows that the resulting model trained on a single batch or even a single sample from a dataset, is able to generalize at test-time to the whole dataset and even across datasets. Because the adaptation occurs entirely at test time, our method requires no ground-truth annotations or dedicated training splits. Additionally, we propose a multi-armed bandit strategy for adaptive frame selection that learns to prioritize informative frames, guided by the same reward formulation. Our evaluation shows that TTA-Vid yields consistent improvements across various video reasoning tasks and is able to outperform current state-of-the-art methods trained on large-scale data. This highlights the potential of test-time reinforcement learning for temporal multimodal understanding.
MM-TS: Multi-Modal Temperature and Margin Schedules for Contrastive Learning with Long-Tail Data
Mar 09, 2026Contrastive learning has become a fundamental approach in both uni-modal and multi-modal frameworks. This learning paradigm pulls positive pairs of samples closer while pushing negatives apart. In the uni-modal setting (e.g., image-based learning), previous research has shown that the strength of these forces can be controlled through the temperature parameter. In this work, we propose Multi-Modal Temperature and Margin Schedules (MM-TS), extending the concept of uni-modal temperature scheduling to multi-modal contrastive learning. Our method dynamically adjusts the temperature in the contrastive loss during training, modulating the attraction and repulsion forces in the multi-modal setting. Additionally, recognizing that standard multi-modal datasets often follow imbalanced, long-tail distributions, we adapt the temperature based on the local distribution of each training sample. Specifically, samples from dense clusters are assigned a higher temperature to better preserve their semantic structure. Furthermore, we demonstrate that temperature scheduling can be effectively integrated within a max-margin framework, thereby unifying the two predominant approaches in multi-modal contrastive learning: InfoNCE loss and max-margin objective. We evaluate our approach on four widely used image- and video-language datasets, Flickr30K, MSCOCO, EPIC-KITCHENS-100, and YouCook2, and show that our dynamic temperature and margin schedules improve performance and lead to new state-of-the-art results in the field.
CALM: Class-Conditional Sparse Attention Vectors for Large Audio-Language Models
Feb 06, 2026Large audio-language models (LALMs) exhibit strong zero-shot capabilities in multiple downstream tasks, such as audio question answering (AQA) and abstract reasoning; however, these models still lag behind specialized models for certain discriminative tasks (e.g., audio classification). Recent studies show that sparse subsets of attention heads within an LALM can serve as strong discriminative feature extractors for downstream tasks such as classification via simple voting schemes. However, these methods assign uniform weights to all selected heads, implicitly assuming that each head contributes equally across all semantic categories. In this work, we propose Class-Conditional Sparse Attention Vectors for Large Audio-Language Models, a few-shot classification method that learns class-dependent importance weights over attention heads. This formulation allows individual heads to specialize in distinct semantic categories and to contribute to ensemble predictions proportionally to their estimated reliability. Experiments on multiple few-shot audio and audiovisual classification benchmarks and tasks demonstrate that our method consistently outperforms state-of-the-art uniform voting-based approaches by up to 14.52%, 1.53%, 8.35% absolute gains for audio classification, audio-visual classification, and spoofing detection respectively.
When LLaVA Meets Objects: Token Composition for Vision-Language-Models
Feb 04, 2026Current autoregressive Vision Language Models (VLMs) usually rely on a large number of visual tokens to represent images, resulting in a need for more compute especially at inference time. To address this problem, we propose Mask-LLaVA, a framework that leverages different levels of visual features to create a compact yet information-rich visual representation for autoregressive VLMs. Namely, we combine mask-based object representations together with global tokens and local patch tokens. While all tokens are used during training, it shows that the resulting model can flexibly drop especially the number of mask-based object-tokens at test time, allowing to adapt the number of tokens during inference without the need to retrain the model and without a significant drop in performance. We evaluate the proposed approach on a suite of standard benchmarks showing results competitive to current token efficient methods and comparable to the original LLaVA baseline using only a fraction of visual tokens. Our analysis demonstrates that combining multi-level features enables efficient learning with fewer tokens while allowing dynamic token selection at test time for good performance.
AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Dec 23, 2025Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, and (3) hierarchical clustering and sampling of training data--typically reserved for self-supervised learning--substantially improves sample efficiency over random sampling for multi-teacher distillation. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts. We release OpenLVD200M and distilled models.
M2SVid: End-to-End Inpainting and Refinement for Monocular-to-Stereo Video Conversion
May 22, 2025We tackle the problem of monocular-to-stereo video conversion and propose a novel architecture for inpainting and refinement of the warped right view obtained by depth-based reprojection of the input left view. We extend the Stable Video Diffusion (SVD) model to utilize the input left video, the warped right video, and the disocclusion masks as conditioning input to generate a high-quality right camera view. In order to effectively exploit information from neighboring frames for inpainting, we modify the attention layers in SVD to compute full attention for discoccluded pixels. Our model is trained to generate the right view video in an end-to-end manner by minimizing image space losses to ensure high-quality generation. Our approach outperforms previous state-of-the-art methods, obtaining an average rank of 1.43 among the 4 compared methods in a user study, while being 6x faster than the second placed method.
Omni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM?
May 14, 2025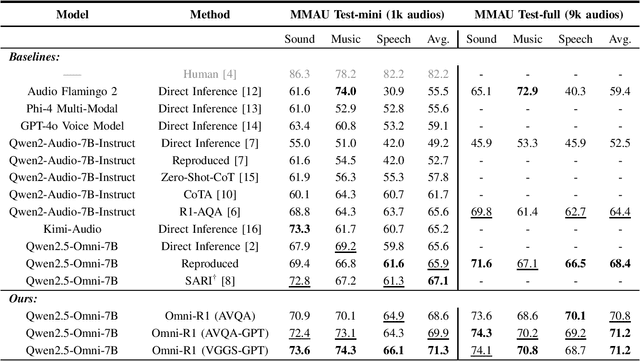
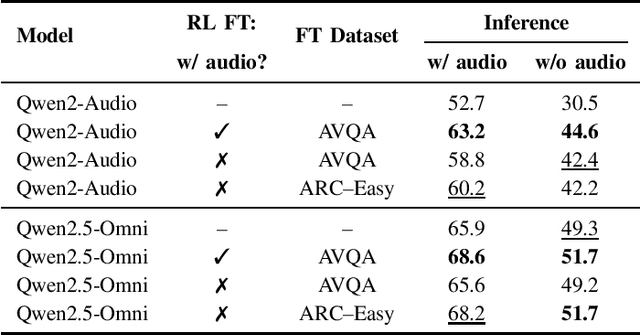
We propose Omni-R1 which fine-tunes a recent multi-modal LLM, Qwen2.5-Omni, on an audio question answering dataset with the reinforcement learning method GRPO. This leads to new State-of-the-Art performance on the recent MMAU benchmark. Omni-R1 achieves the highest accuracies on the sounds, music, speech, and overall average categories, both on the Test-mini and Test-full splits. To understand the performance improvement, we tested models both with and without audio and found that much of the performance improvement from GRPO could be attributed to better text-based reasoning. We also made a surprising discovery that fine-tuning without audio on a text-only dataset was effective at improving the audio-based performance.
REVEAL: Relation-based Video Representation Learning for Video-Question-Answering
Apr 07, 2025Video-Question-Answering (VideoQA) comprises the capturing of complex visual relation changes over time, remaining a challenge even for advanced Video Language Models (VLM), i.a., because of the need to represent the visual content to a reasonably sized input for those models. To address this problem, we propose RElation-based Video rEpresentAtion Learning (REVEAL), a framework designed to capture visual relation information by encoding them into structured, decomposed representations. Specifically, inspired by spatiotemporal scene graphs, we propose to encode video sequences as sets of relation triplets in the form of (\textit{subject-predicate-object}) over time via their language embeddings. To this end, we extract explicit relations from video captions and introduce a Many-to-Many Noise Contrastive Estimation (MM-NCE) together with a Q-Former architecture to align an unordered set of video-derived queries with corresponding text-based relation descriptions. At inference, the resulting Q-former produces an efficient token representation that can serve as input to a VLM for VideoQA. We evaluate the proposed framework on five challenging benchmarks: NeXT-QA, Intent-QA, STAR, VLEP, and TVQA. It shows that the resulting query-based video representation is able to outperform global alignment-based CLS or patch token representations and achieves competitive results against state-of-the-art models, particularly on tasks requiring temporal reasoning and relation comprehension. The code and models will be publicly released.
VideoGEM: Training-free Action Grounding in Videos
Mar 26, 2025



Vision-language foundation models have shown impressive capabilities across various zero-shot tasks, including training-free localization and grounding, primarily focusing on localizing objects in images. However, leveraging those capabilities to localize actions and events in videos is challenging, as actions have less physical outline and are usually described by higher-level concepts. In this work, we propose VideoGEM, the first training-free spatial action grounding method based on pretrained image- and video-language backbones. Namely, we adapt the self-self attention formulation of GEM to spatial activity grounding. We observe that high-level semantic concepts, such as actions, usually emerge in the higher layers of the image- and video-language models. We, therefore, propose a layer weighting in the self-attention path to prioritize higher layers. Additionally, we introduce a dynamic weighting method to automatically tune layer weights to capture each layer`s relevance to a specific prompt. Finally, we introduce a prompt decomposition, processing action, verb, and object prompts separately, resulting in a better spatial localization of actions. We evaluate the proposed approach on three image- and video-language backbones, CLIP, OpenCLIP, and ViCLIP, and on four video grounding datasets, V-HICO, DALY, YouCook-Interactions, and GroundingYouTube, showing that the proposed training-free approach is able to outperform current trained state-of-the-art approaches for spatial video grounding.
Unbiasing through Textual Descriptions: Mitigating Representation Bias in Video Benchmarks
Mar 24, 2025We propose a new "Unbiased through Textual Description (UTD)" video benchmark based on unbiased subsets of existing video classification and retrieval datasets to enable a more robust assessment of video understanding capabilities. Namely, we tackle the problem that current video benchmarks may suffer from different representation biases, e.g., object bias or single-frame bias, where mere recognition of objects or utilization of only a single frame is sufficient for correct prediction. We leverage VLMs and LLMs to analyze and debias benchmarks from such representation biases. Specifically, we generate frame-wise textual descriptions of videos, filter them for specific information (e.g. only objects) and leverage them to examine representation biases across three dimensions: 1) concept bias - determining if a specific concept (e.g., objects) alone suffice for prediction; 2) temporal bias - assessing if temporal information contributes to prediction; and 3) common sense vs. dataset bias - evaluating whether zero-shot reasoning or dataset correlations contribute to prediction. We conduct a systematic analysis of 12 popular video classification and retrieval datasets and create new object-debiased test splits for these datasets. Moreover, we benchmark 30 state-of-the-art video models on original and debiased splits and analyze biases in the models. To facilitate the future development of more robust video understanding benchmarks and models, we release: "UTD-descriptions", a dataset with our rich structured descriptions for each dataset, and "UTD-splits", a dataset of object-debiased test splits.