 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Telephone Game: Evaluating Semantic Drift in Unified Models
Sep 04, 2025Employing a single, unified model (UM) for both visual understanding (image-to-text: I2T) and and visual generation (text-to-image: T2I) has opened a new direction in Visual Language Model (VLM) research. While UMs can also support broader unimodal tasks (e.g., text-to-text, image-to-image), we focus on the core cross-modal pair T2I and I2T, as consistency between understanding and generation is critical for downstream use. Existing evaluations consider these capabilities in isolation: FID and GenEval for T2I, and benchmarks such as MME, MMBench for I2T. These single-pass metrics do not reveal whether a model that understands a concept can also render it, nor whether meaning is preserved when cycling between image and text modalities. To address this, we introduce the Unified Consistency Framework for Unified Models (UCF-UM), a cyclic evaluation protocol that alternates I2T and T2I over multiple generations to quantify semantic drift. UCF formulates 3 metrics: (i) Mean Cumulative Drift (MCD), an embedding-based measure of overall semantic loss; (ii) Semantic Drift Rate (SDR), that summarizes semantic decay rate; and (iii) Multi-Generation GenEval (MGG), an object-level compliance score extending GenEval. To assess generalization beyond COCO, which is widely used in training; we create a new benchmark ND400, sampled from NoCaps and DOCCI and evaluate on seven recent models. UCF-UM reveals substantial variation in cross-modal stability: some models like BAGEL maintain semantics over many alternations, whereas others like Vila-u drift quickly despite strong single-pass scores. Our results highlight cyclic consistency as a necessary complement to standard I2T and T2I evaluations, and provide practical metrics to consistently assess unified model's cross-modal stability and strength of their shared representations. Code: https://github.com/mollahsabbir/Semantic-Drift-in-Unified-Models
TimeLogic: A Temporal Logic Benchmark for Video QA
Jan 13, 2025Temporal logical understanding, a core facet of human cognition, plays a pivotal role in capturing complex sequential events and their temporal relationships within videos. This capability is particularly crucial in tasks like Video Question Answering (VideoQA), where the goal is to process visual data over time together with textual data to provide coherent answers. However, current VideoQA benchmarks devote little focus to evaluating this critical skill due to the challenge of annotating temporal logic. Despite the advancement of vision-language models, assessing their temporal logical reasoning powers remains a challenge, primarily due to the lack QA pairs that demand formal, complex temporal reasoning. To bridge this gap, we introduce the TimeLogic QA (TLQA) framework to automatically generate the QA pairs, specifically designed to evaluate the temporal logical understanding. To this end, TLQA leverages temporal annotations from existing video datasets together with temporal operators derived from logic theory to construct questions that test understanding of event sequences and their temporal relationships. TLQA framework is generic and scalable, capable of leveraging both, existing video action datasets with temporal action segmentation annotations, or video datasets with temporal scene graph annotations, to automatically generate temporal logical questions. We leverage 4 datasets, STAR, Breakfast, AGQA, and CrossTask, and generate two VideoQA dataset variants - small (TLQA-S) and large (TLQA-L) - containing 2k and 10k QA pairs for each category, resulting in 32k and 160k total pairs per dataset. We undertake a comprehensive evaluation of leading-edge VideoQA models, employing the TLQA to benchmark their temporal logical understanding capabilities. We assess the VideoQA model's temporal reasoning performance on 16 categories of temporal logic with varying temporal complexity.
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Jul 18, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by integrating visual perception capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and detailed visual representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) and MAE-ViT (MIM-based). It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding detailed visual understanding. Extensive evaluations indicate that X-Former excels in visual reasoning tasks involving both structural and semantic categories in the GQA dataset. Assessment on fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.
Unsupervised Discriminative Embedding for Sub-Action Learning in Complex Activities
Apr 30, 2021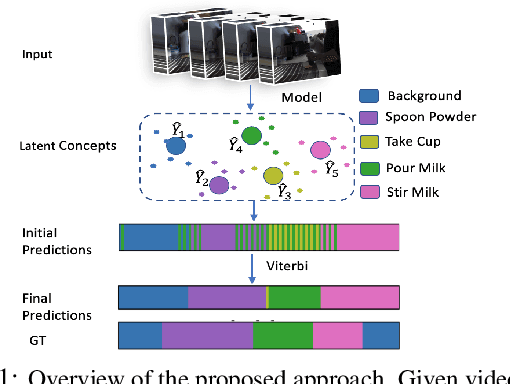
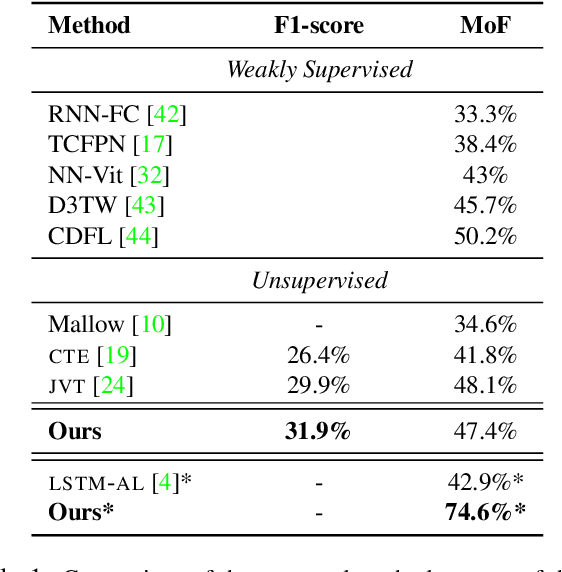
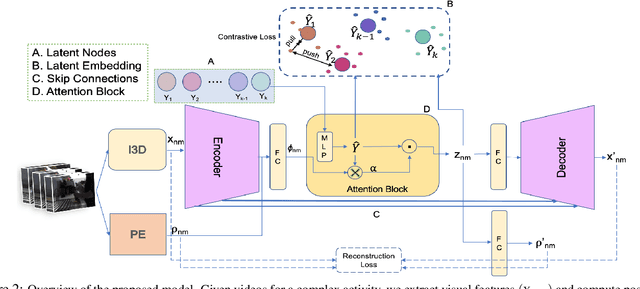

Action recognition and detection in the context of long untrimmed video sequences has seen an increased attention from the research community. However, annotation of complex activities is usually time consuming and challenging in practice. Therefore, recent works started to tackle the problem of unsupervised learning of sub-actions in complex activities. This paper proposes a novel approach for unsupervised sub-action learning in complex activities. The proposed method maps both visual and temporal representations to a latent space where the sub-actions are learnt discriminatively in an end-to-end fashion. To this end, we propose to learn sub-actions as latent concepts and a novel discriminative latent concept learning (DLCL) module aids in learning sub-actions. The proposed DLCL module lends on the idea of latent concepts to learn compact representations in the latent embedding space in an unsupervised way. The result is a set of latent vectors that can be interpreted as cluster centers in the embedding space. The latent space itself is formed by a joint visual and temporal embedding capturing the visual similarity and temporal ordering of the data. Our joint learning with discriminative latent concept module is novel which eliminates the need for explicit clustering. We validate our approach on three benchmark datasets and show that the proposed combination of visual-temporal embedding and discriminative latent concepts allow to learn robust action representations in an unsupervised setting.