 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualGate-Net: A Prior-Gated Dual-Encoder Framework for Histopathology Cell Detection
Jun 05, 2026Cell detection in histopathology images strongly depends on surrounding tissue context, where visually similar cells may belong to different classes under different microenvironments. Recent tissue-aware methods incorporate contextual priors, but often rely on static fusion strategies that may propagate noisy information. In this work, we propose DualGate-Net, a prior-aware dual-encoder framework that combines a ConvNeXtV2-based local encoder and a SegFormer-based global encoder through a learnable prior-gated fusion mechanism. The proposed module adaptively regulates the influence of tissue priors across spatial locations, while an auxiliary foreground reconstruction branch preserves high-frequency cellular structures during training. In addition, auxiliary cellness-guided cues are incorporated to further improve localization robustness. Experiments on the OCELOT benchmark demonstrate consistent improvements, achieving macro F1-scores of 0.7722 on the validation set and 0.7345 on the test set, highlighting the effectiveness of adaptive prior integration for robust histopathology cell detection.
ViLL-E: Video LLM Embeddings for Retrieval
Apr 13, 2026Video Large Language Models (VideoLLMs) excel at video understanding tasks where outputs are textual, such as Video Question Answering and Video Captioning. However, they underperform specialized embedding-based models in Retrieval tasks, such as Text-toVideo Retrieval and Moment Retrieval. We introduce ViLL-E (Video-LLM-Embed), a unified VideoLLM architecture endowed with a novel embedding generation mechanism that allows the model to "think longer" for complex videos and stop early for easy ones. We train this model with a three-stage training methodology combining generative and contrastive learning: initial large-scale pre-training with video-caption pairs; followed by continual training on a smaller, detailed-caption dataset; and concluding with task-specific fine-tuning on a novel multi-task dataset covering Video QA, Temporal Localization, Video Retrieval, and Video-Text Matching. Our model significantly improves temporal localization (on avg. 7% over other VideoLLMs) and video retrieval (up to 4% over dual encoder models), achieving performance comparable to state-of-the-art specialized embedding models while remaining competitive on VideoQA tasks. Furthermore, our joint contrastive-generative training unlocks new zero-shot capabilities, significantly outperforming state-of-the-art methods in composed video retrieval (+5% over SotA) and retrieval from long text (+2% over SotA).
Dictionary-Aligned Concept Control for Safeguarding Multimodal LLMs
Apr 10, 2026Multimodal Large Language Models (MLLMs) have been shown to be vulnerable to malicious queries that can elicit unsafe responses. Recent work uses prompt engineering, response classification, or finetuning to improve MLLM safety. Nevertheless, such approaches are often ineffective against evolving malicious patterns, may require rerunning the query, or demand heavy computational resources. Steering the activations of a frozen model at inference time has recently emerged as a flexible and effective solution. However, existing steering methods for MLLMs typically handle only a narrow set of safety-related concepts or struggle to adjust specific concepts without affecting others. To address these challenges, we introduce Dictionary-Aligned Concept Control (DACO), a framework that utilizes a curated concept dictionary and a Sparse Autoencoder (SAE) to provide granular control over MLLM activations. First, we curate a dictionary of 15,000 multimodal concepts by retrieving over 400,000 caption-image stimuli and summarizing their activations into concept directions. We name the dataset DACO-400K. Second, we show that the curated dictionary can be used to intervene activations via sparse coding. Third, we propose a new steering approach that uses our dictionary to initialize the training of an SAE and automatically annotate the semantics of the SAE atoms for safeguarding MLLMs. Experiments on multiple MLLMs (e.g., QwenVL, LLaVA, InternVL) across safety benchmarks (e.g., MM-SafetyBench, JailBreakV) show that DACO significantly improves MLLM safety while maintaining general-purpose capabilities.
Large Language Models: A Mathematical Formulation
Jan 21, 2026Large language models (LLMs) process and predict sequences containing text to answer questions, and address tasks including document summarization, providing recommendations, writing software and solving quantitative problems. We provide a mathematical framework for LLMs by describing the encoding of text sequences into sequences of tokens, defining the architecture for next-token prediction models, explaining how these models are learned from data, and demonstrating how they are deployed to address a variety of tasks. The mathematical sophistication required to understand this material is not high, and relies on straightforward ideas from information theory, probability and optimization. Nonetheless, the combination of ideas resting on these different components from the mathematical sciences yields a complex algorithmic structure; and this algorithmic structure has demonstrated remarkable empirical successes. The mathematical framework established here provides a platform from which it is possible to formulate and address questions concerning the accuracy, efficiency and robustness of the algorithms that constitute LLMs. The framework also suggests directions for development of modified and new methodologies.
A Mathematical Perspective On Contrastive Learning
May 30, 2025Multimodal contrastive learning is a methodology for linking different data modalities; the canonical example is linking image and text data. The methodology is typically framed as the identification of a set of encoders, one for each modality, that align representations within a common latent space. In this work, we focus on the bimodal setting and interpret contrastive learning as the optimization of (parameterized) encoders that define conditional probability distributions, for each modality conditioned on the other, consistent with the available data. This provides a framework for multimodal algorithms such as crossmodal retrieval, which identifies the mode of one of these conditional distributions, and crossmodal classification, which is similar to retrieval but includes a fine-tuning step to make it task specific. The framework we adopt also gives rise to crossmodal generative models. This probabilistic perspective suggests two natural generalizations of contrastive learning: the introduction of novel probabilistic loss functions, and the use of alternative metrics for measuring alignment in the common latent space. We study these generalizations of the classical approach in the multivariate Gaussian setting. In this context we view the latent space identification as a low-rank matrix approximation problem. This allows us to characterize the capabilities of loss functions and alignment metrics to approximate natural statistics, such as conditional means and covariances; doing so yields novel variants on contrastive learning algorithms for specific mode-seeking and for generative tasks. The framework we introduce is also studied through numerical experiments on multivariate Gaussians, the labeled MNIST dataset, and on a data assimilation application arising in oceanography.
CoLLM: A Large Language Model for Composed Image Retrieval
Mar 25, 2025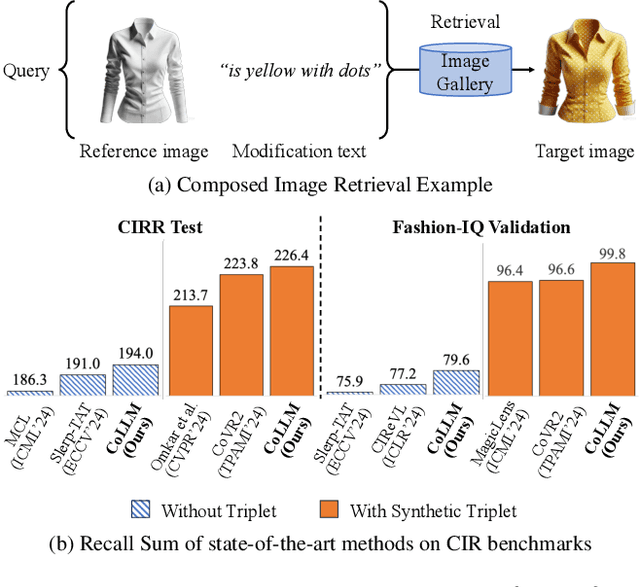
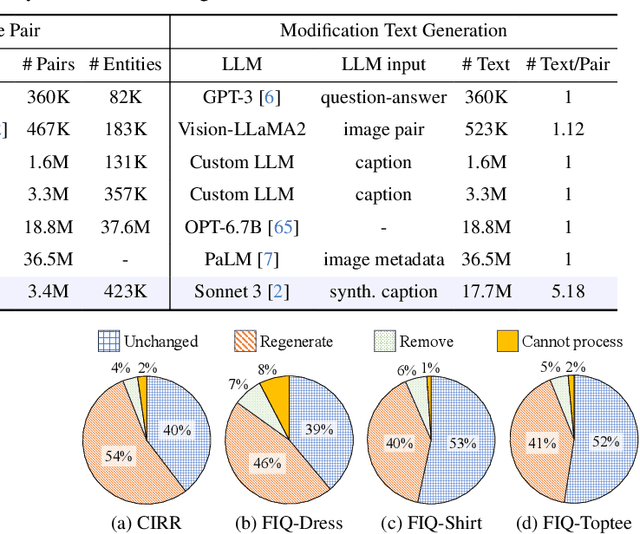
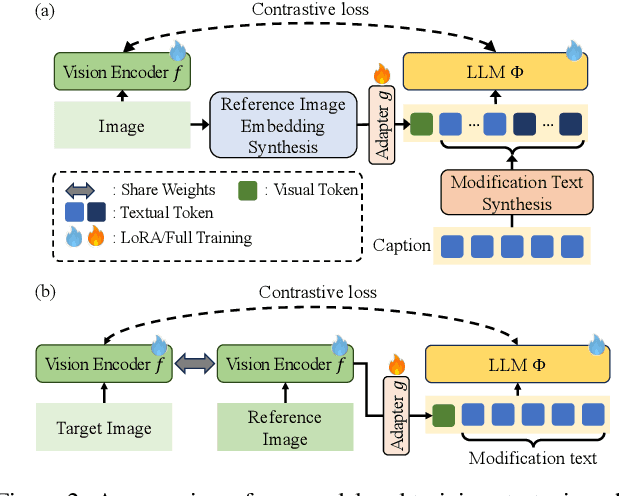
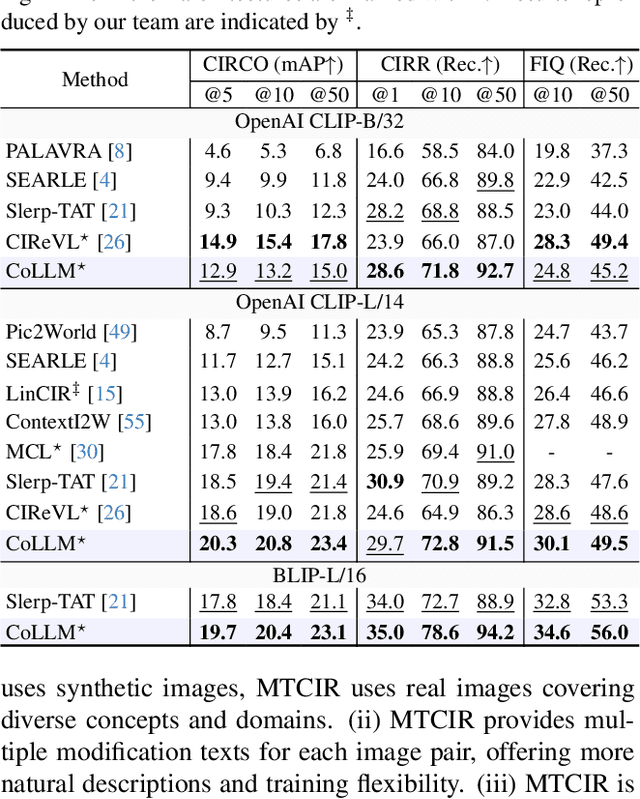
Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language models (VLMs) with ubiquitous web-crawled image-caption pairs. However, these methods have significant limitations: synthetic triplets suffer from limited scale, lack of diversity, and unnatural modification text, while image-caption pairs hinder joint embedding learning of the multimodal query due to the absence of triplet data. Moreover, existing approaches struggle with complex and nuanced modification texts that demand sophisticated fusion and understanding of vision and language modalities. We present CoLLM, a one-stop framework that effectively addresses these limitations. Our approach generates triplets on-the-fly from image-caption pairs, enabling supervised training without manual annotation. We leverage Large Language Models (LLMs) to generate joint embeddings of reference images and modification texts, facilitating deeper multimodal fusion. Additionally, we introduce Multi-Text CIR (MTCIR), a large-scale dataset comprising 3.4M samples, and refine existing CIR benchmarks (CIRR and Fashion-IQ) to enhance evaluation reliability. Experimental results demonstrate that CoLLM achieves state-of-the-art performance across multiple CIR benchmarks and settings. MTCIR yields competitive results, with up to 15% performance improvement. Our refined benchmarks provide more reliable evaluation metrics for CIR models, contributing to the advancement of this important field.
M-LLM Based Video Frame Selection for Efficient Video Understanding
Feb 27, 2025Recent advances in Multi-Modal Large Language Models (M-LLMs) show promising results in video reasoning. Popular Multi-Modal Large Language Model (M-LLM) frameworks usually apply naive uniform sampling to reduce the number of video frames that are fed into an M-LLM, particularly for long context videos. However, it could lose crucial context in certain periods of a video, so that the downstream M-LLM may not have sufficient visual information to answer a question. To attack this pain point, we propose a light-weight M-LLM -based frame selection method that adaptively select frames that are more relevant to users' queries. In order to train the proposed frame selector, we introduce two supervision signals (i) Spatial signal, where single frame importance score by prompting a M-LLM; (ii) Temporal signal, in which multiple frames selection by prompting Large Language Model (LLM) using the captions of all frame candidates. The selected frames are then digested by a frozen downstream video M-LLM for visual reasoning and question answering. Empirical results show that the proposed M-LLM video frame selector improves the performances various downstream video Large Language Model (video-LLM) across medium (ActivityNet, NExT-QA) and long (EgoSchema, LongVideoBench) context video question answering benchmarks.
Bringing Multimodality to Amazon Visual Search System
Dec 17, 2024



Image to image matching has been well studied in the computer vision community. Previous studies mainly focus on training a deep metric learning model matching visual patterns between the query image and gallery images. In this study, we show that pure image-to-image matching suffers from false positives caused by matching to local visual patterns. To alleviate this issue, we propose to leverage recent advances in vision-language pretraining research. Specifically, we introduce additional image-text alignment losses into deep metric learning, which serve as constraints to the image-to-image matching loss. With additional alignments between the text (e.g., product title) and image pairs, the model can learn concepts from both modalities explicitly, which avoids matching low-level visual features. We progressively develop two variants, a 3-tower and a 4-tower model, where the latter takes one more short text query input. Through extensive experiments, we show that this change leads to a substantial improvement to the image to image matching problem. We further leveraged this model for multimodal search, which takes both image and reformulation text queries to improve search quality. Both offline and online experiments show strong improvements on the main metrics. Specifically, we see 4.95% relative improvement on image matching click through rate with the 3-tower model and 1.13% further improvement from the 4-tower model.
DreamBlend: Advancing Personalized Fine-tuning of Text-to-Image Diffusion Models
Nov 28, 2024



Given a small number of images of a subject, personalized image generation techniques can fine-tune large pre-trained text-to-image diffusion models to generate images of the subject in novel contexts, conditioned on text prompts. In doing so, a trade-off is made between prompt fidelity, subject fidelity and diversity. As the pre-trained model is fine-tuned, earlier checkpoints synthesize images with low subject fidelity but high prompt fidelity and diversity. In contrast, later checkpoints generate images with low prompt fidelity and diversity but high subject fidelity. This inherent trade-off limits the prompt fidelity, subject fidelity and diversity of generated images. In this work, we propose DreamBlend to combine the prompt fidelity from earlier checkpoints and the subject fidelity from later checkpoints during inference. We perform a cross attention guided image synthesis from a later checkpoint, guided by an image generated by an earlier checkpoint, for the same prompt. This enables generation of images with better subject fidelity, prompt fidelity and diversity on challenging prompts, outperforming state-of-the-art fine-tuning methods.
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Jul 18, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by integrating visual perception capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and detailed visual representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) and MAE-ViT (MIM-based). It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding detailed visual understanding. Extensive evaluations indicate that X-Former excels in visual reasoning tasks involving both structural and semantic categories in the GQA dataset. Assessment on fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.