 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossmodal Knowledge Distillation with WordNet-Relaxed Text Embeddings for Robust Image Classification
Mar 31, 2025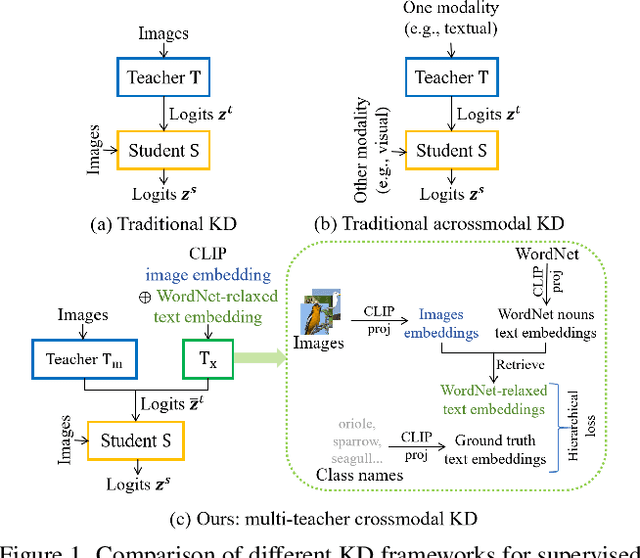
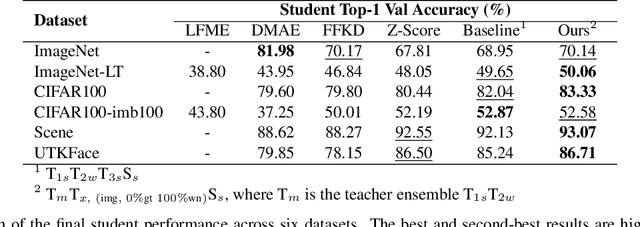
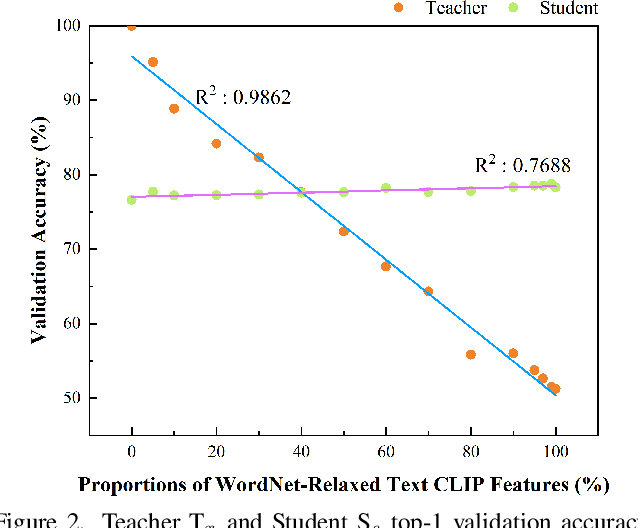
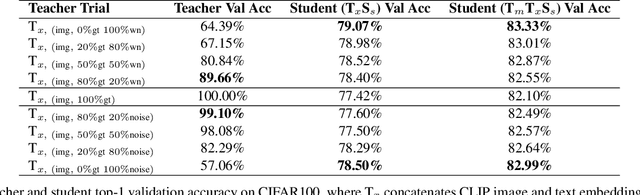
Crossmodal knowledge distillation (KD) aims to enhance a unimodal student using a multimodal teacher model. In particular, when the teacher's modalities include the student's, additional complementary information can be exploited to improve knowledge transfer. In supervised image classification, image datasets typically include class labels that represent high-level concepts, suggesting a natural avenue to incorporate textual cues for crossmodal KD. However, these labels rarely capture the deeper semantic structures in real-world visuals and can lead to label leakage if used directly as inputs, ultimately limiting KD performance. To address these issues, we propose a multi-teacher crossmodal KD framework that integrates CLIP image embeddings with learnable WordNet-relaxed text embeddings under a hierarchical loss. By avoiding direct use of exact class names and instead using semantically richer WordNet expansions, we mitigate label leakage and introduce more diverse textual cues. Experiments show that this strategy significantly boosts student performance, whereas noisy or overly precise text embeddings hinder distillation efficiency. Interpretability analyses confirm that WordNet-relaxed prompts encourage heavier reliance on visual features over textual shortcuts, while still effectively incorporating the newly introduced textual cues. Our method achieves state-of-the-art or second-best results on six public datasets, demonstrating its effectiveness in advancing crossmodal KD.
Supervision-free Vision-Language Alignment
Jan 08, 2025Vision-language models (VLMs) have demonstrated remarkable potential in integrating visual and linguistic information, but their performance is often constrained by the need for extensive, high-quality image-text training data. Curation of these image-text pairs is both time-consuming and computationally expensive. To address this challenge, we introduce SVP (Supervision-free Visual Projection), a novel framework that enhances vision-language alignment without relying on curated data or preference annotation. SVP leverages self-captioning and a pre-trained grounding model as a feedback mechanism to elicit latent information in VLMs. We evaluate our approach across six key areas: captioning, referring, visual question answering, multitasking, hallucination control, and object recall. Results demonstrate significant improvements, including a 14% average improvement in captioning tasks, up to 12% increase in object recall, and substantial reduction in hallucination rates. Notably, a small VLM using SVP achieves hallucination reductions comparable to a model five times larger, while a VLM with initially poor referring capabilities more than doubles its performance, approaching parity with a model twice its size.
DreamBlend: Advancing Personalized Fine-tuning of Text-to-Image Diffusion Models
Nov 28, 2024



Given a small number of images of a subject, personalized image generation techniques can fine-tune large pre-trained text-to-image diffusion models to generate images of the subject in novel contexts, conditioned on text prompts. In doing so, a trade-off is made between prompt fidelity, subject fidelity and diversity. As the pre-trained model is fine-tuned, earlier checkpoints synthesize images with low subject fidelity but high prompt fidelity and diversity. In contrast, later checkpoints generate images with low prompt fidelity and diversity but high subject fidelity. This inherent trade-off limits the prompt fidelity, subject fidelity and diversity of generated images. In this work, we propose DreamBlend to combine the prompt fidelity from earlier checkpoints and the subject fidelity from later checkpoints during inference. We perform a cross attention guided image synthesis from a later checkpoint, guided by an image generated by an earlier checkpoint, for the same prompt. This enables generation of images with better subject fidelity, prompt fidelity and diversity on challenging prompts, outperforming state-of-the-art fine-tuning methods.
Why does Knowledge Distillation Work? Rethink its Attention and Fidelity Mechanism
Apr 30, 2024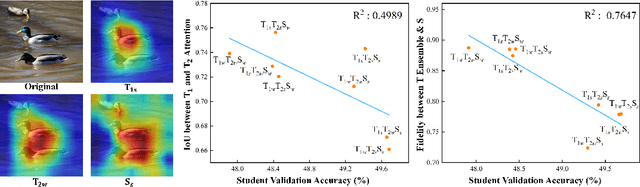
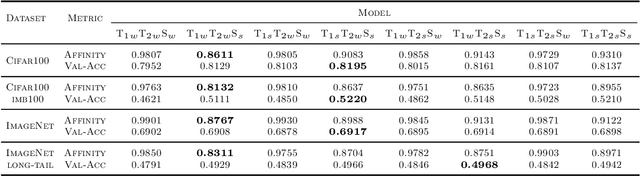
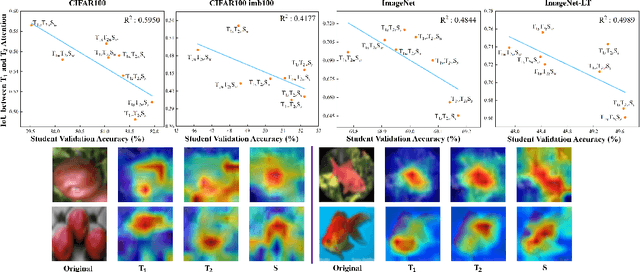
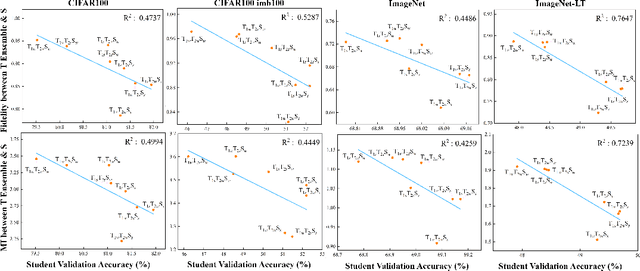
Does Knowledge Distillation (KD) really work? Conventional wisdom viewed it as a knowledge transfer procedure where a perfect mimicry of the student to its teacher is desired. However, paradoxical studies indicate that closely replicating the teacher's behavior does not consistently improve student generalization, posing questions on its possible causes. Confronted with this gap, we hypothesize that diverse attentions in teachers contribute to better student generalization at the expense of reduced fidelity in ensemble KD setups. By increasing data augmentation strengths, our key findings reveal a decrease in the Intersection over Union (IoU) of attentions between teacher models, leading to reduced student overfitting and decreased fidelity. We propose this low-fidelity phenomenon as an underlying characteristic rather than a pathology when training KD. This suggests that stronger data augmentation fosters a broader perspective provided by the divergent teacher ensemble and lower student-teacher mutual information, benefiting generalization performance. These insights clarify the mechanism on low-fidelity phenomenon in KD. Thus, we offer new perspectives on optimizing student model performance, by emphasizing increased diversity in teacher attentions and reduced mimicry behavior between teachers and student.
Structural Similarity: When to Use Deep Generative Models on Imbalanced Image Dataset Augmentation
Mar 08, 2023



Improving the performance on an imbalanced training set is one of the main challenges in nowadays Machine Learning. One way to augment and thus re-balance the image dataset is through existing deep generative models, like class-conditional Generative Adversarial Networks (cGAN) or Diffusion Models by synthesizing images on each of the tail-class. Our experiments on imbalanced image dataset classification show that, the validation accuracy improvement with such re-balancing method is related to the image similarity between different classes. Thus, to quantify this image dataset class similarity, we propose a measurement called Super-Sub Class Structural Similarity (SSIM-supSubCls) based on Structural Similarity (SSIM). A deep generative model data augmentation classification (GM-augCls) pipeline is also provided to verify this metric correlates with the accuracy enhancement. We further quantify the relationship between them, discovering that the accuracy improvement decays exponentially with respect to SSIM-supSubCls values.
Near Perfect GAN Inversion
Feb 23, 2022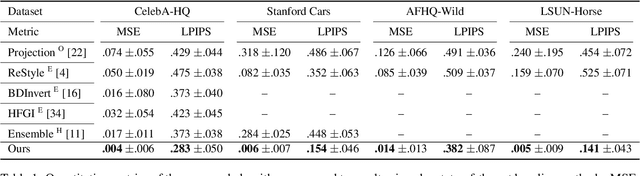
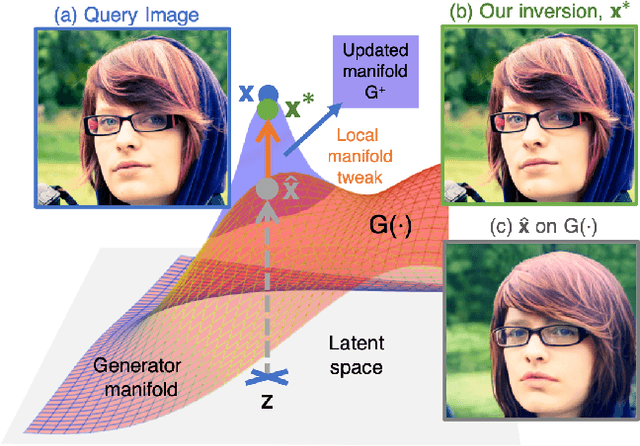


To edit a real photo using Generative Adversarial Networks (GANs), we need a GAN inversion algorithm to identify the latent vector that perfectly reproduces it. Unfortunately, whereas existing inversion algorithms can synthesize images similar to real photos, they cannot generate the identical clones needed in most applications. Here, we derive an algorithm that achieves near perfect reconstructions of photos. Rather than relying on encoder- or optimization-based methods to find an inverse mapping on a fixed generator $G(\cdot)$, we derive an approach to locally adjust $G(\cdot)$ to more optimally represent the photos we wish to synthesize. This is done by locally tweaking the learned mapping $G(\cdot)$ s.t. $\| {\bf x} - G({\bf z}) \|<\epsilon$, with ${\bf x}$ the photo we wish to reproduce, ${\bf z}$ the latent vector, $\|\cdot\|$ an appropriate metric, and $\epsilon > 0$ a small scalar. We show that this approach can not only produce synthetic images that are indistinguishable from the real photos we wish to replicate, but that these images are readily editable. We demonstrate the effectiveness of the derived algorithm on a variety of datasets including human faces, animals, and cars, and discuss its importance for diversity and inclusion.
When do GANs replicate? On the choice of dataset size
Feb 23, 2022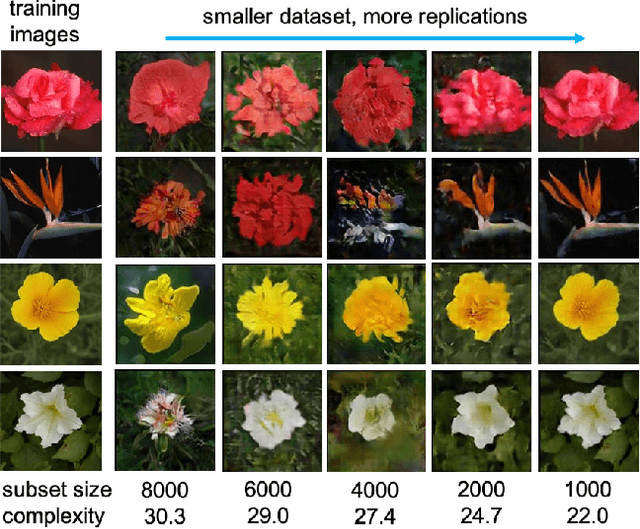



Do GANs replicate training images? Previous studies have shown that GANs do not seem to replicate training data without significant change in the training procedure. This leads to a series of research on the exact condition needed for GANs to overfit to the training data. Although a number of factors has been theoretically or empirically identified, the effect of dataset size and complexity on GANs replication is still unknown. With empirical evidence from BigGAN and StyleGAN2, on datasets CelebA, Flower and LSUN-bedroom, we show that dataset size and its complexity play an important role in GANs replication and perceptual quality of the generated images. We further quantify this relationship, discovering that replication percentage decays exponentially with respect to dataset size and complexity, with a shared decaying factor across GAN-dataset combinations. Meanwhile, the perceptual image quality follows a U-shape trend w.r.t dataset size. This finding leads to a practical tool for one-shot estimation on minimal dataset size to prevent GAN replication which can be used to guide datasets construction and selection.
Diamond in the rough: Improving image realism by traversing the GAN latent space
Apr 12, 2021
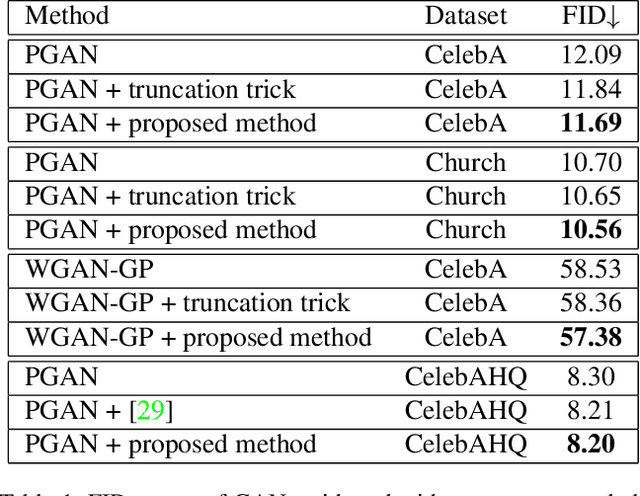
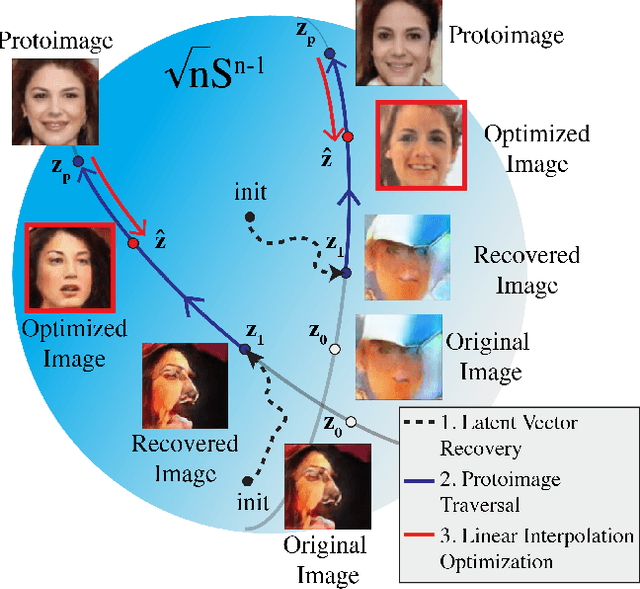
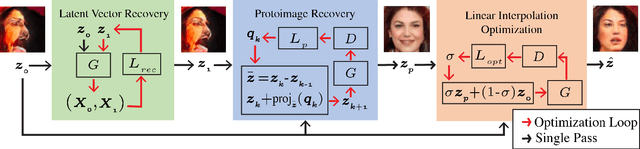
In just a few years, the photo-realism of images synthesized by Generative Adversarial Networks (GANs) has gone from somewhat reasonable to almost perfect largely by increasing the complexity of the networks, e.g., adding layers, intermediate latent spaces, style-transfer parameters, etc. This trajectory has led many of the state-of-the-art GANs to be inaccessibly large, disengaging many without large computational resources. Recognizing this, we explore a method for squeezing additional performance from existing, low-complexity GANs. Formally, we present an unsupervised method to find a direction in the latent space that aligns with improved photo-realism. Our approach leaves the network unchanged while enhancing the fidelity of the generated image. We use a simple generator inversion to find the direction in the latent space that results in the smallest change in the image space. Leveraging the learned structure of the latent space, we find moving in this direction corrects many image artifacts and brings the image into greater realism. We verify our findings qualitatively and quantitatively, showing an improvement in Frechet Inception Distance (FID) exists along our trajectory which surpasses the original GAN and other approaches including a supervised method. We expand further and provide an optimization method to automatically select latent vectors along the path that balance the variation and realism of samples. We apply our method to several diverse datasets and three architectures of varying complexity to illustrate the generalizability of our approach. By expanding the utility of low-complexity and existing networks, we hope to encourage the democratization of GANs.
Adding Knowledge to Unsupervised Algorithms for the Recognition of Intent
Nov 12, 2020
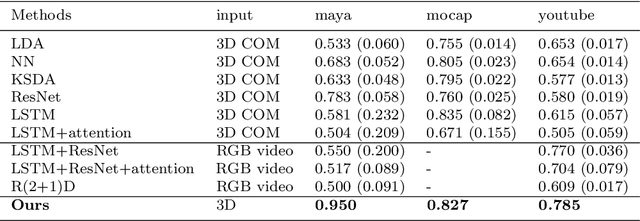
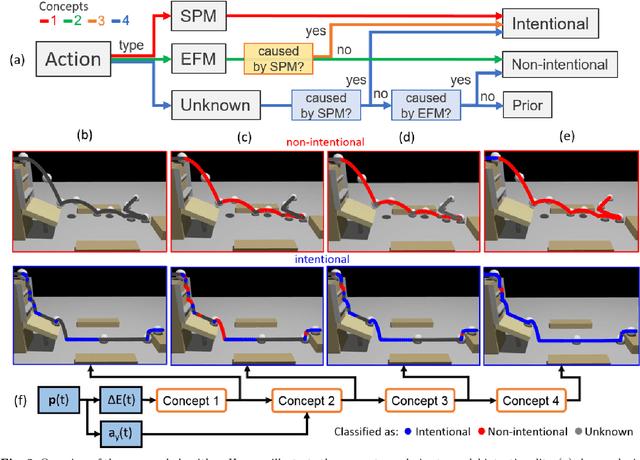

Computer vision algorithms performance are near or superior to humans in the visual problems including object recognition (especially those of fine-grained categories), segmentation, and 3D object reconstruction from 2D views. Humans are, however, capable of higher-level image analyses. A clear example, involving theory of mind, is our ability to determine whether a perceived behavior or action was performed intentionally or not. In this paper, we derive an algorithm that can infer whether the behavior of an agent in a scene is intentional or unintentional based on its 3D kinematics, using the knowledge of self-propelled motion, Newtonian motion and their relationship. We show how the addition of this basic knowledge leads to a simple, unsupervised algorithm. To test the derived algorithm, we constructed three dedicated datasets from abstract geometric animation to realistic videos of agents performing intentional and non-intentional actions. Experiments on these datasets show that our algorithm can recognize whether an action is intentional or not, even without training data. The performance is comparable to various supervised baselines quantitatively, with sensible intentionality segmentation qualitatively.
EmotioNet Challenge: Recognition of facial expressions of emotion in the wild
Mar 03, 2017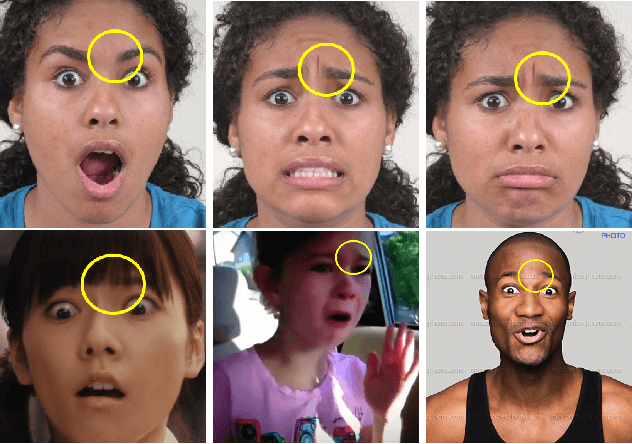
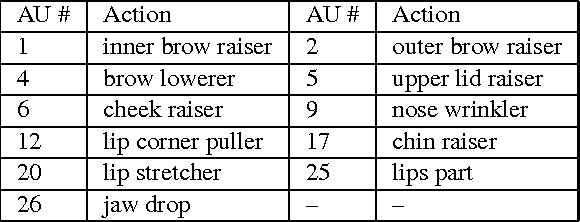
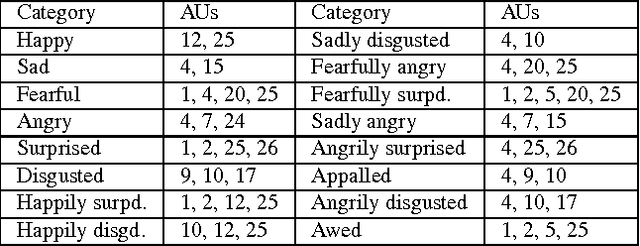

This paper details the methodology and results of the EmotioNet challenge. This challenge is the first to test the ability of computer vision algorithms in the automatic analysis of a large number of images of facial expressions of emotion in the wild. The challenge was divided into two tracks. The first track tested the ability of current computer vision algorithms in the automatic detection of action units (AUs). Specifically, we tested the detection of 11 AUs. The second track tested the algorithms' ability to recognize emotion categories in images of facial expressions. Specifically, we tested the recognition of 16 basic and compound emotion categories. The results of the challenge suggest that current computer vision and machine learning algorithms are unable to reliably solve these two tasks. The limitations of current algorithms are more apparent when trying to recognize emotion. We also show that current algorithms are not affected by mild resolution changes, small occluders, gender or age, but that 3D pose is a major limiting factor on performance. We provide an in-depth discussion of the points that need special attention moving forward.