 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging The Topological Consistencies of Learning in Deep Neural Networks
Nov 30, 2021

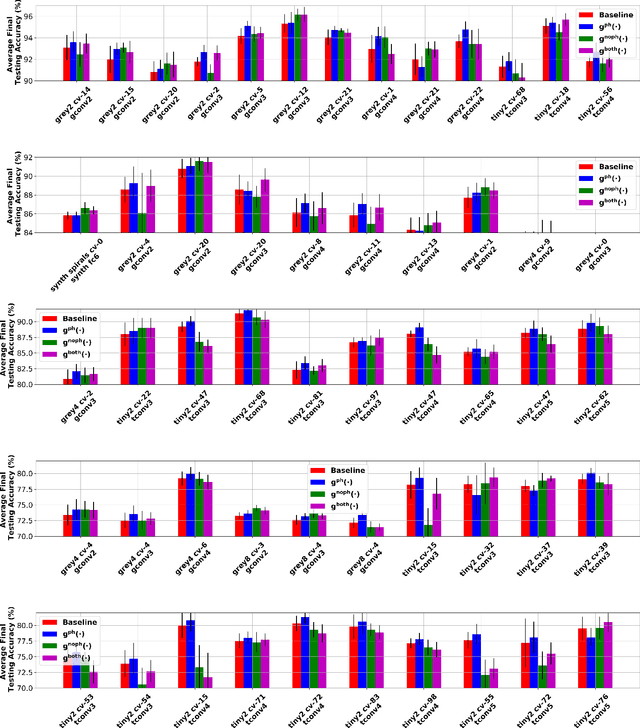
Recently, methods have been developed to accurately predict the testing performance of a Deep Neural Network (DNN) on a particular task, given statistics of its underlying topological structure. However, further leveraging this newly found insight for practical applications is intractable due to the high computational cost in terms of time and memory. In this work, we define a new class of topological features that accurately characterize the progress of learning while being quick to compute during running time. Additionally, our proposed topological features are readily equipped for backpropagation, meaning that they can be incorporated in end-to-end training. Our newly developed practical topological characterization of DNNs allows for an additional set of applications. We first show we can predict the performance of a DNN without a testing set and without the need for high-performance computing. We also demonstrate our topological characterization of DNNs is effective in estimating task similarity. Lastly, we show we can induce learning in DNNs by actively constraining the DNN's topological structure. This opens up new avenues in constricting the underlying structure of DNNs in a meta-learning framework.
Adding Knowledge to Unsupervised Algorithms for the Recognition of Intent
Nov 12, 2020
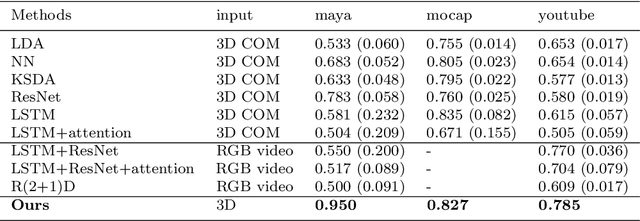
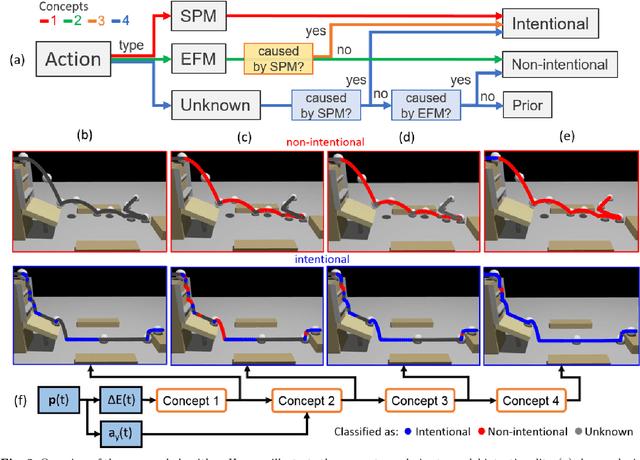

Computer vision algorithms performance are near or superior to humans in the visual problems including object recognition (especially those of fine-grained categories), segmentation, and 3D object reconstruction from 2D views. Humans are, however, capable of higher-level image analyses. A clear example, involving theory of mind, is our ability to determine whether a perceived behavior or action was performed intentionally or not. In this paper, we derive an algorithm that can infer whether the behavior of an agent in a scene is intentional or unintentional based on its 3D kinematics, using the knowledge of self-propelled motion, Newtonian motion and their relationship. We show how the addition of this basic knowledge leads to a simple, unsupervised algorithm. To test the derived algorithm, we constructed three dedicated datasets from abstract geometric animation to realistic videos of agents performing intentional and non-intentional actions. Experiments on these datasets show that our algorithm can recognize whether an action is intentional or not, even without training data. The performance is comparable to various supervised baselines quantitatively, with sensible intentionality segmentation qualitatively.