 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Similarity: When to Use Deep Generative Models on Imbalanced Image Dataset Augmentation
Mar 08, 2023



Improving the performance on an imbalanced training set is one of the main challenges in nowadays Machine Learning. One way to augment and thus re-balance the image dataset is through existing deep generative models, like class-conditional Generative Adversarial Networks (cGAN) or Diffusion Models by synthesizing images on each of the tail-class. Our experiments on imbalanced image dataset classification show that, the validation accuracy improvement with such re-balancing method is related to the image similarity between different classes. Thus, to quantify this image dataset class similarity, we propose a measurement called Super-Sub Class Structural Similarity (SSIM-supSubCls) based on Structural Similarity (SSIM). A deep generative model data augmentation classification (GM-augCls) pipeline is also provided to verify this metric correlates with the accuracy enhancement. We further quantify the relationship between them, discovering that the accuracy improvement decays exponentially with respect to SSIM-supSubCls values.
When do GANs replicate? On the choice of dataset size
Feb 23, 2022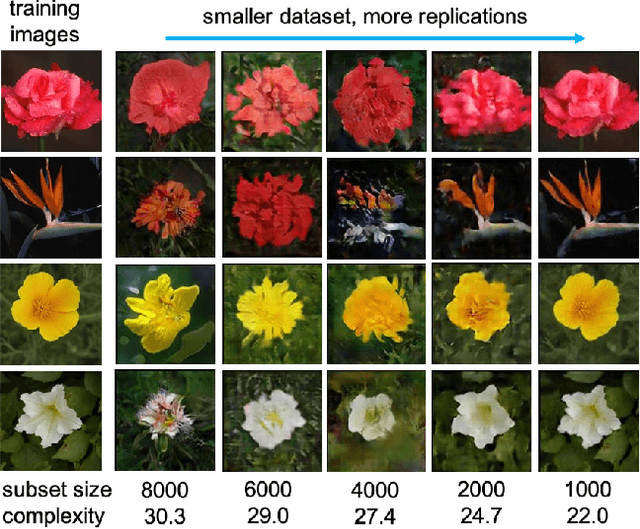



Do GANs replicate training images? Previous studies have shown that GANs do not seem to replicate training data without significant change in the training procedure. This leads to a series of research on the exact condition needed for GANs to overfit to the training data. Although a number of factors has been theoretically or empirically identified, the effect of dataset size and complexity on GANs replication is still unknown. With empirical evidence from BigGAN and StyleGAN2, on datasets CelebA, Flower and LSUN-bedroom, we show that dataset size and its complexity play an important role in GANs replication and perceptual quality of the generated images. We further quantify this relationship, discovering that replication percentage decays exponentially with respect to dataset size and complexity, with a shared decaying factor across GAN-dataset combinations. Meanwhile, the perceptual image quality follows a U-shape trend w.r.t dataset size. This finding leads to a practical tool for one-shot estimation on minimal dataset size to prevent GAN replication which can be used to guide datasets construction and selection.
Leveraging The Topological Consistencies of Learning in Deep Neural Networks
Nov 30, 2021

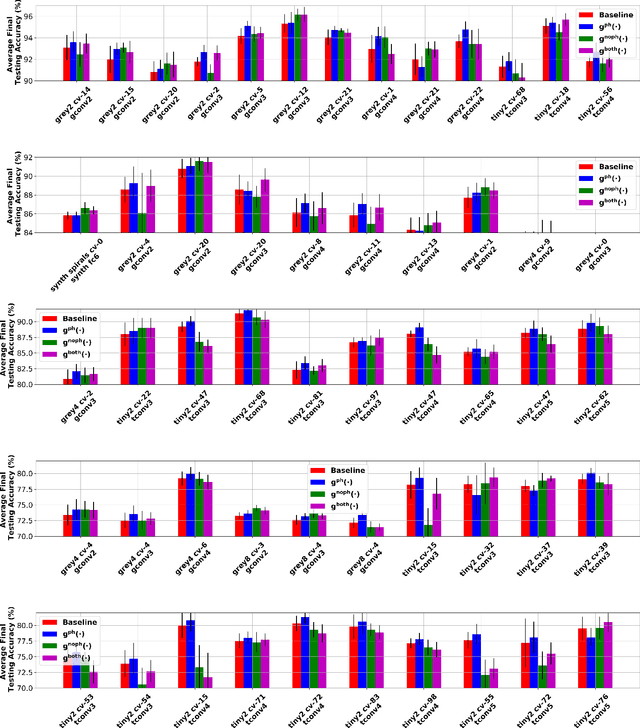
Recently, methods have been developed to accurately predict the testing performance of a Deep Neural Network (DNN) on a particular task, given statistics of its underlying topological structure. However, further leveraging this newly found insight for practical applications is intractable due to the high computational cost in terms of time and memory. In this work, we define a new class of topological features that accurately characterize the progress of learning while being quick to compute during running time. Additionally, our proposed topological features are readily equipped for backpropagation, meaning that they can be incorporated in end-to-end training. Our newly developed practical topological characterization of DNNs allows for an additional set of applications. We first show we can predict the performance of a DNN without a testing set and without the need for high-performance computing. We also demonstrate our topological characterization of DNNs is effective in estimating task similarity. Lastly, we show we can induce learning in DNNs by actively constraining the DNN's topological structure. This opens up new avenues in constricting the underlying structure of DNNs in a meta-learning framework.
Diamond in the rough: Improving image realism by traversing the GAN latent space
Apr 12, 2021
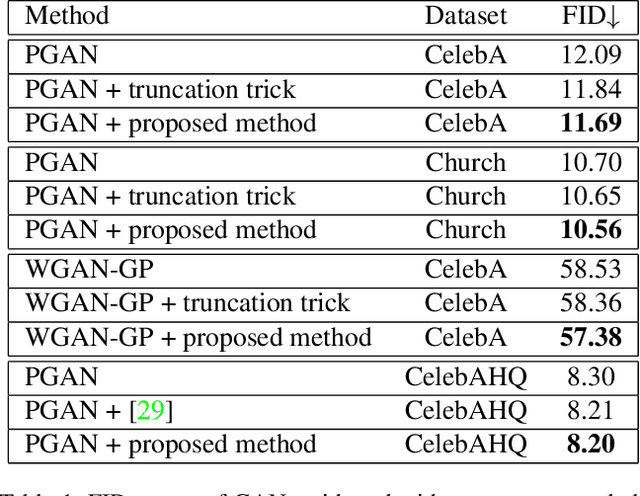
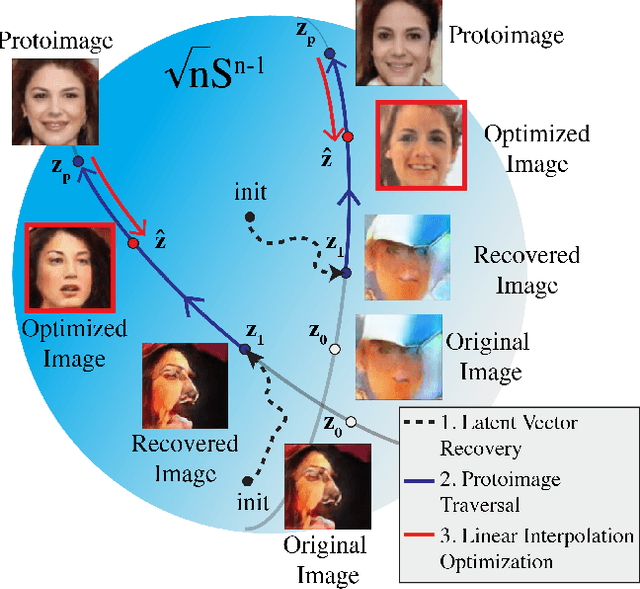
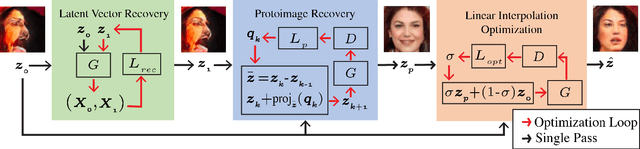
In just a few years, the photo-realism of images synthesized by Generative Adversarial Networks (GANs) has gone from somewhat reasonable to almost perfect largely by increasing the complexity of the networks, e.g., adding layers, intermediate latent spaces, style-transfer parameters, etc. This trajectory has led many of the state-of-the-art GANs to be inaccessibly large, disengaging many without large computational resources. Recognizing this, we explore a method for squeezing additional performance from existing, low-complexity GANs. Formally, we present an unsupervised method to find a direction in the latent space that aligns with improved photo-realism. Our approach leaves the network unchanged while enhancing the fidelity of the generated image. We use a simple generator inversion to find the direction in the latent space that results in the smallest change in the image space. Leveraging the learned structure of the latent space, we find moving in this direction corrects many image artifacts and brings the image into greater realism. We verify our findings qualitatively and quantitatively, showing an improvement in Frechet Inception Distance (FID) exists along our trajectory which surpasses the original GAN and other approaches including a supervised method. We expand further and provide an optimization method to automatically select latent vectors along the path that balance the variation and realism of samples. We apply our method to several diverse datasets and three architectures of varying complexity to illustrate the generalizability of our approach. By expanding the utility of low-complexity and existing networks, we hope to encourage the democratization of GANs.