 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding Knowledge to Unsupervised Algorithms for the Recognition of Intent
Paper and Code
Nov 12, 2020
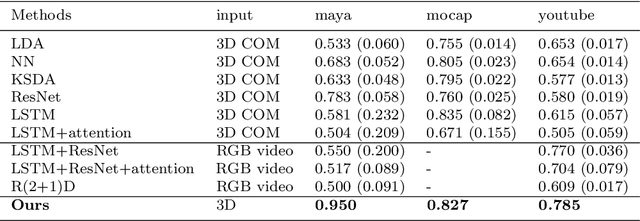
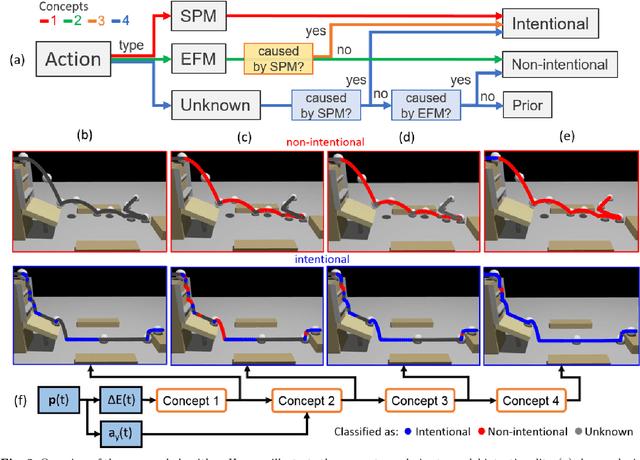

Computer vision algorithms performance are near or superior to humans in the visual problems including object recognition (especially those of fine-grained categories), segmentation, and 3D object reconstruction from 2D views. Humans are, however, capable of higher-level image analyses. A clear example, involving theory of mind, is our ability to determine whether a perceived behavior or action was performed intentionally or not. In this paper, we derive an algorithm that can infer whether the behavior of an agent in a scene is intentional or unintentional based on its 3D kinematics, using the knowledge of self-propelled motion, Newtonian motion and their relationship. We show how the addition of this basic knowledge leads to a simple, unsupervised algorithm. To test the derived algorithm, we constructed three dedicated datasets from abstract geometric animation to realistic videos of agents performing intentional and non-intentional actions. Experiments on these datasets show that our algorithm can recognize whether an action is intentional or not, even without training data. The performance is comparable to various supervised baselines quantitatively, with sensible intentionality segmentation qualitatively.