 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossmodal Knowledge Distillation with WordNet-Relaxed Text Embeddings for Robust Image Classification
Mar 31, 2025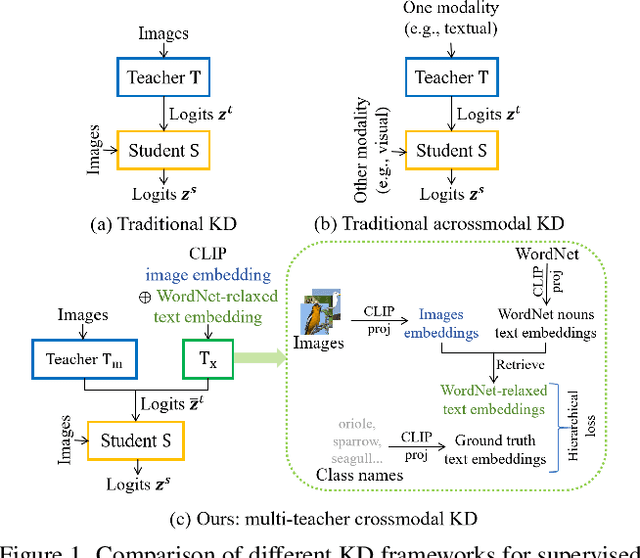
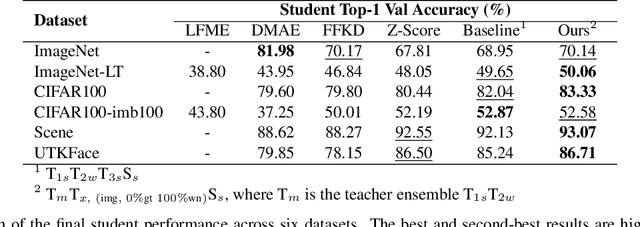
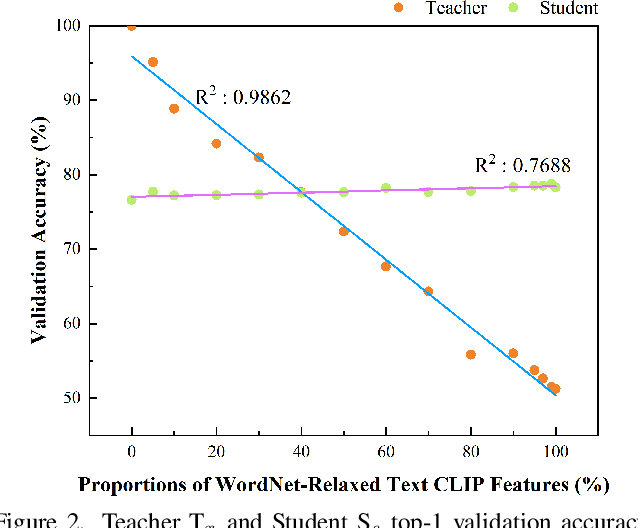
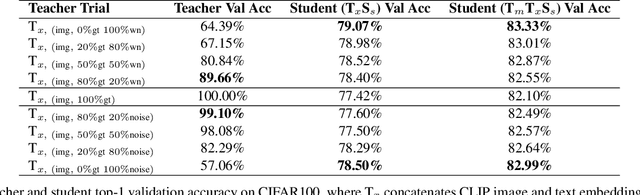
Crossmodal knowledge distillation (KD) aims to enhance a unimodal student using a multimodal teacher model. In particular, when the teacher's modalities include the student's, additional complementary information can be exploited to improve knowledge transfer. In supervised image classification, image datasets typically include class labels that represent high-level concepts, suggesting a natural avenue to incorporate textual cues for crossmodal KD. However, these labels rarely capture the deeper semantic structures in real-world visuals and can lead to label leakage if used directly as inputs, ultimately limiting KD performance. To address these issues, we propose a multi-teacher crossmodal KD framework that integrates CLIP image embeddings with learnable WordNet-relaxed text embeddings under a hierarchical loss. By avoiding direct use of exact class names and instead using semantically richer WordNet expansions, we mitigate label leakage and introduce more diverse textual cues. Experiments show that this strategy significantly boosts student performance, whereas noisy or overly precise text embeddings hinder distillation efficiency. Interpretability analyses confirm that WordNet-relaxed prompts encourage heavier reliance on visual features over textual shortcuts, while still effectively incorporating the newly introduced textual cues. Our method achieves state-of-the-art or second-best results on six public datasets, demonstrating its effectiveness in advancing crossmodal KD.
Why does Knowledge Distillation Work? Rethink its Attention and Fidelity Mechanism
Apr 30, 2024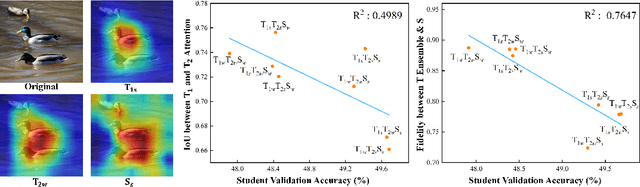
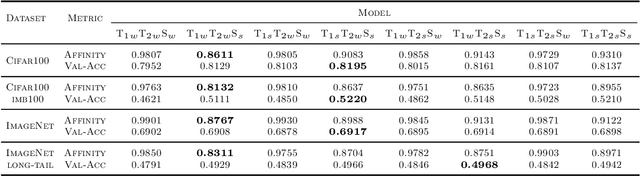
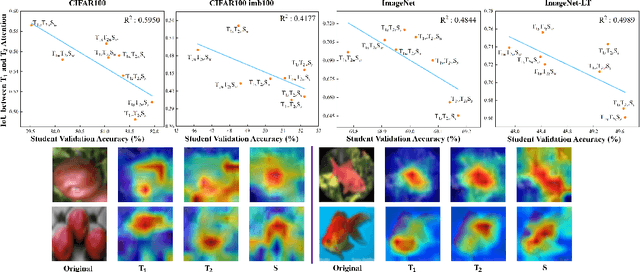
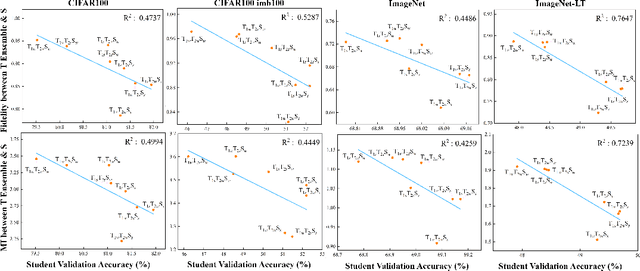
Does Knowledge Distillation (KD) really work? Conventional wisdom viewed it as a knowledge transfer procedure where a perfect mimicry of the student to its teacher is desired. However, paradoxical studies indicate that closely replicating the teacher's behavior does not consistently improve student generalization, posing questions on its possible causes. Confronted with this gap, we hypothesize that diverse attentions in teachers contribute to better student generalization at the expense of reduced fidelity in ensemble KD setups. By increasing data augmentation strengths, our key findings reveal a decrease in the Intersection over Union (IoU) of attentions between teacher models, leading to reduced student overfitting and decreased fidelity. We propose this low-fidelity phenomenon as an underlying characteristic rather than a pathology when training KD. This suggests that stronger data augmentation fosters a broader perspective provided by the divergent teacher ensemble and lower student-teacher mutual information, benefiting generalization performance. These insights clarify the mechanism on low-fidelity phenomenon in KD. Thus, we offer new perspectives on optimizing student model performance, by emphasizing increased diversity in teacher attentions and reduced mimicry behavior between teachers and student.
CEIL: A General Classification-Enhanced Iterative Learning Framework for Text Clustering
Apr 20, 2023
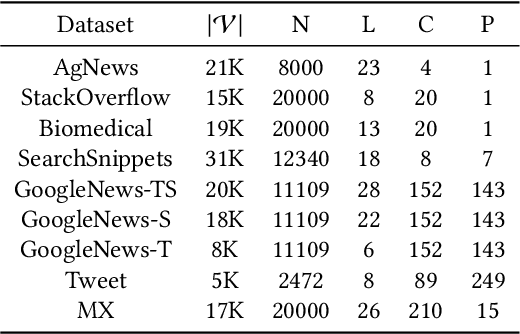

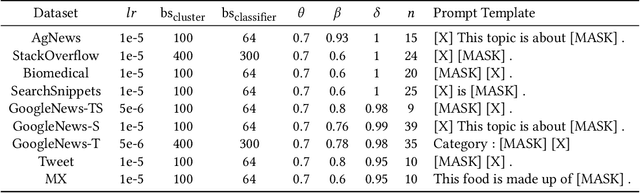
Text clustering, as one of the most fundamental challenges in unsupervised learning, aims at grouping semantically similar text segments without relying on human annotations. With the rapid development of deep learning, deep clustering has achieved significant advantages over traditional clustering methods. Despite the effectiveness, most existing deep text clustering methods rely heavily on representations pre-trained in general domains, which may not be the most suitable solution for clustering in specific target domains. To address this issue, we propose CEIL, a novel Classification-Enhanced Iterative Learning framework for short text clustering, which aims at generally promoting the clustering performance by introducing a classification objective to iteratively improve feature representations. In each iteration, we first adopt a language model to retrieve the initial text representations, from which the clustering results are collected using our proposed Category Disentangled Contrastive Clustering (CDCC) algorithm. After strict data filtering and aggregation processes, samples with clean category labels are retrieved, which serve as supervision information to update the language model with the classification objective via a prompt learning approach. Finally, the updated language model with improved representation ability is used to enhance clustering in the next iteration. Extensive experiments demonstrate that the CEIL framework significantly improves the clustering performance over iterations, and is generally effective on various clustering algorithms. Moreover, by incorporating CEIL on CDCC, we achieve the state-of-the-art clustering performance on a wide range of short text clustering benchmarks outperforming other strong baseline methods.
HFT-ONLSTM: Hierarchical and Fine-Tuning Multi-label Text Classification
Apr 18, 2022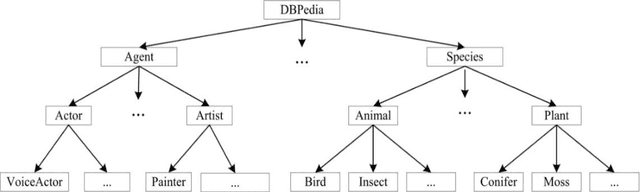
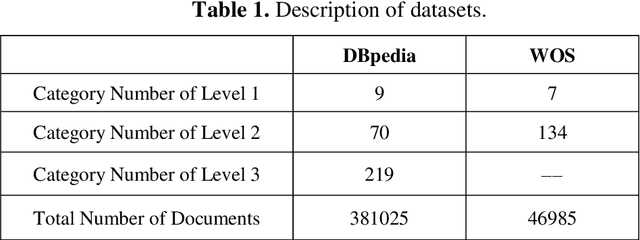
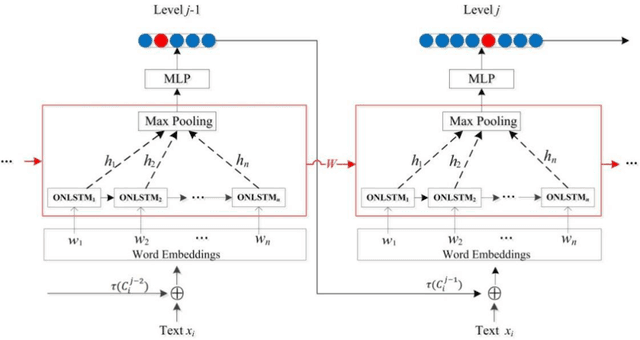
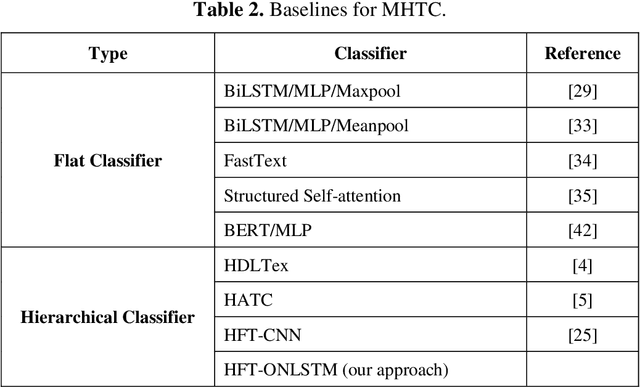
Many important classification problems in the real-world consist of a large number of closely related categories in a hierarchical structure or taxonomy. Hierarchical multi-label text classification (HMTC) with higher accuracy over large sets of closely related categories organized in a hierarchy or taxonomy has become a challenging problem. In this paper, we present a hierarchical and fine-tuning approach based on the Ordered Neural LSTM neural network, abbreviated as HFT-ONLSTM, for more accurate level-by-level HMTC. First, we present a novel approach to learning the joint embeddings based on parent category labels and textual data for accurately capturing the joint features of both category labels and texts. Second, a fine tuning technique is adopted for training parameters such that the text classification results in the upper level should contribute to the classification in the lower one. At last, the comprehensive analysis is made based on extensive experiments in comparison with the state-of-the-art hierarchical and flat multi-label text classification approaches over two benchmark datasets, and the experimental results show that our HFT-ONLSTM approach outperforms these approaches, in particular reducing computational costs while achieving superior performance.
A Hierarchical Fine-Tuning Approach Based on Joint Embedding of Words and Parent Categories for Hierarchical Multi-label Text Classification
Apr 06, 2020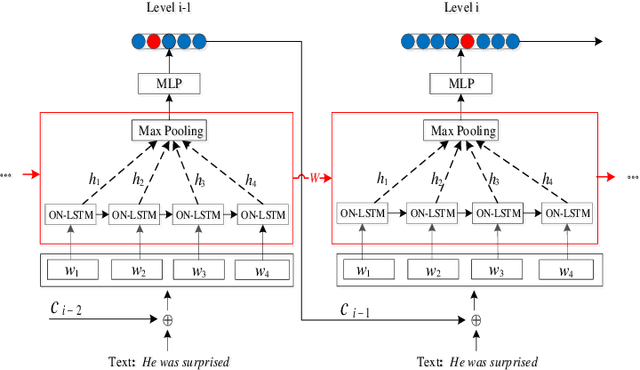
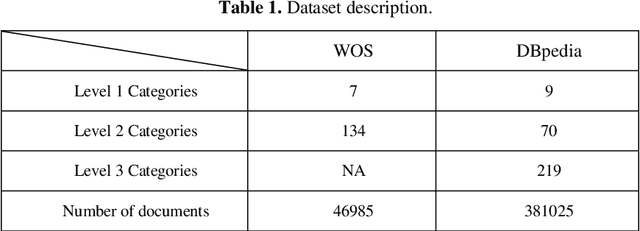
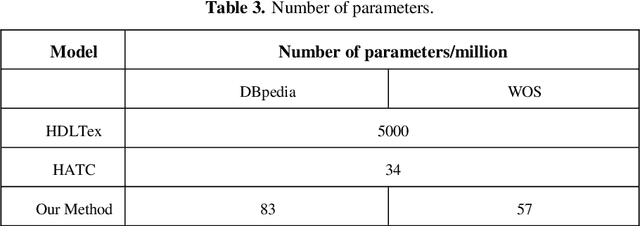
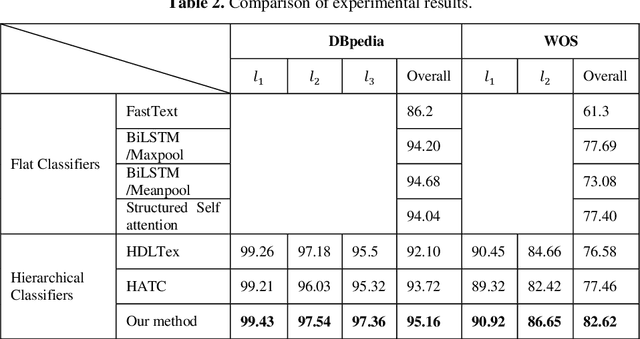
Many important classification problems in real world consist of a large number of categories. Hierarchical multi-label text classification (HMTC) with higher accuracy over large sets of closely related categories organized in a hierarchical structure or taxonomy has become a challenging problem. In this paper, we present a hierarchical fine-tuning deep learning approach for HMTC. A joint embedding approach of words and parent category are utilized by leveraging the hierarchical relations in the hierarchical structure of categories and the textual data. A fine tuning technique is applied to the Ordered Neural LSTM (ONLSTM) neural network such that the text classification results in the upper levels should contribute to the classification in the lower ones. The extensive experiments were made over two benchmark datasets, and the results show that the method proposed in this paper outperforms the state-of-the-art hierarchical and flat multi-label text classification approaches at significantly lower compu-tational cost while maintaining high interpretability.
An Efficient Approach to Learning Chinese Judgment Document Similarity Based on Knowledge Summarization
Aug 06, 2018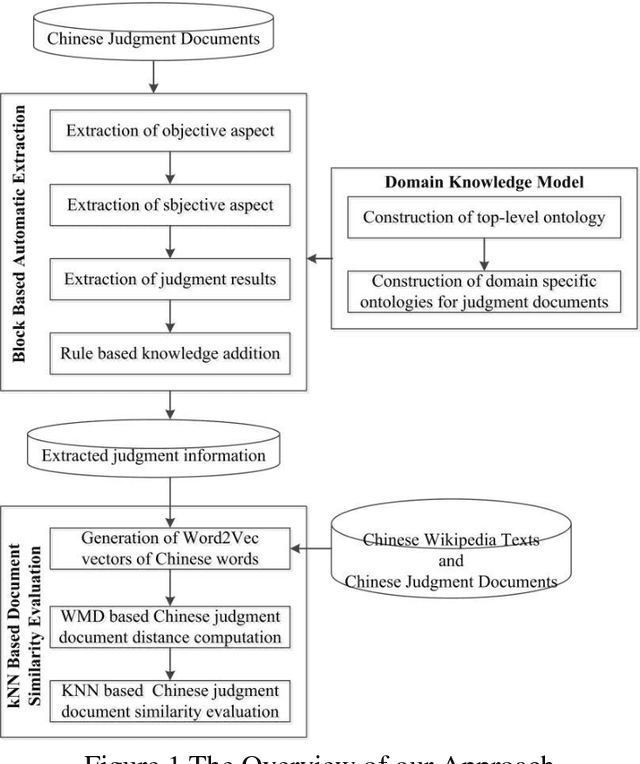



A previous similar case in common law systems can be used as a reference with respect to the current case such that identical situations can be treated similarly in every case. However, current approaches for judgment document similarity computation failed to capture the core semantics of judgment documents and therefore suffer from lower accuracy and higher computation complexity. In this paper, a knowledge block summarization based machine learning approach is proposed to compute the semantic similarity of Chinese judgment documents. By utilizing domain ontologies for judgment documents, the core semantics of Chinese judgment documents is summarized based on knowledge blocks. Then the WMD algorithm is used to calculate the similarity between knowledge blocks. At last, the related experiments were made to illustrate that our approach is very effective and efficient in achieving higher accuracy and faster computation speed in comparison with the traditional approaches.