 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEIL: A General Classification-Enhanced Iterative Learning Framework for Text Clustering
Apr 20, 2023
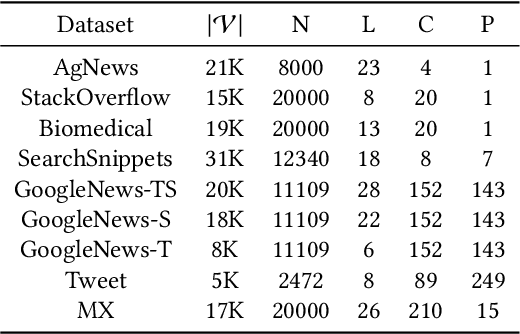

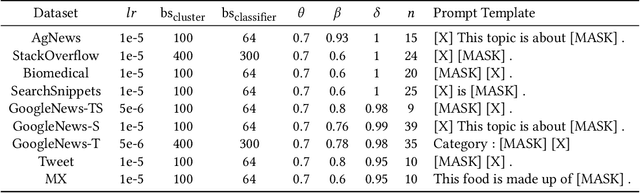
Text clustering, as one of the most fundamental challenges in unsupervised learning, aims at grouping semantically similar text segments without relying on human annotations. With the rapid development of deep learning, deep clustering has achieved significant advantages over traditional clustering methods. Despite the effectiveness, most existing deep text clustering methods rely heavily on representations pre-trained in general domains, which may not be the most suitable solution for clustering in specific target domains. To address this issue, we propose CEIL, a novel Classification-Enhanced Iterative Learning framework for short text clustering, which aims at generally promoting the clustering performance by introducing a classification objective to iteratively improve feature representations. In each iteration, we first adopt a language model to retrieve the initial text representations, from which the clustering results are collected using our proposed Category Disentangled Contrastive Clustering (CDCC) algorithm. After strict data filtering and aggregation processes, samples with clean category labels are retrieved, which serve as supervision information to update the language model with the classification objective via a prompt learning approach. Finally, the updated language model with improved representation ability is used to enhance clustering in the next iteration. Extensive experiments demonstrate that the CEIL framework significantly improves the clustering performance over iterations, and is generally effective on various clustering algorithms. Moreover, by incorporating CEIL on CDCC, we achieve the state-of-the-art clustering performance on a wide range of short text clustering benchmarks outperforming other strong baseline methods.
Verdi: Quality Estimation and Error Detection for Bilingual
May 31, 2021
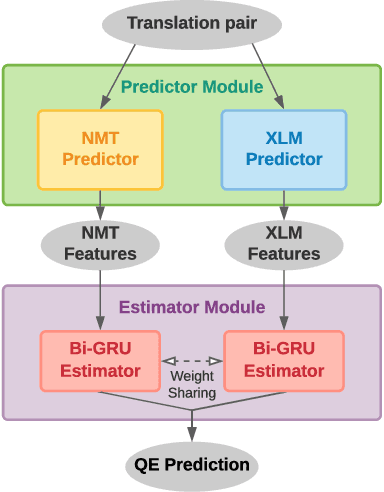
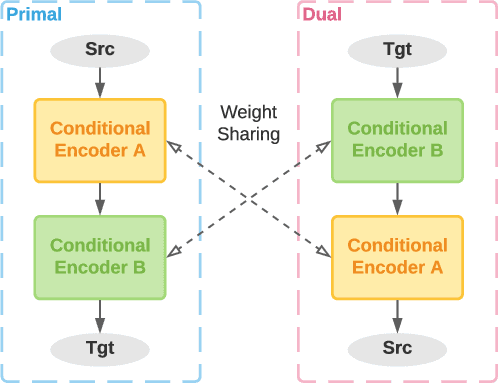

Translation Quality Estimation is critical to reducing post-editing efforts in machine translation and to cross-lingual corpus cleaning. As a research problem, quality estimation (QE) aims to directly estimate the quality of translation in a given pair of source and target sentences, and highlight the words that need corrections, without referencing to golden translations. In this paper, we propose Verdi, a novel framework for word-level and sentence-level post-editing effort estimation for bilingual corpora. Verdi adopts two word predictors to enable diverse features to be extracted from a pair of sentences for subsequent quality estimation, including a transformer-based neural machine translation (NMT) model and a pre-trained cross-lingual language model (XLM). We exploit the symmetric nature of bilingual corpora and apply model-level dual learning in the NMT predictor, which handles a primal task and a dual task simultaneously with weight sharing, leading to stronger context prediction ability than single-direction NMT models. By taking advantage of the dual learning scheme, we further design a novel feature to directly encode the translated target information without relying on the source context. Extensive experiments conducted on WMT20 QE tasks demonstrate that our method beats the winner of the competition and outperforms other baseline methods by a great margin. We further use the sentence-level scores provided by Verdi to clean a parallel corpus and observe benefits on both model performance and training efficiency.
Reinforced Curriculum Learning on Pre-trained Neural Machine Translation Models
Apr 13, 2020
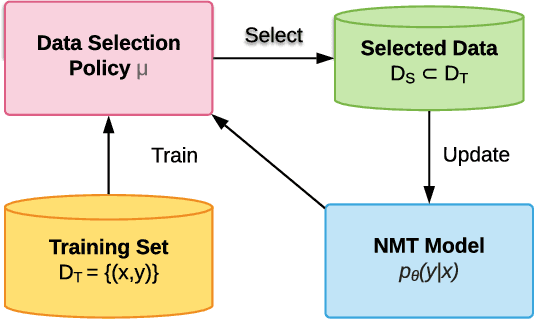
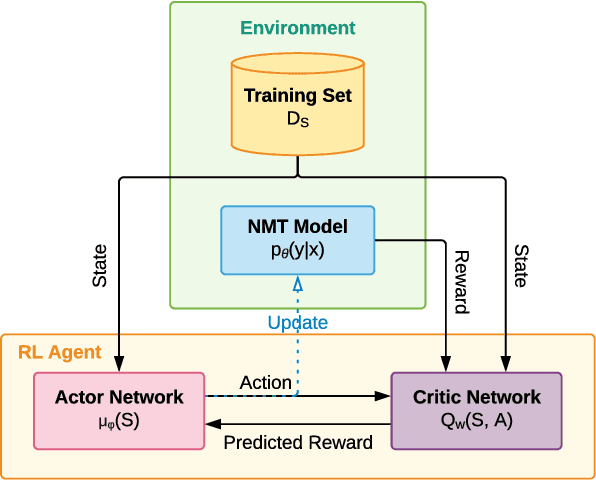
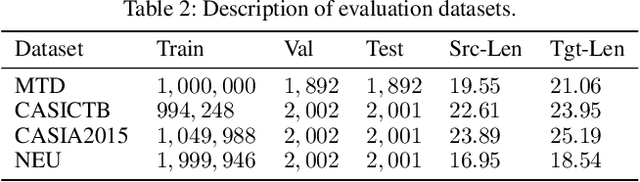
The competitive performance of neural machine translation (NMT) critically relies on large amounts of training data. However, acquiring high-quality translation pairs requires expert knowledge and is costly. Therefore, how to best utilize a given dataset of samples with diverse quality and characteristics becomes an important yet understudied question in NMT. Curriculum learning methods have been introduced to NMT to optimize a model's performance by prescribing the data input order, based on heuristics such as the assessment of noise and difficulty levels. However, existing methods require training from scratch, while in practice most NMT models are pre-trained on big data already. Moreover, as heuristics, they do not generalize well. In this paper, we aim to learn a curriculum for improving a pre-trained NMT model by re-selecting influential data samples from the original training set and formulate this task as a reinforcement learning problem. Specifically, we propose a data selection framework based on Deterministic Actor-Critic, in which a critic network predicts the expected change of model performance due to a certain sample, while an actor network learns to select the best sample out of a random batch of samples presented to it. Experiments on several translation datasets show that our method can further improve the performance of NMT when original batch training reaches its ceiling, without using additional new training data, and significantly outperforms several strong baseline methods.