 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConKI: Contrastive Knowledge Injection for Multimodal Sentiment Analysis
Jun 27, 2023



Multimodal Sentiment Analysis leverages multimodal signals to detect the sentiment of a speaker. Previous approaches concentrate on performing multimodal fusion and representation learning based on general knowledge obtained from pretrained models, which neglects the effect of domain-specific knowledge. In this paper, we propose Contrastive Knowledge Injection (ConKI) for multimodal sentiment analysis, where specific-knowledge representations for each modality can be learned together with general knowledge representations via knowledge injection based on an adapter architecture. In addition, ConKI uses a hierarchical contrastive learning procedure performed between knowledge types within every single modality, across modalities within each sample, and across samples to facilitate the effective learning of the proposed representations, hence improving multimodal sentiment predictions. The experiments on three popular multimodal sentiment analysis benchmarks show that ConKI outperforms all prior methods on a variety of performance metrics.
LA3: Efficient Label-Aware AutoAugment
Apr 20, 2023Automated augmentation is an emerging and effective technique to search for data augmentation policies to improve generalizability of deep neural network training. Most existing work focuses on constructing a unified policy applicable to all data samples in a given dataset, without considering sample or class variations. In this paper, we propose a novel two-stage data augmentation algorithm, named Label-Aware AutoAugment (LA3), which takes advantage of the label information, and learns augmentation policies separately for samples of different labels. LA3 consists of two learning stages, where in the first stage, individual augmentation methods are evaluated and ranked for each label via Bayesian Optimization aided by a neural predictor, which allows us to identify effective augmentation techniques for each label under a low search cost. And in the second stage, a composite augmentation policy is constructed out of a selection of effective as well as complementary augmentations, which produces significant performance boost and can be easily deployed in typical model training. Extensive experiments demonstrate that LA3 achieves excellent performance matching or surpassing existing methods on CIFAR-10 and CIFAR-100, and achieves a new state-of-the-art ImageNet accuracy of 79.97% on ResNet-50 among auto-augmentation methods, while maintaining a low computational cost.
Search-Map-Search: A Frame Selection Paradigm for Action Recognition
Apr 20, 2023



Despite the success of deep learning in video understanding tasks, processing every frame in a video is computationally expensive and often unnecessary in real-time applications. Frame selection aims to extract the most informative and representative frames to help a model better understand video content. Existing frame selection methods either individually sample frames based on per-frame importance prediction, without considering interaction among frames, or adopt reinforcement learning agents to find representative frames in succession, which are costly to train and may lead to potential stability issues. To overcome the limitations of existing methods, we propose a Search-Map-Search learning paradigm which combines the advantages of heuristic search and supervised learning to select the best combination of frames from a video as one entity. By combining search with learning, the proposed method can better capture frame interactions while incurring a low inference overhead. Specifically, we first propose a hierarchical search method conducted on each training video to search for the optimal combination of frames with the lowest error on the downstream task. A feature mapping function is then learned to map the frames of a video to the representation of its target optimal frame combination. During inference, another search is performed on an unseen video to select a combination of frames whose feature representation is close to the projected feature representation. Extensive experiments based on several action recognition benchmarks demonstrate that our frame selection method effectively improves performance of action recognition models, and significantly outperforms a number of competitive baselines.
CEIL: A General Classification-Enhanced Iterative Learning Framework for Text Clustering
Apr 20, 2023
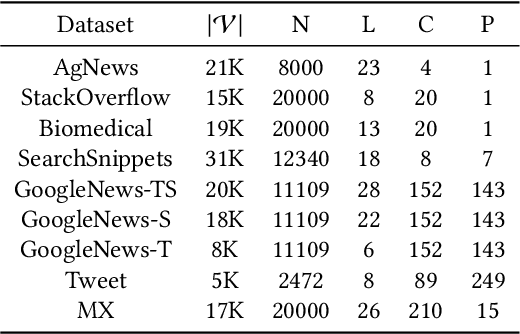

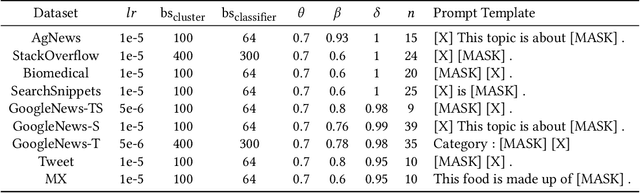
Text clustering, as one of the most fundamental challenges in unsupervised learning, aims at grouping semantically similar text segments without relying on human annotations. With the rapid development of deep learning, deep clustering has achieved significant advantages over traditional clustering methods. Despite the effectiveness, most existing deep text clustering methods rely heavily on representations pre-trained in general domains, which may not be the most suitable solution for clustering in specific target domains. To address this issue, we propose CEIL, a novel Classification-Enhanced Iterative Learning framework for short text clustering, which aims at generally promoting the clustering performance by introducing a classification objective to iteratively improve feature representations. In each iteration, we first adopt a language model to retrieve the initial text representations, from which the clustering results are collected using our proposed Category Disentangled Contrastive Clustering (CDCC) algorithm. After strict data filtering and aggregation processes, samples with clean category labels are retrieved, which serve as supervision information to update the language model with the classification objective via a prompt learning approach. Finally, the updated language model with improved representation ability is used to enhance clustering in the next iteration. Extensive experiments demonstrate that the CEIL framework significantly improves the clustering performance over iterations, and is generally effective on various clustering algorithms. Moreover, by incorporating CEIL on CDCC, we achieve the state-of-the-art clustering performance on a wide range of short text clustering benchmarks outperforming other strong baseline methods.
GlyphDraw: Learning to Draw Chinese Characters in Image Synthesis Models Coherently
Mar 31, 2023



Recent breakthroughs in the field of language-guided image generation have yielded impressive achievements, enabling the creation of high-quality and diverse images based on user instructions. Although the synthesis performance is fascinating, one significant limitation of current image generation models is their insufficient ability to generate coherent text within images, particularly for complex glyph structures like Chinese characters. To address this problem, we introduce GlyphDraw, a general learning framework aiming at endowing image generation models with the capacity to generate images embedded with coherent text. To the best of our knowledge, this is the first work in the field of image synthesis to address the generation of Chinese characters. % we first adopt the OCR technique to collect images with Chinese characters as training samples, and extract the text and locations as auxiliary information. We first sophisticatedly design the image-text dataset's construction strategy, then build our model specifically on a diffusion-based image generator and carefully modify the network structure to allow the model to learn drawing Chinese characters with the help of glyph and position information. Furthermore, we maintain the model's open-domain image synthesis capability by preventing catastrophic forgetting by using a variety of training techniques. Extensive qualitative and quantitative experiments demonstrate that our method not only produces accurate Chinese characters as in prompts, but also naturally blends the generated text into the background. Please refer to https://1073521013.github.io/glyph-draw.github.io
RecGURU: Adversarial Learning of Generalized User Representations for Cross-Domain Recommendation
Nov 19, 2021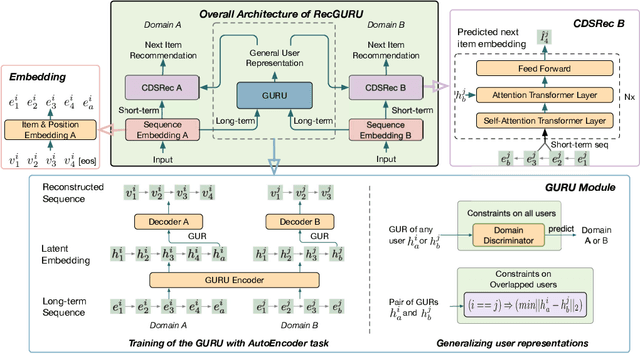
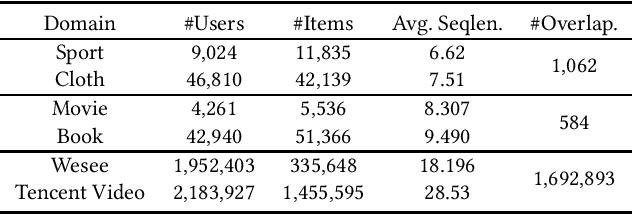
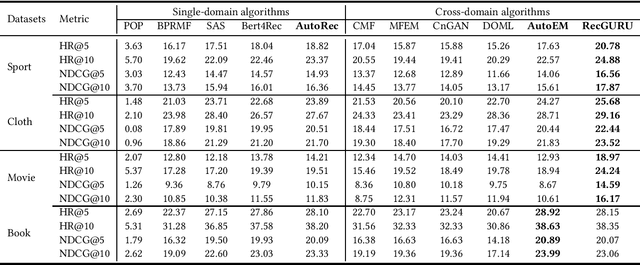
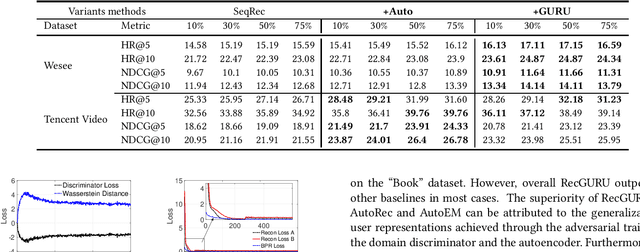
Cross-domain recommendation can help alleviate the data sparsity issue in traditional sequential recommender systems. In this paper, we propose the RecGURU algorithm framework to generate a Generalized User Representation (GUR) incorporating user information across domains in sequential recommendation, even when there is minimum or no common users in the two domains. We propose a self-attentive autoencoder to derive latent user representations, and a domain discriminator, which aims to predict the origin domain of a generated latent representation. We propose a novel adversarial learning method to train the two modules to unify user embeddings generated from different domains into a single global GUR for each user. The learned GUR captures the overall preferences and characteristics of a user and thus can be used to augment the behavior data and improve recommendations in any single domain in which the user is involved. Extensive experiments have been conducted on two public cross-domain recommendation datasets as well as a large dataset collected from real-world applications. The results demonstrate that RecGURU boosts performance and outperforms various state-of-the-art sequential recommendation and cross-domain recommendation methods. The collected data will be released to facilitate future research.
LICHEE: Improving Language Model Pre-training with Multi-grained Tokenization
Aug 03, 2021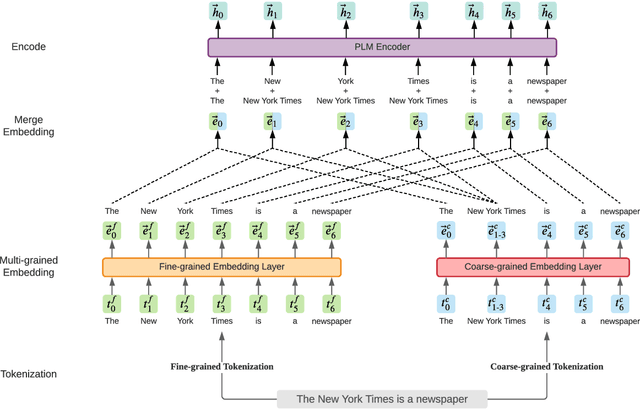
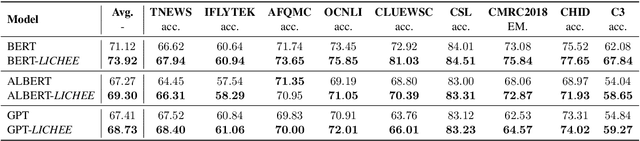
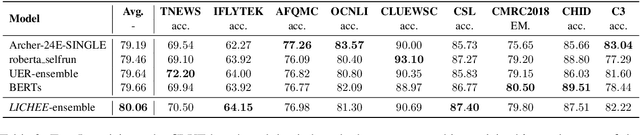
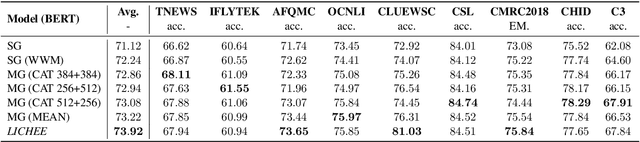
Language model pre-training based on large corpora has achieved tremendous success in terms of constructing enriched contextual representations and has led to significant performance gains on a diverse range of Natural Language Understanding (NLU) tasks. Despite the success, most current pre-trained language models, such as BERT, are trained based on single-grained tokenization, usually with fine-grained characters or sub-words, making it hard for them to learn the precise meaning of coarse-grained words and phrases. In this paper, we propose a simple yet effective pre-training method named LICHEE to efficiently incorporate multi-grained information of input text. Our method can be applied to various pre-trained language models and improve their representation capability. Extensive experiments conducted on CLUE and SuperGLUE demonstrate that our method achieves comprehensive improvements on a wide variety of NLU tasks in both Chinese and English with little extra inference cost incurred, and that our best ensemble model achieves the state-of-the-art performance on CLUE benchmark competition.
Verdi: Quality Estimation and Error Detection for Bilingual
May 31, 2021
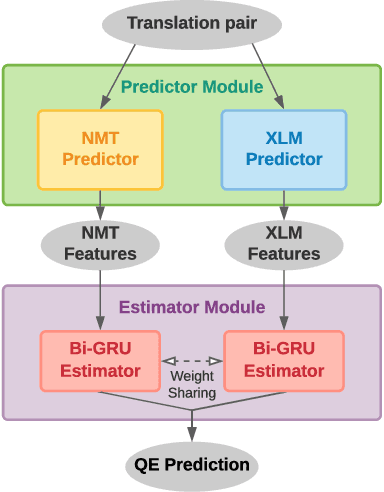
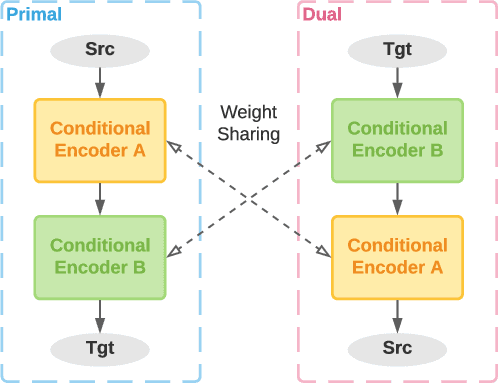

Translation Quality Estimation is critical to reducing post-editing efforts in machine translation and to cross-lingual corpus cleaning. As a research problem, quality estimation (QE) aims to directly estimate the quality of translation in a given pair of source and target sentences, and highlight the words that need corrections, without referencing to golden translations. In this paper, we propose Verdi, a novel framework for word-level and sentence-level post-editing effort estimation for bilingual corpora. Verdi adopts two word predictors to enable diverse features to be extracted from a pair of sentences for subsequent quality estimation, including a transformer-based neural machine translation (NMT) model and a pre-trained cross-lingual language model (XLM). We exploit the symmetric nature of bilingual corpora and apply model-level dual learning in the NMT predictor, which handles a primal task and a dual task simultaneously with weight sharing, leading to stronger context prediction ability than single-direction NMT models. By taking advantage of the dual learning scheme, we further design a novel feature to directly encode the translated target information without relying on the source context. Extensive experiments conducted on WMT20 QE tasks demonstrate that our method beats the winner of the competition and outperforms other baseline methods by a great margin. We further use the sentence-level scores provided by Verdi to clean a parallel corpus and observe benefits on both model performance and training efficiency.
QBSUM: a Large-Scale Query-Based Document Summarization Dataset from Real-world Applications
Oct 28, 2020
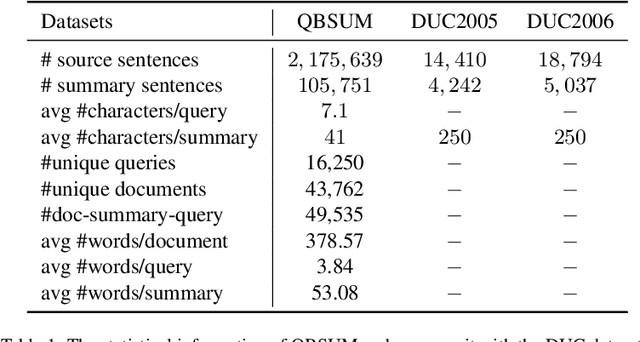
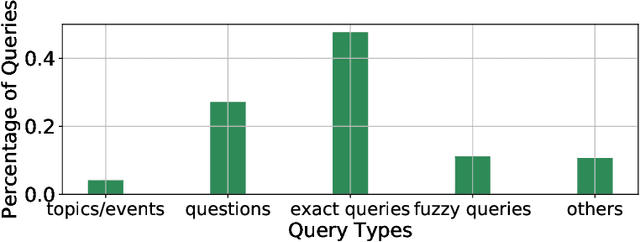

Query-based document summarization aims to extract or generate a summary of a document which directly answers or is relevant to the search query. It is an important technique that can be beneficial to a variety of applications such as search engines, document-level machine reading comprehension, and chatbots. Currently, datasets designed for query-based summarization are short in numbers and existing datasets are also limited in both scale and quality. Moreover, to the best of our knowledge, there is no publicly available dataset for Chinese query-based document summarization. In this paper, we present QBSUM, a high-quality large-scale dataset consisting of 49,000+ data samples for the task of Chinese query-based document summarization. We also propose multiple unsupervised and supervised solutions to the task and demonstrate their high-speed inference and superior performance via both offline experiments and online A/B tests. The QBSUM dataset is released in order to facilitate future advancement of this research field.
Reinforced Curriculum Learning on Pre-trained Neural Machine Translation Models
Apr 13, 2020
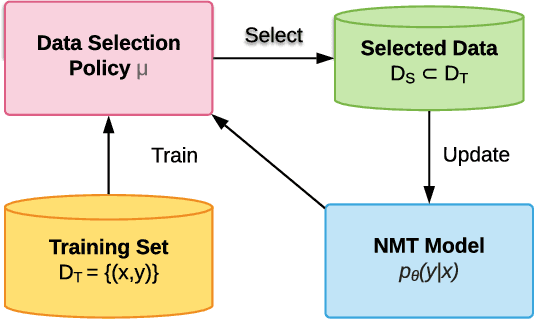
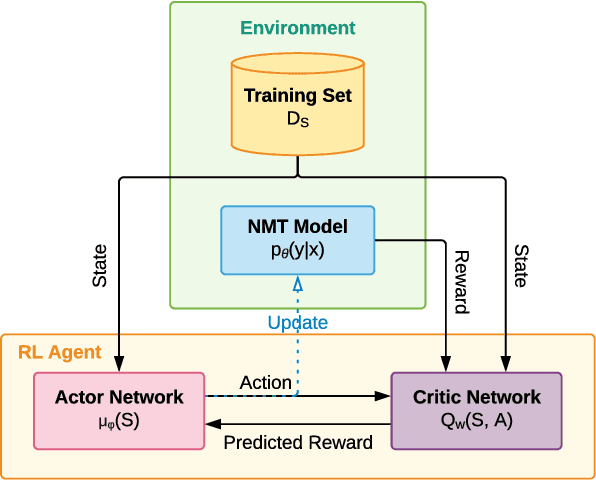
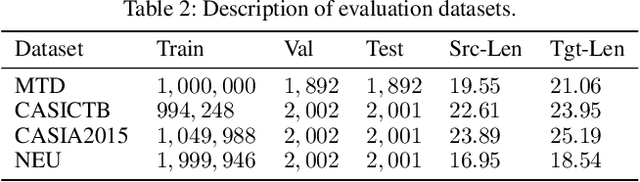
The competitive performance of neural machine translation (NMT) critically relies on large amounts of training data. However, acquiring high-quality translation pairs requires expert knowledge and is costly. Therefore, how to best utilize a given dataset of samples with diverse quality and characteristics becomes an important yet understudied question in NMT. Curriculum learning methods have been introduced to NMT to optimize a model's performance by prescribing the data input order, based on heuristics such as the assessment of noise and difficulty levels. However, existing methods require training from scratch, while in practice most NMT models are pre-trained on big data already. Moreover, as heuristics, they do not generalize well. In this paper, we aim to learn a curriculum for improving a pre-trained NMT model by re-selecting influential data samples from the original training set and formulate this task as a reinforcement learning problem. Specifically, we propose a data selection framework based on Deterministic Actor-Critic, in which a critic network predicts the expected change of model performance due to a certain sample, while an actor network learns to select the best sample out of a random batch of samples presented to it. Experiments on several translation datasets show that our method can further improve the performance of NMT when original batch training reaches its ceiling, without using additional new training data, and significantly outperforms several strong baseline methods.