 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-inspired Graph Spiking Neural Networks for Commonsense Knowledge Representation and Reasoning
Jul 11, 2022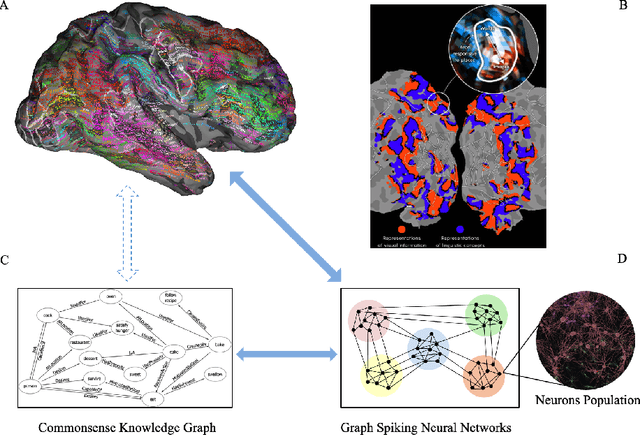
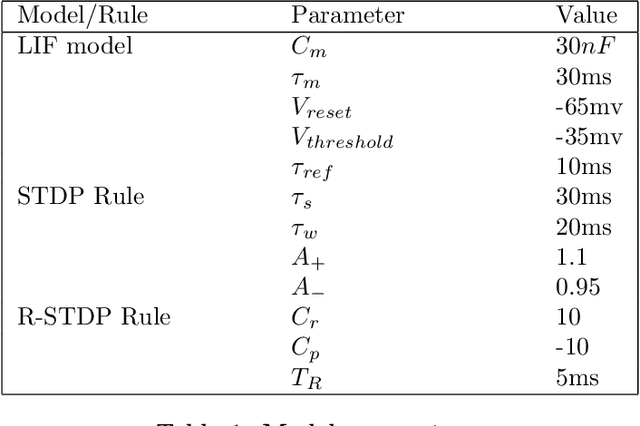
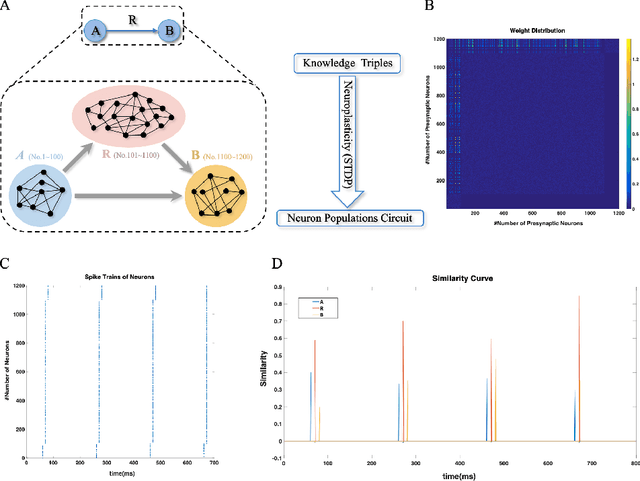
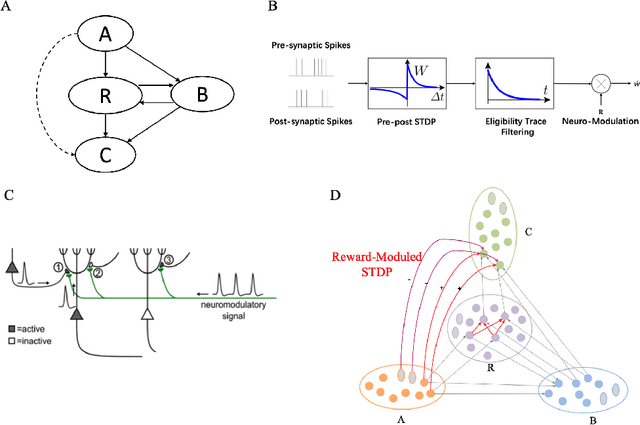
How neural networks in the human brain represent commonsense knowledge, and complete related reasoning tasks is an important research topic in neuroscience, cognitive science, psychology, and artificial intelligence. Although the traditional artificial neural network using fixed-length vectors to represent symbols has gained good performance in some specific tasks, it is still a black box that lacks interpretability, far from how humans perceive the world. Inspired by the grandmother-cell hypothesis in neuroscience, this work investigates how population encoding and spiking timing-dependent plasticity (STDP) mechanisms can be integrated into the learning of spiking neural networks, and how a population of neurons can represent a symbol via guiding the completion of sequential firing between different neuron populations. The neuron populations of different communities together constitute the entire commonsense knowledge graph, forming a giant graph spiking neural network. Moreover, we introduced the Reward-modulated spiking timing-dependent plasticity (R-STDP) mechanism to simulate the biological reinforcement learning process and completed the related reasoning tasks accordingly, achieving comparable accuracy and faster convergence speed than the graph convolutional artificial neural networks. For the fields of neuroscience and cognitive science, the work in this paper provided the foundation of computational modeling for further exploration of the way the human brain represents commonsense knowledge. For the field of artificial intelligence, this paper indicated the exploration direction for realizing a more robust and interpretable neural network by constructing a commonsense knowledge representation and reasoning spiking neural networks with solid biological plausibility.
LICHEE: Improving Language Model Pre-training with Multi-grained Tokenization
Aug 03, 2021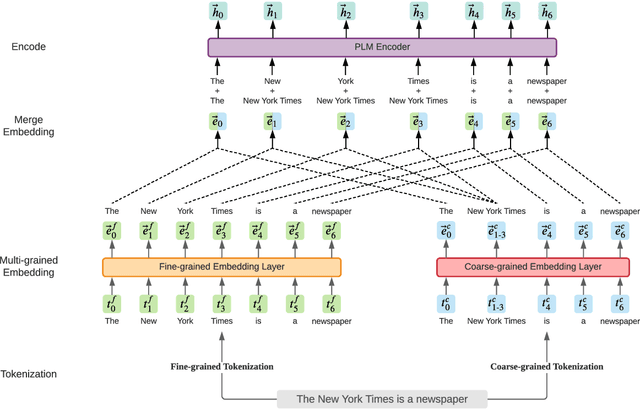
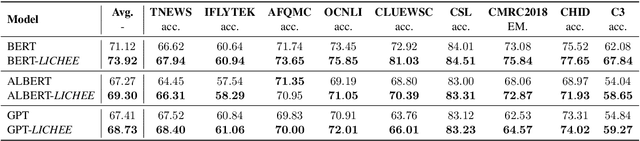
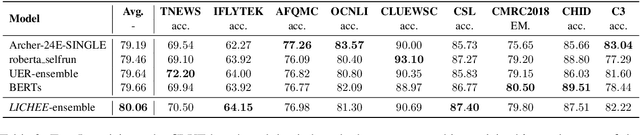
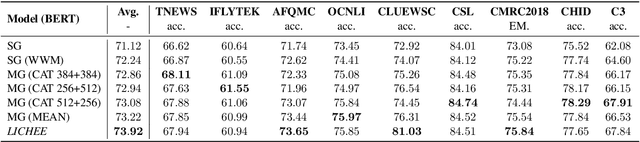
Language model pre-training based on large corpora has achieved tremendous success in terms of constructing enriched contextual representations and has led to significant performance gains on a diverse range of Natural Language Understanding (NLU) tasks. Despite the success, most current pre-trained language models, such as BERT, are trained based on single-grained tokenization, usually with fine-grained characters or sub-words, making it hard for them to learn the precise meaning of coarse-grained words and phrases. In this paper, we propose a simple yet effective pre-training method named LICHEE to efficiently incorporate multi-grained information of input text. Our method can be applied to various pre-trained language models and improve their representation capability. Extensive experiments conducted on CLUE and SuperGLUE demonstrate that our method achieves comprehensive improvements on a wide variety of NLU tasks in both Chinese and English with little extra inference cost incurred, and that our best ensemble model achieves the state-of-the-art performance on CLUE benchmark competition.