 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRec-Distill: An Industrial Distillation Pipeline for Large-Scale Recommendation Models
May 28, 2026Large recommendation models have demonstrated substantial potential gains under scaling laws, yet these gains are difficult to realize in industrial recommendation systems because real-world deployment requires lightweight models with strict serving efficiency and latency guarantees. This creates a fundamental gap between offline model scaling and online deployment. In this work, we present Rec-Distill, an industrial distillation pipeline that transfers the performance gains of large-scale recommendation modeling to efficient serving models. Rec-Distill combines large-teacher scaling with student-side transfer optimization through decoupled training, black-box distillation, debiasing mechanism, and a hybrid batch-streaming pipeline for dynamic recommendation environments. Across multiple recommendation and advertising scenarios on real-world platforms, our framework scales teacher models up to 24B dense parameters and 20K behavior sequence length, while enabling lightweight students to recover a substantial portion of teacher gains, with distillation transferability exceeding 60% in the best setting. Extensive offline and online experiments further show that these transferred gains consistently translate into measurable business improvements under industrial constraints. These results demonstrate that Rec-Distill provides a practical framework for distilling large-scale recommendation models into deployable, cost-efficient serving systems, while also establishing a reliable path toward scaling recommendation models to even larger regimes in the future.
Seeing is Believing: Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise
Apr 10, 2026Prompt learning is a parameter-efficient approach for vision-language models, yet its robustness under label noise is less investigated. Visual content contains richer and more reliable semantic information, which remains more robust under label noise. However, the prompt itself is highly susceptible to label noise. Motivated by this intuition, we propose VisPrompt, a lightweight and robust vision-guided prompt learning framework for noisy-label settings. Specifically, we exploit a cross-modal attention mechanism to reversely inject visual semantics into prompt representations. This enables the prompt tokens to selectively aggregate visual information relevant to the current sample, thereby improving robustness by anchoring prompt learning to stable instance-level visual evidence and reducing the influence of noisy supervision. To address the instability caused by using the same way of injecting visual information for all samples, despite differences in the quality of their visual cues, we further introduce a lightweight conditional modulation mechanism to adaptively control the strength of visual information injection, which strikes a more robust balance between text-side semantic priors and image-side instance evidence. The proposed framework effectively suppresses the noise-induced disturbances, reduce instability in prompt updates, and alleviate memorization of mislabeled samples. VisPrompt significantly improves robustness while keeping the pretrained VLM backbone frozen and introducing only a small amount of additional trainable parameters. Extensive experiments under synthetic and real-world label noise demonstrate that VisPrompt generally outperforms existing baselines on seven benchmark datasets and achieves stronger robustness. Our code is publicly available at https://github.com/gezbww/Vis_Prompt.
FedRG: Unleashing the Representation Geometry for Federated Learning with Noisy Clients
Mar 20, 2026Federated learning (FL) suffers from performance degradation due to the inevitable presence of noisy annotations in distributed scenarios. Existing approaches have advanced in distinguishing noisy samples from the dataset for label correction by leveraging loss values. However, noisy samples recognition relying on scalar loss lacks reliability for FL under heterogeneous scenarios. In this paper, we rethink this paradigm from a representation perspective and propose \method~(\textbf{Fed}erated under \textbf{R}epresentation \textbf{G}emometry), which follows \textbf{the principle of ``representation geometry priority''} to recognize noisy labels. Firstly, \method~creates label-agnostic spherical representations by using self-supervision. It then iteratively fits a spherical von Mises-Fisher (vMF) mixture model to this geometry using previously identified clean samples to capture semantic clusters. This geometric evidence is integrated with a semantic-label soft mapping mechanism to derive a distribution divergence between the label-free and annotated label-conditioned feature space, which robustly identifies noisy samples and updates the vMF mixture model with the newly separated clean dataset. Lastly, we employ an additional personalized noise absorption matrix on noisy labels to achieve robust optimization. Extensive experimental results demonstrate that \method~significantly outperforms state-of-the-art methods for FL with data heterogeneity under diverse noisy clients scenarios.
Beyond Unimodal Shortcuts: MLLMs as Cross-Modal Reasoners for Grounded Named Entity Recognition
Feb 04, 2026Grounded Multimodal Named Entity Recognition (GMNER) aims to extract text-based entities, assign them semantic categories, and ground them to corresponding visual regions. In this work, we explore the potential of Multimodal Large Language Models (MLLMs) to perform GMNER in an end-to-end manner, moving beyond their typical role as auxiliary tools within cascaded pipelines. Crucially, our investigation reveals a fundamental challenge: MLLMs exhibit $\textbf{modality bias}$, including visual bias and textual bias, which stems from their tendency to take unimodal shortcuts rather than rigorous cross-modal verification. To address this, we propose Modality-aware Consistency Reasoning ($\textbf{MCR}$), which enforces structured cross-modal reasoning through Multi-style Reasoning Schema Injection (MRSI) and Constraint-guided Verifiable Optimization (CVO). MRSI transforms abstract constraints into executable reasoning chains, while CVO empowers the model to dynamically align its reasoning trajectories with Group Relative Policy Optimization (GRPO). Experiments on GMNER and visual grounding tasks demonstrate that MCR effectively mitigates modality bias and achieves superior performance compared to existing baselines.
Seeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
Nov 14, 2025Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence. We will make all code, data, and trained models' weights publicly available.
Wireless Channel Foundation Model with Embedded Noise-Plus-Interference Suppression Structure
Sep 19, 2025Wireless channel foundation model (WCFM) is a task-agnostic AI model that is pretrained on large-scale wireless channel datasets to learn a universal channel feature representation that can be used for a wide range of downstream tasks related to communications and sensing. While existing works on WCFM have demonstrated its great potentials in various tasks including beam prediction, channel prediction, localization, etc, the models are all trained using perfect (i.e., error-free and complete) channel information state (CSI) data which are generated with simulation tools. However, in practical systems where the WCFM is deployed, perfect CSI is not available. Instead, channel estimation needs to be first performed based on pilot signals over a subset of the resource elements (REs) to acquire a noisy version of the CSI (termed as degraded CSI), which significantly differs from the perfect CSI in some real-world environments with severe noise and interference. As a result, the feature representation generated by the WCFM is unable to reflect the characteristics of the true channel, yielding performance degradation in downstream tasks. To address this issue, in this paper we propose an enhanced wireless channel foundation model architecture with noise-plus-interference (NPI) suppression capability. In our approach, coarse estimates of the CSIs are first obtained. With these information, two projection matrices are computed to extract the NPI terms in the received signals, which are further processed by a NPI estimation and subtraction module. Finally, the resultant signal is passed through a CSI completion network to get a clean version of the CSI, which is used for feature extraction. Simulation results demonstrated that compared to the state-of-the-art solutions, WCFM with NPI suppression structure achieves improved performance on channel prediction task.
MVPBench: A Benchmark and Fine-Tuning Framework for Aligning Large Language Models with Diverse Human Values
Sep 09, 2025The alignment of large language models (LLMs) with human values is critical for their safe and effective deployment across diverse user populations. However, existing benchmarks often neglect cultural and demographic diversity, leading to limited understanding of how value alignment generalizes globally. In this work, we introduce MVPBench, a novel benchmark that systematically evaluates LLMs' alignment with multi-dimensional human value preferences across 75 countries. MVPBench contains 24,020 high-quality instances annotated with fine-grained value labels, personalized questions, and rich demographic metadata, making it the most comprehensive resource of its kind to date. Using MVPBench, we conduct an in-depth analysis of several state-of-the-art LLMs, revealing substantial disparities in alignment performance across geographic and demographic lines. We further demonstrate that lightweight fine-tuning methods, such as Low-Rank Adaptation (LoRA) and Direct Preference Optimization (DPO), can significantly enhance value alignment in both in-domain and out-of-domain settings. Our findings underscore the necessity for population-aware alignment evaluation and provide actionable insights for building culturally adaptive and value-sensitive LLMs. MVPBench serves as a practical foundation for future research on global alignment, personalized value modeling, and equitable AI development.
FNBench: Benchmarking Robust Federated Learning against Noisy Labels
May 10, 2025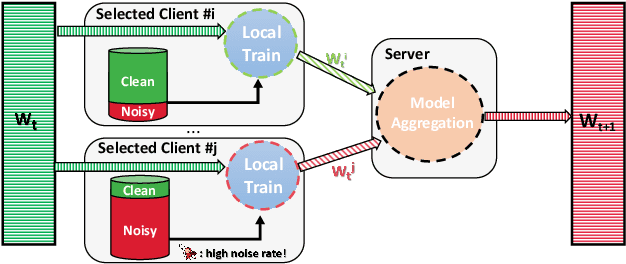
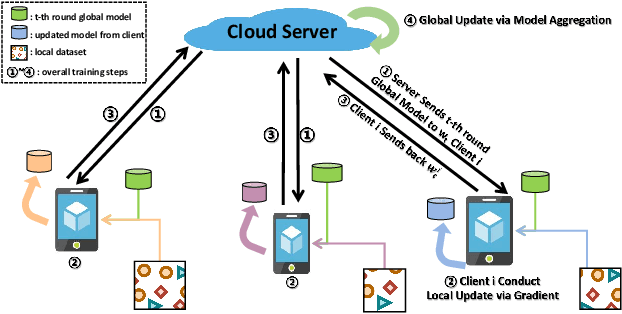
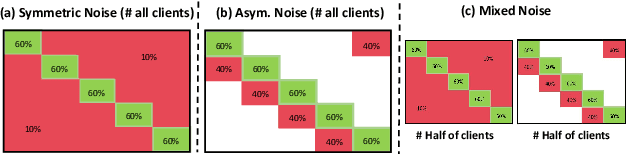
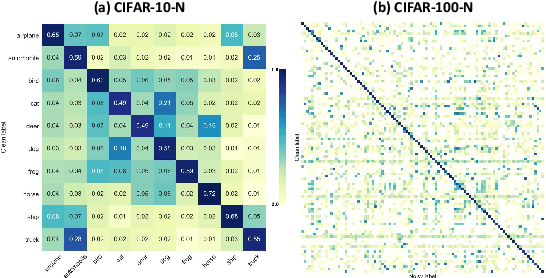
Robustness to label noise within data is a significant challenge in federated learning (FL). From the data-centric perspective, the data quality of distributed datasets can not be guaranteed since annotations of different clients contain complicated label noise of varying degrees, which causes the performance degradation. There have been some early attempts to tackle noisy labels in FL. However, there exists a lack of benchmark studies on comprehensively evaluating their practical performance under unified settings. To this end, we propose the first benchmark study FNBench to provide an experimental investigation which considers three diverse label noise patterns covering synthetic label noise, imperfect human-annotation errors and systematic errors. Our evaluation incorporates eighteen state-of-the-art methods over five image recognition datasets and one text classification dataset. Meanwhile, we provide observations to understand why noisy labels impair FL, and additionally exploit a representation-aware regularization method to enhance the robustness of existing methods against noisy labels based on our observations. Finally, we discuss the limitations of this work and propose three-fold future directions. To facilitate related communities, our source code is open-sourced at https://github.com/Sprinter1999/FNBench.
Redefining Superalignment: From Weak-to-Strong Alignment to Human-AI Co-Alignment to Sustainable Symbiotic Society
Apr 24, 2025Artificial Intelligence (AI) systems are becoming increasingly powerful and autonomous, and may progress to surpass human intelligence levels, namely Artificial Superintelligence (ASI). During the progression from AI to ASI, it may exceed human control, violate human values, and even lead to irreversible catastrophic consequences in extreme cases. This gives rise to a pressing issue that needs to be addressed: superalignment, ensuring that AI systems much smarter than humans, remain aligned with human (compatible) intentions and values. Existing scalable oversight and weak-to-strong generalization methods may prove substantially infeasible and inadequate when facing ASI. We must explore safer and more pluralistic frameworks and approaches for superalignment. In this paper, we redefine superalignment as the human-AI co-alignment towards a sustainable symbiotic society, and highlight a framework that integrates external oversight and intrinsic proactive alignment. External oversight superalignment should be grounded in human-centered ultimate decision, supplemented by interpretable automated evaluation and correction, to achieve continuous alignment with humanity's evolving values. Intrinsic proactive superalignment is rooted in a profound understanding of the self, others, and society, integrating self-awareness, self-reflection, and empathy to spontaneously infer human intentions, distinguishing good from evil and proactively considering human well-being, ultimately attaining human-AI co-alignment through iterative interaction. The integration of externally-driven oversight with intrinsically-driven proactive alignment empowers sustainable symbiotic societies through human-AI co-alignment, paving the way for achieving safe and beneficial AGI and ASI for good, for human, and for a symbiotic ecology.
AI Governance InternationaL Evaluation Index (AGILE Index)
Feb 26, 2025The rapid advancement of Artificial Intelligence (AI) technology is profoundly transforming human society and concurrently presenting a series of ethical, legal, and social issues. The effective governance of AI has become a crucial global concern. Since 2022, the extensive deployment of generative AI, particularly large language models, marked a new phase in AI governance. Continuous efforts are being made by the international community in actively addressing the novel challenges posed by these AI developments. As consensus on international governance continues to be established and put into action, the practical importance of conducting a global assessment of the state of AI governance is progressively coming to light. In this context, we initiated the development of the AI Governance InternationaL Evaluation Index (AGILE Index). Adhering to the design principle, "the level of governance should match the level of development," the inaugural evaluation of the AGILE Index commences with an exploration of four foundational pillars: the development level of AI, the AI governance environment, the AI governance instruments, and the AI governance effectiveness. It covers 39 indicators across 18 dimensions to comprehensively assess the AI governance level of 14 representative countries globally. The index is utilized to delve into the status of AI governance to date in 14 countries for the first batch of evaluation. The aim is to depict the current state of AI governance in these countries through data scoring, assist them in identifying their governance stage and uncovering governance issues, and ultimately offer insights for the enhancement of their AI governance systems.