 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Supervised Machine Learning Models: Principles, Pitfalls, and Metric Selection
Apr 15, 2026The evaluation of supervised machine learning models is a critical stage in the development of reliable predictive systems. Despite the widespread availability of machine learning libraries and automated workflows, model assessment is often reduced to the reporting of a small set of aggregate metrics, which can lead to misleading conclusions about real-world performance. This paper examines the principles, challenges, and practical considerations involved in evaluating supervised learning algorithms across classification and regression tasks. In particular, it discusses how evaluation outcomes are influenced by dataset characteristics, validation design, class imbalance, asymmetric error costs, and the choice of performance metrics. Through a series of controlled experimental scenarios using diverse benchmark datasets, the study highlights common pitfalls such as the accuracy paradox, data leakage, inappropriate metric selection, and overreliance on scalar summary measures. The paper also compares alternative validation strategies and emphasizes the importance of aligning model evaluation with the intended operational objective of the task. By presenting evaluation as a decision-oriented and context-dependent process, this work provides a structured foundation for selecting metrics and validation protocols that support statistically sound, robust, and trustworthy supervised machine learning systems.
LFPO: Likelihood-Free Policy Optimization for Masked Diffusion Models
Mar 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has achieved remarkable success in improving autoregressive models, especially in domains requiring correctness like mathematical reasoning and code generation. However, directly applying such paradigms to Diffusion Large Language Models (dLLMs) is fundamentally hindered by the intractability of exact likelihood computation, which forces existing methods to rely on high-variance approximations. To bridge this gap, we propose Likelihood-Free Policy Optimization (LFPO), a native framework that maps the concept of vector field flow matching to the discrete token space. Specifically, LFPO formulates alignment as geometric velocity rectification, which directly optimizes denoising logits via contrastive updates. This design effectively bypasses the errors inherent in likelihood approximation, yielding the precise gradient estimation. Furthermore, LFPO enforce consistency by predicting final solutions from intermediate steps, effectively straightening the probability flow to enable high-quality generation with significantly fewer iterations. Extensive experiments demonstrate that LFPO not only outperforms state-of-the-art baselines on code and reasoning benchmarks but also accelerates inference by approximately 20% through reduced diffusion steps.
StyMam: A Mamba-Based Generator for Artistic Style Transfer
Jan 19, 2026Image style transfer aims to integrate the visual patterns of a specific artistic style into a content image while preserving its content structure. Existing methods mainly rely on the generative adversarial network (GAN) or stable diffusion (SD). GAN-based approaches using CNNs or Transformers struggle to jointly capture local and global dependencies, leading to artifacts and disharmonious patterns. SD-based methods reduce such issues but often fail to preserve content structures and suffer from slow inference. To address these issues, we revisit GAN and propose a mamba-based generator, termed as StyMam, to produce high-quality stylized images without introducing artifacts and disharmonious patterns. Specifically, we introduce a mamba-based generator with a residual dual-path strip scanning mechanism and a channel-reweighted spatial attention module. The former efficiently captures local texture features, while the latter models global dependencies. Finally, extensive qualitative and quantitative experiments demonstrate that the proposed method outperforms state-of-the-art algorithms in both quality and speed.
MTP: Exploring Multimodal Urban Traffic Profiling with Modality Augmentation and Spectrum Fusion
Nov 17, 2025With rapid urbanization in the modern era, traffic signals from various sensors have been playing a significant role in monitoring the states of cities, which provides a strong foundation in ensuring safe travel, reducing traffic congestion and optimizing urban mobility. Most existing methods for traffic signal modeling often rely on the original data modality, i.e., numerical direct readings from the sensors in cities. However, this unimodal approach overlooks the semantic information existing in multimodal heterogeneous urban data in different perspectives, which hinders a comprehensive understanding of traffic signals and limits the accurate prediction of complex traffic dynamics. To address this problem, we propose a novel Multimodal framework, MTP, for urban Traffic Profiling, which learns multimodal features through numeric, visual, and textual perspectives. The three branches drive for a multimodal perspective of urban traffic signal learning in the frequency domain, while the frequency learning strategies delicately refine the information for extraction. Specifically, we first conduct the visual augmentation for the traffic signals, which transforms the original modality into frequency images and periodicity images for visual learning. Also, we augment descriptive texts for the traffic signals based on the specific topic, background information and item description for textual learning. To complement the numeric information, we utilize frequency multilayer perceptrons for learning on the original modality. We design a hierarchical contrastive learning on the three branches to fuse the spectrum of three modalities. Finally, extensive experiments on six real-world datasets demonstrate superior performance compared with the state-of-the-art approaches.
Reward-Driven Interaction: Enhancing Proactive Dialogue Agents through User Satisfaction Prediction
May 24, 2025Reward-driven proactive dialogue agents require precise estimation of user satisfaction as an intrinsic reward signal to determine optimal interaction strategies. Specifically, this framework triggers clarification questions when detecting potential user dissatisfaction during interactions in the industrial dialogue system. Traditional works typically rely on training a neural network model based on weak labels which are generated by a simple model trained on user actions after current turn. However, existing methods suffer from two critical limitations in real-world scenarios: (1) Noisy Reward Supervision, dependence on weak labels derived from post-hoc user actions introduces bias, particularly failing to capture satisfaction signals in ASR-error-induced utterances; (2) Long-Tail Feedback Sparsity, the power-law distribution of user queries causes reward prediction accuracy to drop in low-frequency domains. The noise in the weak labels and a power-law distribution of user utterances results in that the model is hard to learn good representation of user utterances and sessions. To address these limitations, we propose two auxiliary tasks to improve the representation learning of user utterances and sessions that enhance user satisfaction prediction. The first one is a contrastive self-supervised learning task, which helps the model learn the representation of rare user utterances and identify ASR errors. The second one is a domain-intent classification task, which aids the model in learning the representation of user sessions from long-tailed domains and improving the model's performance on such domains. The proposed method is evaluated on DuerOS, demonstrating significant improvements in the accuracy of error recognition on rare user utterances and long-tailed domains.
LeetCodeDataset: A Temporal Dataset for Robust Evaluation and Efficient Training of Code LLMs
Apr 20, 2025
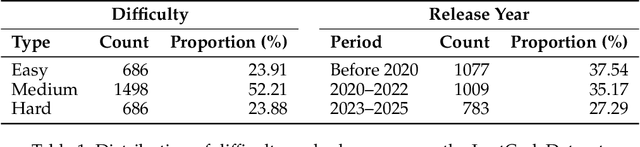
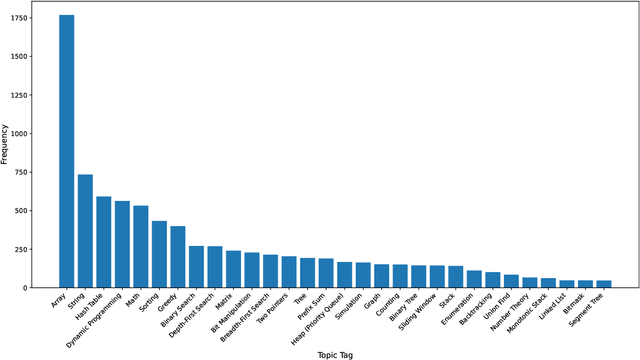
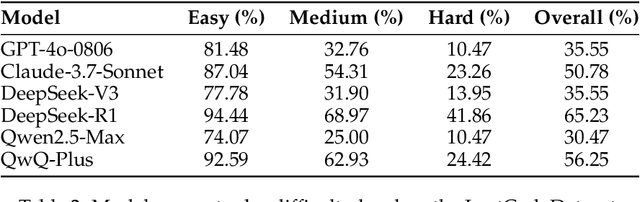
We introduce LeetCodeDataset, a high-quality benchmark for evaluating and training code-generation models, addressing two key challenges in LLM research: the lack of reasoning-focused coding benchmarks and self-contained training testbeds. By curating LeetCode Python problems with rich metadata, broad coverage, 100+ test cases per problem, and temporal splits (pre/post July 2024), our dataset enables contamination-free evaluation and efficient supervised fine-tuning (SFT). Experiments show reasoning models significantly outperform non-reasoning counterparts, while SFT with only 2.6K model-generated solutions achieves performance comparable to 110K-sample counterparts. The dataset and evaluation framework are available on Hugging Face and Github.
CMCRD: Cross-Modal Contrastive Representation Distillation for Emotion Recognition
Apr 12, 2025



Emotion recognition is an important component of affective computing, and also human-machine interaction. Unimodal emotion recognition is convenient, but the accuracy may not be high enough; on the contrary, multi-modal emotion recognition may be more accurate, but it also increases the complexity and cost of the data collection system. This paper considers cross-modal emotion recognition, i.e., using both electroencephalography (EEG) and eye movement in training, but only EEG or eye movement in test. We propose cross-modal contrastive representation distillation (CMCRD), which uses a pre-trained eye movement classification model to assist the training of an EEG classification model, improving feature extraction from EEG signals, or vice versa. During test, only EEG signals (or eye movement signals) are acquired, eliminating the need for multi-modal data. CMCRD not only improves the emotion recognition accuracy, but also makes the system more simplified and practical. Experiments using three different neural network architectures on three multi-modal emotion recognition datasets demonstrated the effectiveness of CMCRD. Compared with the EEG-only model, it improved the average classification accuracy by about 6.2%.
DapperFL: Domain Adaptive Federated Learning with Model Fusion Pruning for Edge Devices
Dec 08, 2024Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data. In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a realworld FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to 2.28%, while significantly achieving model volume reductions ranging from 20% to 80%. Our code is available at: https://github.com/jyzgh/DapperFL.
REFOL: Resource-Efficient Federated Online Learning for Traffic Flow Forecasting
Nov 21, 2024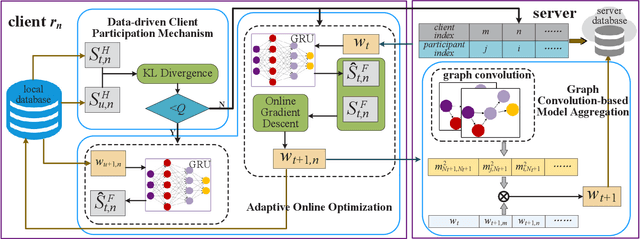
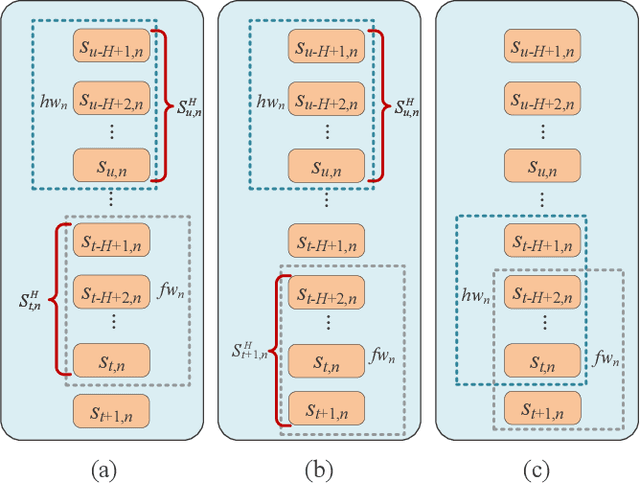
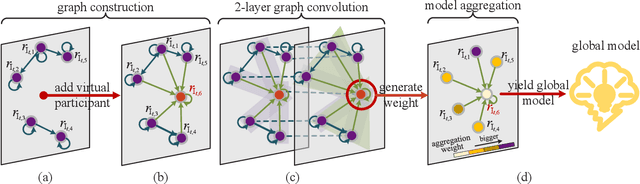
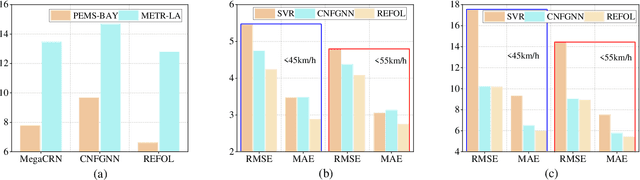
Multiple federated learning (FL) methods are proposed for traffic flow forecasting (TFF) to avoid heavy-transmission and privacy-leaking concerns resulting from the disclosure of raw data in centralized methods. However, these FL methods adopt offline learning which may yield subpar performance, when concept drift occurs, i.e., distributions of historical and future data vary. Online learning can detect concept drift during model training, thus more applicable to TFF. Nevertheless, the existing federated online learning method for TFF fails to efficiently solve the concept drift problem and causes tremendous computing and communication overhead. Therefore, we propose a novel method named Resource-Efficient Federated Online Learning (REFOL) for TFF, which guarantees prediction performance in a communication-lightweight and computation-efficient way. Specifically, we design a data-driven client participation mechanism to detect the occurrence of concept drift and determine clients' participation necessity. Subsequently, we propose an adaptive online optimization strategy, which guarantees prediction performance and meanwhile avoids meaningless model updates. Then, a graph convolution-based model aggregation mechanism is designed, aiming to assess participants' contribution based on spatial correlation without importing extra communication and computing consumption on clients. Finally, we conduct extensive experiments on real-world datasets to demonstrate the superiority of REFOL in terms of prediction improvement and resource economization.
Real-time and Downtime-tolerant Fault Diagnosis for Railway Turnout Machines (RTMs) Empowered with Cloud-Edge Pipeline Parallelism
Nov 04, 2024



Railway Turnout Machines (RTMs) are mission-critical components of the railway transportation infrastructure, responsible for directing trains onto desired tracks. For safety assurance applications, especially in early-warning scenarios, RTM faults are expected to be detected as early as possible on a continuous 7x24 basis. However, limited emphasis has been placed on distributed model inference frameworks that can meet the inference latency and reliability requirements of such mission critical fault diagnosis systems. In this paper, an edge-cloud collaborative early-warning system is proposed to enable real-time and downtime-tolerant fault diagnosis of RTMs, providing a new paradigm for the deployment of models in safety-critical scenarios. Firstly, a modular fault diagnosis model is designed specifically for distributed deployment, which utilizes a hierarchical architecture consisting of the prior knowledge module, subordinate classifiers, and a fusion layer for enhanced accuracy and parallelism. Then, a cloud-edge collaborative framework leveraging pipeline parallelism, namely CEC-PA, is developed to minimize the overhead resulting from distributed task execution and context exchange by strategically partitioning and offloading model components across cloud and edge. Additionally, an election consensus mechanism is implemented within CEC-PA to ensure system robustness during coordinator node downtime. Comparative experiments and ablation studies are conducted to validate the effectiveness of the proposed distributed fault diagnosis approach. Our ensemble-based fault diagnosis model achieves a remarkable 97.4% accuracy on a real-world dataset collected by Nanjing Metro in Jiangsu Province, China. Meanwhile, CEC-PA demonstrates superior recovery proficiency during node disruptions and speed-up ranging from 1.98x to 7.93x in total inference time compared to its counterparts.