 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Learn to Reason Robustly under Noisy Supervision?
Apr 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) effectively trains reasoning models that rely on abundant perfect labels, but its vulnerability to unavoidable noisy labels due to expert scarcity remains critically underexplored. In this work, we take the first step toward a systematic analysis of noisy label mechanisms in RLVR. In contrast to supervised classification, most RLVR algorithms incorporate a rollout-based condition: a label's influence on training is contingent on whether the current policy can generate rollouts that realize it, a property that naturally extends to noisy labels. Based on this observation, we distinguish two types of noise: inactive noisy labels, which reduce data efficiency, and active noisy labels, which are reinforced and risk skewing the model toward incorrect distributions. From experiments on training with noisy samples, we identify an Early Correctness Coherence phenomenon: although noisy samples begin to lag behind in later stages, accuracy on both clean and noisy samples increases similarly in early training. Motivated by this dynamic, we propose Online Label Refinement (OLR), which progressively corrects potentially noisy labels with majority-voted answers when two conditions hold: a positive slope in the majority answer's rollout pass rate and stable historical consistency across updates, enabling gradual self-correction as the policy improves. We evaluate OLR on six in-distribution mathematical reasoning benchmarks (AIME24/25, AMC, MATH-500, Minerva, and Olympiad) and three out-of-distribution tasks (ARC-c, GPQA-diamond, and MMLU-pro). Across noise ratios from 0.1 to 0.9, OLR consistently improves robustness under both inactive and active noisy-label settings, achieving average gains of 3.6% to 3.9% on in-distribution benchmarks and 3.3% to 4.6% on out-of-distribution evaluations.
Multimodal Adaptive Retrieval Augmented Generation through Internal Representation Learning
Feb 28, 2026Visual Question Answering systems face reliability issues due to hallucinations, where models generate answers misaligned with visual input or factual knowledge. While Retrieval Augmented Generation frameworks mitigate this issue by incorporating external knowledge, static retrieval often introduces irrelevant or conflicting content, particularly in visual RAG settings where visually similar but semantically incorrect evidence may be retrieved. To address this, we propose Multimodal Adaptive RAG (MMA-RAG), which dynamically assesses the confidence in the internal knowledge of the model to decide whether to incorporate the retrieved external information into the generation process. Central to MMA-RAG is a decision classifier trained through a layer-wise analysis, which leverages joint internal visual and textual representations to guide the use of reverse image retrieval. Experiments demonstrated that the model achieves a significant improvement in response performance in three VQA datasets. Meanwhile, ablation studies highlighted the importance of internal representations in adaptive retrieval decisions. In general, the experimental results demonstrated that MMA-RAG effectively balances external knowledge utilization and inference robustness in diverse multimodal scenarios.
Predict the Retrieval! Test time adaptation for Retrieval Augmented Generation
Jan 16, 2026Retrieval-Augmented Generation (RAG) has emerged as a powerful approach for enhancing large language models' question-answering capabilities through the integration of external knowledge. However, when adapting RAG systems to specialized domains, challenges arise from distribution shifts, resulting in suboptimal generalization performance. In this work, we propose TTARAG, a test-time adaptation method that dynamically updates the language model's parameters during inference to improve RAG system performance in specialized domains. Our method introduces a simple yet effective approach where the model learns to predict retrieved content, enabling automatic parameter adjustment to the target domain. Through extensive experiments across six specialized domains, we demonstrate that TTARAG achieves substantial performance improvements over baseline RAG systems. Code available at https://github.com/sunxin000/TTARAG.
TraPO: A Semi-Supervised Reinforcement Learning Framework for Boosting LLM Reasoning
Dec 15, 2025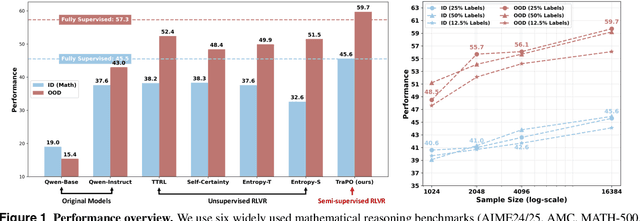
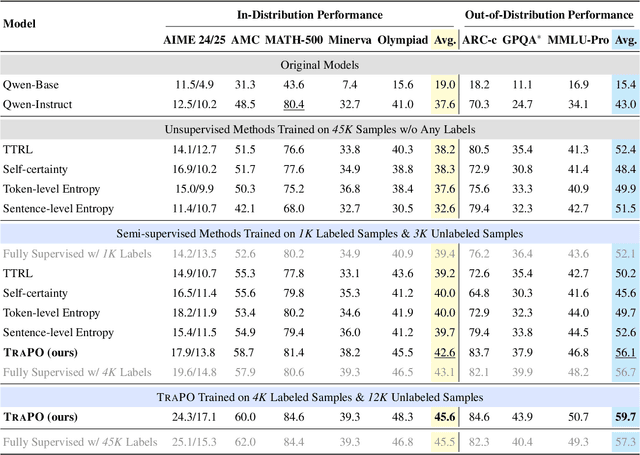
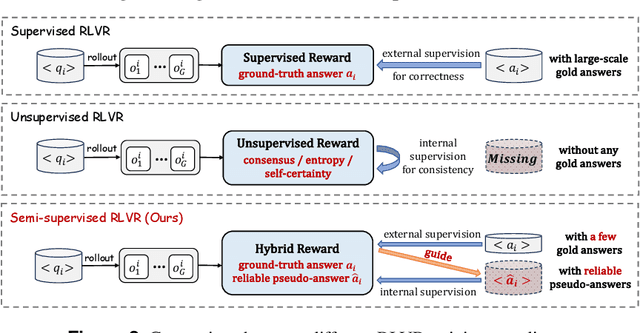
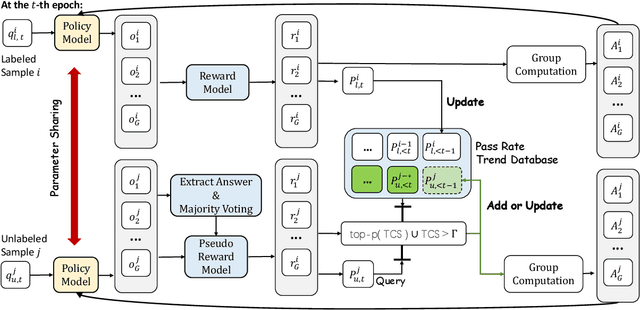
Reinforcement learning with verifiable rewards (RLVR) has proven effective in training large reasoning models (LRMs) by leveraging answer-verifiable signals to guide policy optimization, which, however, suffers from high annotation costs. To alleviate this problem, recent work has explored unsupervised RLVR methods that derive rewards solely from the model's internal consistency, such as through entropy and majority voting. While seemingly promising, these methods often suffer from model collapse in the later stages of training, which may arise from the reinforcement of incorrect reasoning patterns in the absence of external supervision. In this work, we investigate a novel semi-supervised RLVR paradigm that utilizes a small labeled set to guide RLVR training on unlabeled samples. Our key insight is that supervised rewards are essential for stabilizing consistency-based training on unlabeled samples, ensuring that only reasoning patterns verified on labeled instances are incorporated into RL training. Technically, we propose an effective policy optimization algorithm, TraPO, that identifies reliable unlabeled samples by matching their learning trajectory similarity to labeled ones. Building on this, TraPO achieves remarkable data efficiency and strong generalization on six widely used mathematical reasoning benchmarks (AIME24/25, AMC, MATH-500, Minerva, and Olympiad) and three out-of-distribution tasks (ARC-c, GPQA-diamond, and MMLU-pro). With only 1K labeled and 3K unlabeled samples, TraPO reaches 42.6% average accuracy, surpassing the best unsupervised method trained on 45K unlabeled samples (38.3%). Notably, when using 4K labeled and 12K unlabeled samples, TraPO even outperforms the fully supervised model trained on the full 45K labeled samples on all benchmarks, while using only 10% of the labeled data. The code is available via https://github.com/ShenzhiYang2000/TRAPO.
KBQA-R1: Reinforcing Large Language Models for Knowledge Base Question Answering
Dec 10, 2025Knowledge Base Question Answering (KBQA) challenges models to bridge the gap between natural language and strict knowledge graph schemas by generating executable logical forms. While Large Language Models (LLMs) have advanced this field, current approaches often struggle with a dichotomy of failure: they either generate hallucinated queries without verifying schema existence or exhibit rigid, template-based reasoning that mimics synthesized traces without true comprehension of the environment. To address these limitations, we present \textbf{KBQA-R1}, a framework that shifts the paradigm from text imitation to interaction optimization via Reinforcement Learning. Treating KBQA as a multi-turn decision process, our model learns to navigate the knowledge base using a list of actions, leveraging Group Relative Policy Optimization (GRPO) to refine its strategies based on concrete execution feedback rather than static supervision. Furthermore, we introduce \textbf{Referenced Rejection Sampling (RRS)}, a data synthesis method that resolves cold-start challenges by strictly aligning reasoning traces with ground-truth action sequences. Extensive experiments on WebQSP, GrailQA, and GraphQuestions demonstrate that KBQA-R1 achieves state-of-the-art performance, effectively grounding LLM reasoning in verifiable execution.
SMART: Relation-Aware Learning of Geometric Representations for Knowledge Graphs
Jul 17, 2025Knowledge graph representation learning approaches provide a mapping between symbolic knowledge in the form of triples in a knowledge graph (KG) and their feature vectors. Knowledge graph embedding (KGE) models often represent relations in a KG as geometric transformations. Most state-of-the-art (SOTA) KGE models are derived from elementary geometric transformations (EGTs), such as translation, scaling, rotation, and reflection, or their combinations. These geometric transformations enable the models to effectively preserve specific structural and relational patterns of the KG. However, the current use of EGTs by KGEs remains insufficient without considering relation-specific transformations. Although recent models attempted to address this problem by ensembling SOTA baseline models in different ways, only a single or composite version of geometric transformations are used by such baselines to represent all the relations. In this paper, we propose a framework that evaluates how well each relation fits with different geometric transformations. Based on this ranking, the model can: (1) assign the best-matching transformation to each relation, or (2) use majority voting to choose one transformation type to apply across all relations. That is, the model learns a single relation-specific EGT in low dimensional vector space through an attention mechanism. Furthermore, we use the correlation between relations and EGTs, which are learned in a low dimension, for relation embeddings in a high dimensional vector space. The effectiveness of our models is demonstrated through comprehensive evaluations on three benchmark KGs as well as a real-world financial KG, witnessing a performance comparable to leading models
Antithetic Noise in Diffusion Models
Jun 06, 2025



We initiate a systematic study of antithetic initial noise in diffusion models. Across unconditional models trained on diverse datasets, text-conditioned latent-diffusion models, and diffusion-posterior samplers, we find that pairing each initial noise with its negation consistently yields strongly negatively correlated samples. To explain this phenomenon, we combine experiments and theoretical analysis, leading to a symmetry conjecture that the learned score function is approximately affine antisymmetric (odd symmetry up to a constant shift), and provide evidence supporting it. Leveraging this negative correlation, we enable two applications: (1) enhancing image diversity in models like Stable Diffusion without quality loss, and (2) sharpening uncertainty quantification (e.g., up to 90% narrower confidence intervals) when estimating downstream statistics. Building on these gains, we extend the two-point pairing to a randomized quasi-Monte Carlo estimator, which further improves estimation accuracy. Our framework is training-free, model-agnostic, and adds no runtime overhead.
Divide-Then-Align: Honest Alignment based on the Knowledge Boundary of RAG
May 27, 2025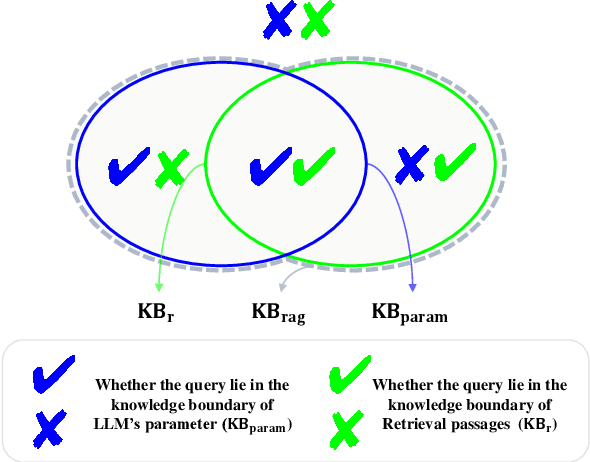
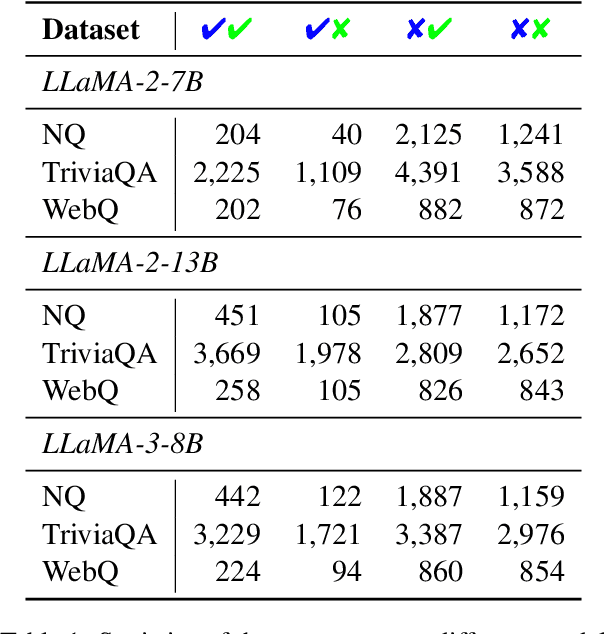
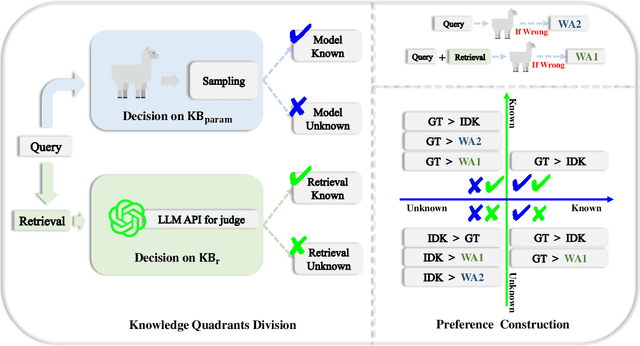

Large language models (LLMs) augmented with retrieval systems have significantly advanced natural language processing tasks by integrating external knowledge sources, enabling more accurate and contextually rich responses. To improve the robustness of such systems against noisy retrievals, Retrieval-Augmented Fine-Tuning (RAFT) has emerged as a widely adopted method. However, RAFT conditions models to generate answers even in the absence of reliable knowledge. This behavior undermines their reliability in high-stakes domains, where acknowledging uncertainty is critical. To address this issue, we propose Divide-Then-Align (DTA), a post-training approach designed to endow RAG systems with the ability to respond with "I don't know" when the query is out of the knowledge boundary of both the retrieved passages and the model's internal knowledge. DTA divides data samples into four knowledge quadrants and constructs tailored preference data for each quadrant, resulting in a curated dataset for Direct Preference Optimization (DPO). Experimental results on three benchmark datasets demonstrate that DTA effectively balances accuracy with appropriate abstention, enhancing the reliability and trustworthiness of retrieval-augmented systems.
CCS: Controllable and Constrained Sampling with Diffusion Models via Initial Noise Perturbation
Feb 07, 2025



Diffusion models have emerged as powerful tools for generative tasks, producing high-quality outputs across diverse domains. However, how the generated data responds to the initial noise perturbation in diffusion models remains under-explored, which hinders understanding the controllability of the sampling process. In this work, we first observe an interesting phenomenon: the relationship between the change of generation outputs and the scale of initial noise perturbation is highly linear through the diffusion ODE sampling. Then we provide both theoretical and empirical study to justify this linearity property of this input-output (noise-generation data) relationship. Inspired by these new insights, we propose a novel Controllable and Constrained Sampling method (CCS) together with a new controller algorithm for diffusion models to sample with desired statistical properties while preserving good sample quality. We perform extensive experiments to compare our proposed sampling approach with other methods on both sampling controllability and sampled data quality. Results show that our CCS method achieves more precisely controlled sampling while maintaining superior sample quality and diversity.
What You See Is What Matters: A Novel Visual and Physics-Based Metric for Evaluating Video Generation Quality
Nov 20, 2024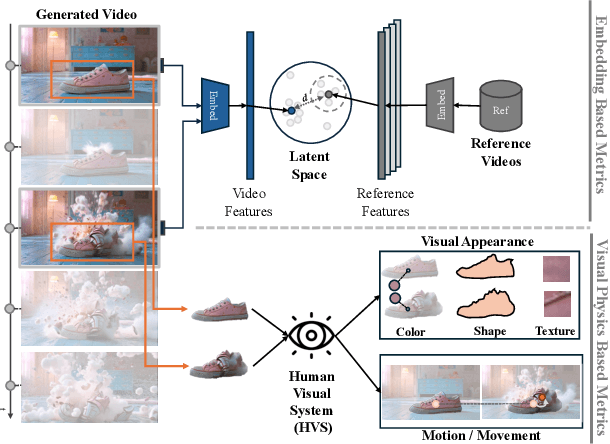
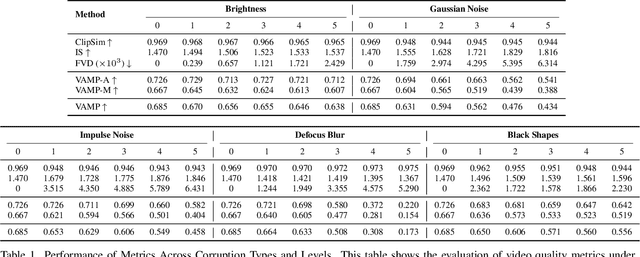
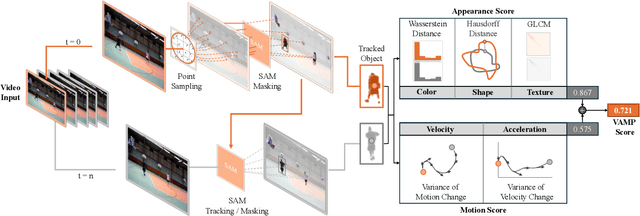
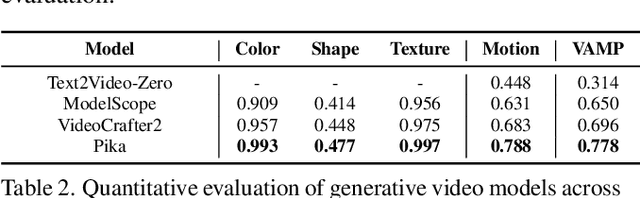
As video generation models advance rapidly, assessing the quality of generated videos has become increasingly critical. Existing metrics, such as Fr\'echet Video Distance (FVD), Inception Score (IS), and ClipSim, measure quality primarily in latent space rather than from a human visual perspective, often overlooking key aspects like appearance and motion consistency to physical laws. In this paper, we propose a novel metric, VAMP (Visual Appearance and Motion Plausibility), that evaluates both the visual appearance and physical plausibility of generated videos. VAMP is composed of two main components: an appearance score, which assesses color, shape, and texture consistency across frames, and a motion score, which evaluates the realism of object movements. We validate VAMP through two experiments: corrupted video evaluation and generated video evaluation. In the corrupted video evaluation, we introduce various types of corruptions into real videos and measure the correlation between corruption severity and VAMP scores. In the generated video evaluation, we use state-of-the-art models to generate videos from carefully designed prompts and compare VAMP's performance to human evaluators' rankings. Our results demonstrate that VAMP effectively captures both visual fidelity and temporal consistency, offering a more comprehensive evaluation of video quality than traditional methods.