 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleepLM: Natural-Language Intelligence for Human Sleep
Feb 27, 2026We present SleepLM, a family of sleep-language foundation models that enable human sleep alignment, interpretation, and interaction with natural language. Despite the critical role of sleep, learning-based sleep analysis systems operate in closed label spaces (e.g., predefined stages or events) and fail to describe, query, or generalize to novel sleep phenomena. SleepLM bridges natural language and multimodal polysomnography, enabling language-grounded representations of sleep physiology. To support this alignment, we introduce a multilevel sleep caption generation pipeline that enables the curation of the first large-scale sleep-text dataset, comprising over 100K hours of data from more than 10,000 individuals. Furthermore, we present a unified pretraining objective that combines contrastive alignment, caption generation, and signal reconstruction to better capture physiological fidelity and cross-modal interactions. Extensive experiments on real-world sleep understanding tasks verify that SleepLM outperforms state-of-the-art in zero-shot and few-shot learning, cross-modal retrieval, and sleep captioning. Importantly, SleepLM also exhibits intriguing capabilities including language-guided event localization, targeted insight generation, and zero-shot generalization to unseen tasks. All code and data will be open-sourced.
OSF: On Pre-training and Scaling of Sleep Foundation Models
Feb 27, 2026Polysomnography (PSG) provides the gold standard for sleep assessment but suffers from substantial heterogeneity across recording devices and cohorts. There have been growing efforts to build general-purpose foundation models (FMs) for sleep physiology, but lack an in-depth understanding of the pre-training process and scaling patterns that lead to more generalizable sleep FMs. To fill this gap, we curate a massive corpus of 166,500 hours of sleep recordings from nine public sources and establish SleepBench, a comprehensive, fully open-source benchmark. Leveraging SleepBench, we systematically evaluate four families of self-supervised pre-training objectives and uncover three critical findings: (1) existing FMs fail to generalize to missing channels at inference; (2) channel-invariant feature learning is essential for pre-training; and (3) scaling sample size, model capacity, and multi-source data mixture consistently improves downstream performance.With an enhanced pre-training and scaling recipe, we introduce OSF, a family of sleep FMs that achieves state-of-the-art performance across nine datasets on diverse sleep and disease prediction tasks. Further analysis of OSF also reveals intriguing properties in sample efficiency, hierarchical aggregation, and cross-dataset scaling.
Dynamical Multimodal Fusion with Mixture-of-Experts for Localizations
Jul 02, 2025Multimodal fingerprinting is a crucial technique to sub-meter 6G integrated sensing and communications (ISAC) localization, but two hurdles block deployment: (i) the contribution each modality makes to the target position varies with the operating conditions such as carrier frequency, and (ii) spatial and fingerprint ambiguities markedly undermine localization accuracy, especially in non-line-of-sight (NLOS) scenarios. To solve these problems, we introduce SCADF-MoE, a spatial-context aware dynamic fusion network built on a soft mixture-of-experts backbone. SCADF-MoE first clusters neighboring points into short trajectories to inject explicit spatial context. Then, it adaptively fuses channel state information, angle of arrival profile, distance, and gain through its learnable MoE router, so that the most reliable cues dominate at each carrier band. The fused representation is fed to a modality-task MoE that simultaneously regresses the coordinates of every vertex in the trajectory and its centroid, thereby exploiting inter-point correlations. Finally, an auxiliary maximum-mean-discrepancy loss enforces expert diversity and mitigates gradient interference, stabilizing multi-task training. On three real urban layouts and three carrier bands (2.6, 6, 28 GHz), the model delivers consistent sub-meter MSE and halves unseen-NLOS error versus the best prior work. To our knowledge, this is the first work that leverages large-scale multimodal MoE for frequency-robust ISAC localization.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Multi-OphthaLingua: A Multilingual Benchmark for Assessing and Debiasing LLM Ophthalmological QA in LMICs
Dec 18, 2024



Current ophthalmology clinical workflows are plagued by over-referrals, long waits, and complex and heterogeneous medical records. Large language models (LLMs) present a promising solution to automate various procedures such as triaging, preliminary tests like visual acuity assessment, and report summaries. However, LLMs have demonstrated significantly varied performance across different languages in natural language question-answering tasks, potentially exacerbating healthcare disparities in Low and Middle-Income Countries (LMICs). This study introduces the first multilingual ophthalmological question-answering benchmark with manually curated questions parallel across languages, allowing for direct cross-lingual comparisons. Our evaluation of 6 popular LLMs across 7 different languages reveals substantial bias across different languages, highlighting risks for clinical deployment of LLMs in LMICs. Existing debiasing methods such as Translation Chain-of-Thought or Retrieval-augmented generation (RAG) by themselves fall short of closing this performance gap, often failing to improve performance across all languages and lacking specificity for the medical domain. To address this issue, We propose CLARA (Cross-Lingual Reflective Agentic system), a novel inference time de-biasing method leveraging retrieval augmented generation and self-verification. Our approach not only improves performance across all languages but also significantly reduces the multilingual bias gap, facilitating equitable LLM application across the globe.
Multi-Sources Fusion Learning for Multi-Points NLOS Localization in OFDM System
Sep 04, 2024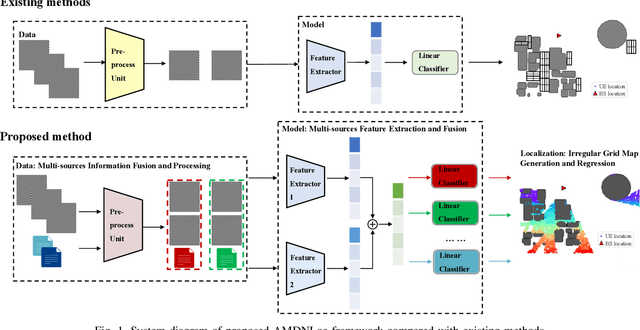
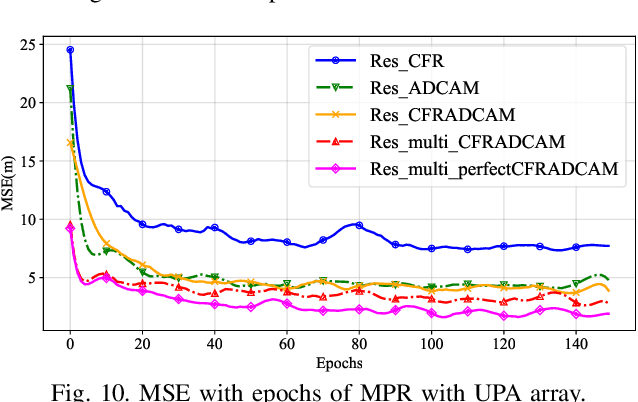
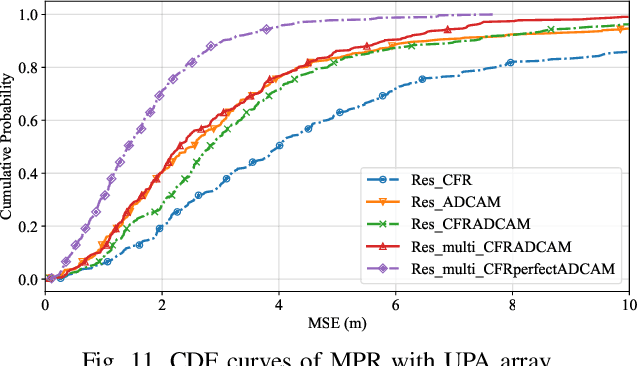
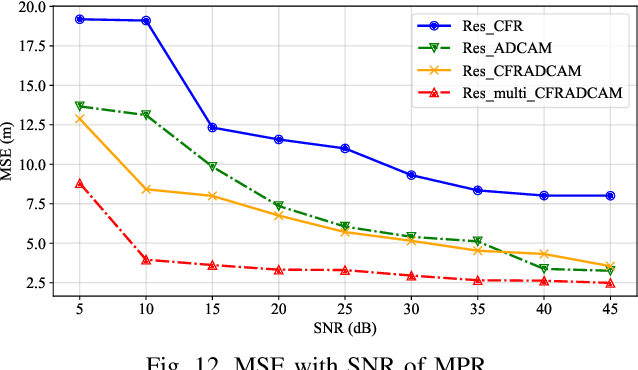
Accurate localization of mobile terminals is a pivotal aspect of integrated sensing and communication systems. Traditional fingerprint-based localization methods, which infer coordinates from channel information within pre-set rectangular areas, often face challenges due to the heterogeneous distribution of fingerprints inherent in non-line-of-sight (NLOS) scenarios, particularly within orthogonal frequency division multiplexing systems. To overcome this limitation, we develop a novel multi-sources information fusion learning framework referred to as the Autosync Multi-Domains NLOS Localization (AMDNLoc). Specifically, AMDNLoc employs a two-stage matched filter fused with a target tracking algorithm and iterative centroid-based clustering to automatically and irregularly segment NLOS regions, ensuring uniform distribution within channel state information across frequency, power, and time-delay domains. Additionally, the framework utilizes a segment-specific linear classifier array, coupled with deep residual network-based feature extraction and fusion, to establish the correlation function between fingerprint features and coordinates within these regions. Simulation results reveal that AMDNLoc achieves an impressive NLOS localization accuracy of 1.46 meters on typical wireless artificial intelligence research datasets and demonstrates significant improvements in interpretability, adaptability, and scalability.
Latent Space Disentanglement in Diffusion Transformers Enables Zero-shot Fine-grained Semantic Editing
Aug 23, 2024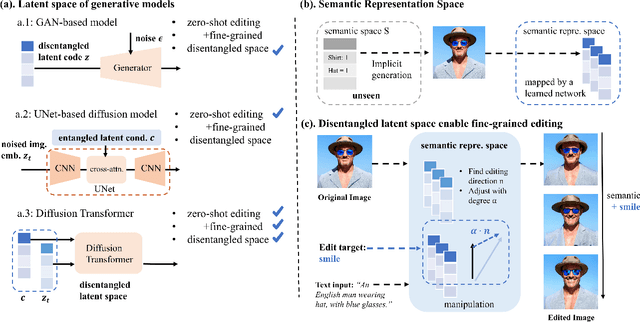

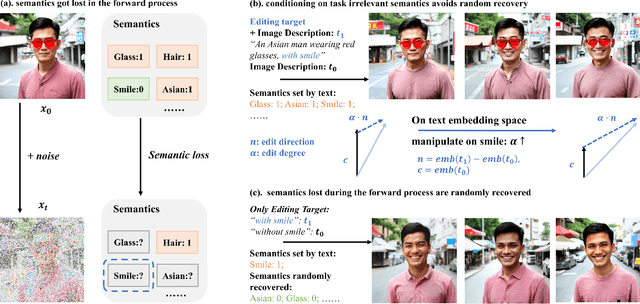

Diffusion Transformers (DiTs) have achieved remarkable success in diverse and high-quality text-to-image(T2I) generation. However, how text and image latents individually and jointly contribute to the semantics of generated images, remain largely unexplored. Through our investigation of DiT's latent space, we have uncovered key findings that unlock the potential for zero-shot fine-grained semantic editing: (1) Both the text and image spaces in DiTs are inherently decomposable. (2) These spaces collectively form a disentangled semantic representation space, enabling precise and fine-grained semantic control. (3) Effective image editing requires the combined use of both text and image latent spaces. Leveraging these insights, we propose a simple and effective Extract-Manipulate-Sample (EMS) framework for zero-shot fine-grained image editing. Our approach first utilizes a multi-modal Large Language Model to convert input images and editing targets into text descriptions. We then linearly manipulate text embeddings based on the desired editing degree and employ constrained score distillation sampling to manipulate image embeddings. We quantify the disentanglement degree of the latent space of diffusion models by proposing a new metric. To evaluate fine-grained editing performance, we introduce a comprehensive benchmark incorporating both human annotations, manual evaluation, and automatic metrics. We have conducted extensive experimental results and in-depth analysis to thoroughly uncover the semantic disentanglement properties of the diffusion transformer, as well as the effectiveness of our proposed method. Our annotated benchmark dataset is publicly available at https://anonymous.com/anonymous/EMS-Benchmark, facilitating reproducible research in this domain.
Efficient In-Context Medical Segmentation with Meta-driven Visual Prompt Selection
Jul 15, 2024



In-context learning (ICL) with Large Vision Models (LVMs) presents a promising avenue in medical image segmentation by reducing the reliance on extensive labeling. However, the ICL performance of LVMs highly depends on the choices of visual prompts and suffers from domain shifts. While existing works leveraging LVMs for medical tasks have focused mainly on model-centric approaches like fine-tuning, we study an orthogonal data-centric perspective on how to select good visual prompts to facilitate generalization to medical domain. In this work, we propose a label-efficient in-context medical segmentation method by introducing a novel Meta-driven Visual Prompt Selection mechanism (MVPS), where a prompt retriever obtained from a meta-learning framework actively selects the optimal images as prompts to promote model performance and generalizability. Evaluated on 8 datasets and 4 tasks across 3 medical imaging modalities, our proposed approach demonstrates consistent gains over existing methods under different scenarios, improving both computational and label efficiency. Finally, we show that MVPS is a flexible, finetuning-free module that could be easily plugged into different backbones and combined with other model-centric approaches.
Mitigating Heterogeneity in Federated Multimodal Learning with Biomedical Vision-Language Pre-training
Apr 05, 2024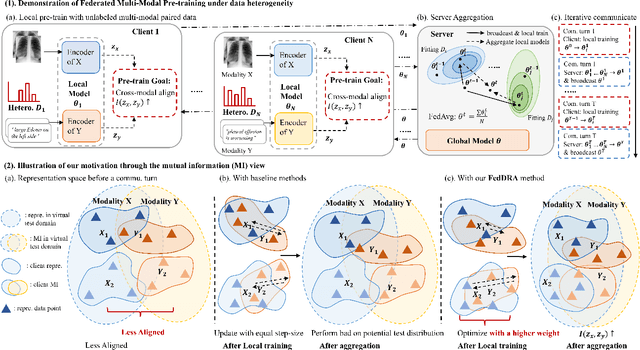

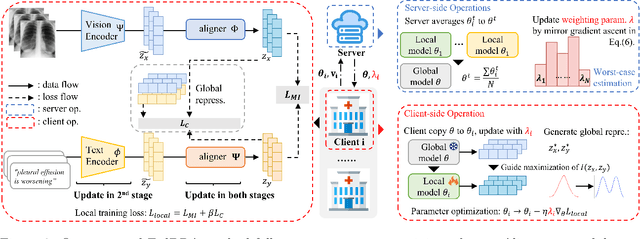
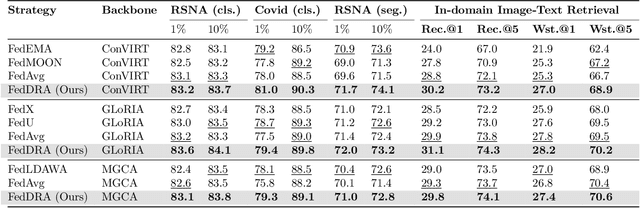
Vision-language pre-training (VLP) has arised as an efficient scheme for multimodal representation learning, but it requires large-scale multimodal data for pre-training, making it an obstacle especially for biomedical applications. To overcome the data limitation, federated learning (FL) can be a promising strategy to scale up the dataset for biomedical VLP while protecting data privacy. However, client data are often heterogeneous in real-world scenarios, and we observe that local training on heterogeneous client data would distort the multimodal representation learning and lead to biased cross-modal alignment. To address this challenge, we propose Federated distributional Robust Guidance-Based (FedRGB) learning framework for federated VLP with robustness to data heterogeneity. Specifically, we utilize a guidance-based local training scheme to reduce feature distortions, and employ a distribution-based min-max optimization to learn unbiased cross-modal alignment. The experiments on real-world datasets show our method successfully promotes efficient federated multimodal learning for biomedical VLP with data heterogeneity.