 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Compression May Hurt Generalization: A Remedy by Synthetic Data Guided Sharpness Aware Minimization
Feb 12, 2026It is commonly believed that gradient compression in federated learning (FL) enjoys significant improvement in communication efficiency with negligible performance degradation. In this paper, we find that gradient compression induces sharper loss landscapes in federated learning, particularly under non-IID data distributions, which suggests hindered generalization capability. The recently emerging Sharpness Aware Minimization (SAM) effectively searches for a flat minima by incorporating a gradient ascent step (i.e., perturbing the model with gradients) before the celebrated stochastic gradient descent. Nonetheless, the direct application of SAM in FL suffers from inaccurate estimation of the global perturbation due to data heterogeneity. Existing approaches propose to utilize the model update from the previous communication round as a rough estimate. However, its effectiveness is hindered when model update compression is incorporated. In this paper, we propose FedSynSAM, which leverages the global model trajectory to construct synthetic data and facilitates an accurate estimation of the global perturbation. The convergence of the proposed algorithm is established, and extensive experiments are conducted to validate its effectiveness.
Differentially Private and Communication Efficient Large Language Model Split Inference via Stochastic Quantization and Soft Prompt
Feb 12, 2026Large Language Models (LLMs) have achieved remarkable performance and received significant research interest. The enormous computational demands, however, hinder the local deployment on devices with limited resources. The current prevalent LLM inference paradigms require users to send queries to the service providers for processing, which raises critical privacy concerns. Existing approaches propose to allow the users to obfuscate the token embeddings before transmission and utilize local models for denoising. Nonetheless, transmitting the token embeddings and deploying local models may result in excessive communication and computation overhead, preventing practical implementation. In this work, we propose \textbf{DEL}, a framework for \textbf{D}ifferentially private and communication \textbf{E}fficient \textbf{L}LM split inference. More specifically, an embedding projection module and a differentially private stochastic quantization mechanism are proposed to reduce the communication overhead in a privacy-preserving manner. To eliminate the need for local models, we adapt soft prompt at the server side to compensate for the utility degradation caused by privacy. To the best of our knowledge, this is the first work that utilizes soft prompt to improve the trade-off between privacy and utility in LLM inference, and extensive experiments on text generation and natural language understanding benchmarks demonstrate the effectiveness of the proposed method.
Diffusion-aided Extreme Video Compression with Lightweight Semantics Guidance
Feb 05, 2026Modern video codecs and learning-based approaches struggle for semantic reconstruction at extremely low bit-rates due to reliance on low-level spatiotemporal redundancies. Generative models, especially diffusion models, offer a new paradigm for video compression by leveraging high-level semantic understanding and powerful visual synthesis. This paper propose a video compression framework that integrates generative priors to drastically reduce bit-rate while maintaining reconstruction fidelity. Specifically, our method compresses high-level semantic representations of the video, then uses a conditional diffusion model to reconstruct frames from these semantics. To further improve compression, we characterize motion information with global camera trajectories and foreground segmentation: background motion is compactly represented by camera pose parameters while foreground dynamics by sparse segmentation masks. This allows for significantly boosts compression efficiency, enabling descent video reconstruction at extremely low bit-rates.
Mobility-Assisted Decentralized Federated Learning: Convergence Analysis and A Data-Driven Approach
Dec 31, 2025Decentralized Federated Learning (DFL) has emerged as a privacy-preserving machine learning paradigm that enables collaborative training among users without relying on a central server. However, its performance often degrades significantly due to limited connectivity and data heterogeneity. As we move toward the next generation of wireless networks, mobility is increasingly embedded in many real-world applications. The user mobility, either natural or induced, enables clients to act as relays or bridges, thus enhancing information flow in sparse networks; however, its impact on DFL has been largely overlooked despite its potential. In this work, we systematically investigate the role of mobility in improving DFL performance. We first establish the convergence of DFL in sparse networks under user mobility and theoretically demonstrate that even random movement of a fraction of users can significantly boost performance. Building upon this insight, we propose a DFL framework that utilizes mobile users with induced mobility patterns, allowing them to exploit the knowledge of data distribution to determine their trajectories to enhance information propagation through the network. Through extensive experiments, we empirically confirm our theoretical findings, validate the superiority of our approach over baselines, and provide a comprehensive analysis of how various network parameters influence DFL performance in mobile networks.
Byzantine Outside, Curious Inside: Reconstructing Data Through Malicious Updates
Jun 13, 2025Federated learning (FL) enables decentralized machine learning without sharing raw data, allowing multiple clients to collaboratively learn a global model. However, studies reveal that privacy leakage is possible under commonly adopted FL protocols. In particular, a server with access to client gradients can synthesize data resembling the clients' training data. In this paper, we introduce a novel threat model in FL, named the maliciously curious client, where a client manipulates its own gradients with the goal of inferring private data from peers. This attacker uniquely exploits the strength of a Byzantine adversary, traditionally aimed at undermining model robustness, and repurposes it to facilitate data reconstruction attack. We begin by formally defining this novel client-side threat model and providing a theoretical analysis that demonstrates its ability to achieve significant reconstruction success during FL training. To demonstrate its practical impact, we further develop a reconstruction algorithm that combines gradient inversion with malicious update strategies. Our analysis and experimental results reveal a critical blind spot in FL defenses: both server-side robust aggregation and client-side privacy mechanisms may fail against our proposed attack. Surprisingly, standard server- and client-side defenses designed to enhance robustness or privacy may unintentionally amplify data leakage. Compared to the baseline approach, a mistakenly used defense may instead improve the reconstructed image quality by 10-15%.
Distribution-Aware Mobility-Assisted Decentralized Federated Learning
May 24, 2025Decentralized federated learning (DFL) has attracted significant attention due to its scalability and independence from a central server. In practice, some participating clients can be mobile, yet the impact of user mobility on DFL performance remains largely unexplored, despite its potential to facilitate communication and model convergence. In this work, we demonstrate that introducing a small fraction of mobile clients, even with random movement, can significantly improve the accuracy of DFL by facilitating information flow. To further enhance performance, we propose novel distribution-aware mobility patterns, where mobile clients strategically navigate the network, leveraging knowledge of data distributions and static client locations. The proposed moving strategies mitigate the impact of data heterogeneity and boost learning convergence. Extensive experiments validate the effectiveness of induced mobility in DFL and demonstrate the superiority of our proposed mobility patterns over random movement.
Wireless Large AI Model: Shaping the AI-Native Future of 6G and Beyond
Apr 20, 2025The emergence of sixth-generation and beyond communication systems is expected to fundamentally transform digital experiences through introducing unparalleled levels of intelligence, efficiency, and connectivity. A promising technology poised to enable this revolutionary vision is the wireless large AI model (WLAM), characterized by its exceptional capabilities in data processing, inference, and decision-making. In light of these remarkable capabilities, this paper provides a comprehensive survey of WLAM, elucidating its fundamental principles, diverse applications, critical challenges, and future research opportunities. We begin by introducing the background of WLAM and analyzing the key synergies with wireless networks, emphasizing the mutual benefits. Subsequently, we explore the foundational characteristics of WLAM, delving into their unique relevance in wireless environments. Then, the role of WLAM in optimizing wireless communication systems across various use cases and the reciprocal benefits are systematically investigated. Furthermore, we discuss the integration of WLAM with emerging technologies, highlighting their potential to enable transformative capabilities and breakthroughs in wireless communication. Finally, we thoroughly examine the high-level challenges hindering the practical implementation of WLAM and discuss pivotal future research directions.
Analogical Learning for Cross-Scenario Generalization: Framework and Application to Intelligent Localization
Apr 09, 2025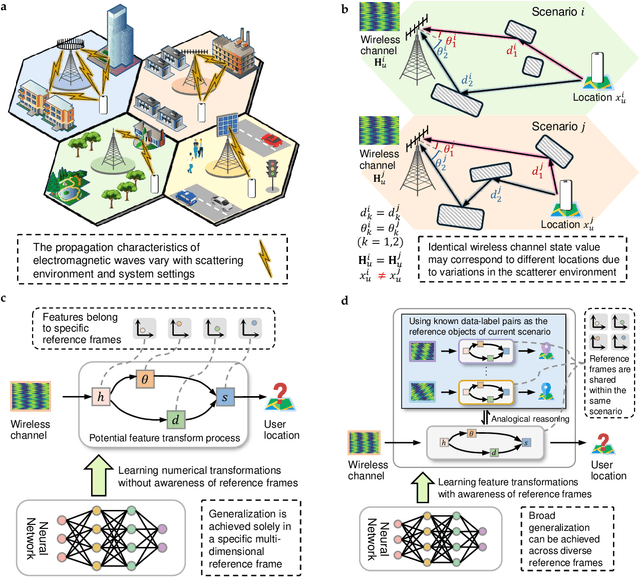
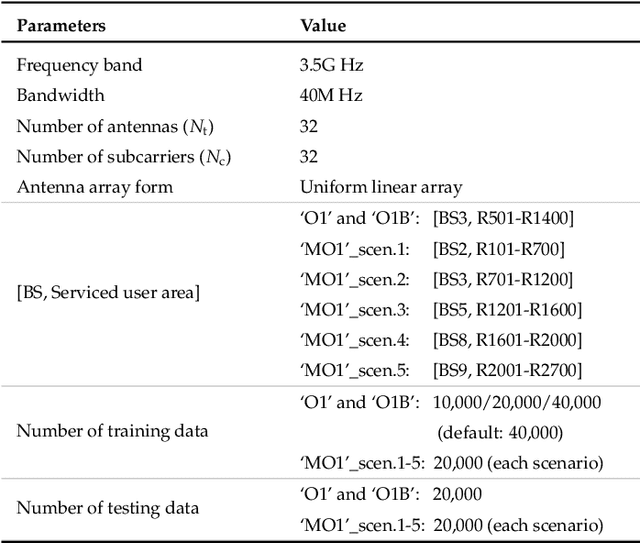
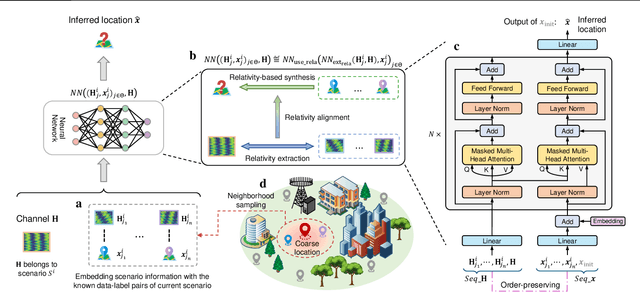

Existing learning models often exhibit poor generalization when deployed across diverse scenarios. It is mainly due to that the underlying reference frame of the data varies with the deployment environment and settings. However, despite the data of each scenario has its distinct reference frame, its generation generally follows the same underlying physical rule. Based on these findings, this article proposes a brand-new universal deep learning framework named analogical learning (AL), which provides a highly efficient way to implicitly retrieve the reference frame information associated with a scenario and then to make accurate prediction by relative analogy across scenarios. Specifically, an elegant bipartite neural network architecture called Mateformer is designed, the first part of which calculates the relativity within multiple feature spaces between the input data and a small amount of embedded data from the current scenario, while the second part uses these relativity to guide the nonlinear analogy. We apply AL to the typical multi-scenario learning problem of intelligent wireless localization in cellular networks. Extensive experiments show that AL achieves state-of-the-art accuracy, stable transferability and robust adaptation to new scenarios without any tuning, and outperforming conventional methods with a precision improvement of nearly two orders of magnitude. All data and code are available at https://github.com/ziruichen-research/ALLoc.
GSBA$^K$: $top$-$K$ Geometric Score-based Black-box Attack
Mar 18, 2025Existing score-based adversarial attacks mainly focus on crafting $top$-1 adversarial examples against classifiers with single-label classification. Their attack success rate and query efficiency are often less than satisfactory, particularly under small perturbation requirements; moreover, the vulnerability of classifiers with multi-label learning is yet to be studied. In this paper, we propose a comprehensive surrogate free score-based attack, named \b geometric \b score-based \b black-box \b attack (GSBA$^K$), to craft adversarial examples in an aggressive $top$-$K$ setting for both untargeted and targeted attacks, where the goal is to change the $top$-$K$ predictions of the target classifier. We introduce novel gradient-based methods to find a good initial boundary point to attack. Our iterative method employs novel gradient estimation techniques, particularly effective in $top$-$K$ setting, on the decision boundary to effectively exploit the geometry of the decision boundary. Additionally, GSBA$^K$ can be used to attack against classifiers with $top$-$K$ multi-label learning. Extensive experimental results on ImageNet and PASCAL VOC datasets validate the effectiveness of GSBA$^K$ in crafting $top$-$K$ adversarial examples.
GSBAK$^K$: $top$-$K$ Geometric Score-based Black-box Attack
Mar 17, 2025Existing score-based adversarial attacks mainly focus on crafting $top$-1 adversarial examples against classifiers with single-label classification. Their attack success rate and query efficiency are often less than satisfactory, particularly under small perturbation requirements; moreover, the vulnerability of classifiers with multi-label learning is yet to be studied. In this paper, we propose a comprehensive surrogate free score-based attack, named \b geometric \b score-based \b black-box \b attack (GSBAK$^K$), to craft adversarial examples in an aggressive $top$-$K$ setting for both untargeted and targeted attacks, where the goal is to change the $top$-$K$ predictions of the target classifier. We introduce novel gradient-based methods to find a good initial boundary point to attack. Our iterative method employs novel gradient estimation techniques, particularly effective in $top$-$K$ setting, on the decision boundary to effectively exploit the geometry of the decision boundary. Additionally, GSBAK$^K$ can be used to attack against classifiers with $top$-$K$ multi-label learning. Extensive experimental results on ImageNet and PASCAL VOC datasets validate the effectiveness of GSBAK$^K$ in crafting $top$-$K$ adversarial examples.