 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Quality Assessment Model Based on Mixture of Experts: System-Level Performance Enhancement and Utterance-Level Challenge Analysis
Jul 08, 2025Automatic speech quality assessment plays a crucial role in the development of speech synthesis systems, but existing models exhibit significant performance variations across different granularity levels of prediction tasks. This paper proposes an enhanced MOS prediction system based on self-supervised learning speech models, incorporating a Mixture of Experts (MoE) classification head and utilizing synthetic data from multiple commercial generation models for data augmentation. Our method builds upon existing self-supervised models such as wav2vec2, designing a specialized MoE architecture to address different types of speech quality assessment tasks. We also collected a large-scale synthetic speech dataset encompassing the latest text-to-speech, speech conversion, and speech enhancement systems. However, despite the adoption of the MoE architecture and expanded dataset, the model's performance improvements in sentence-level prediction tasks remain limited. Our work reveals the limitations of current methods in handling sentence-level quality assessment, provides new technical pathways for the field of automatic speech quality assessment, and also delves into the fundamental causes of performance differences across different assessment granularities.
KunLunBaizeRAG: Reinforcement Learning Driven Inference Performance Leap for Large Language Models
Jun 24, 2025This paper introduces KunLunBaizeRAG, a reinforcement learning-driven reasoning framework designed to enhance the reasoning capabilities of large language models (LLMs) in complex multi-hop question-answering tasks. The framework addresses key limitations of traditional RAG, such as retrieval drift, information redundancy, and strategy rigidity. Key innovations include the RAG-driven Reasoning Alignment (RDRA) mechanism, the Search-Think Iterative Enhancement (STIE) mechanism, the Network-Local Intelligent Routing (NLR) mechanism, and a progressive hybrid training strategy. Experimental results demonstrate significant improvements in exact match (EM) and LLM-judged score (LJ) across four benchmarks, highlighting the framework's robustness and effectiveness in complex reasoning scenarios.
Wireless Large AI Model: Shaping the AI-Native Future of 6G and Beyond
Apr 20, 2025The emergence of sixth-generation and beyond communication systems is expected to fundamentally transform digital experiences through introducing unparalleled levels of intelligence, efficiency, and connectivity. A promising technology poised to enable this revolutionary vision is the wireless large AI model (WLAM), characterized by its exceptional capabilities in data processing, inference, and decision-making. In light of these remarkable capabilities, this paper provides a comprehensive survey of WLAM, elucidating its fundamental principles, diverse applications, critical challenges, and future research opportunities. We begin by introducing the background of WLAM and analyzing the key synergies with wireless networks, emphasizing the mutual benefits. Subsequently, we explore the foundational characteristics of WLAM, delving into their unique relevance in wireless environments. Then, the role of WLAM in optimizing wireless communication systems across various use cases and the reciprocal benefits are systematically investigated. Furthermore, we discuss the integration of WLAM with emerging technologies, highlighting their potential to enable transformative capabilities and breakthroughs in wireless communication. Finally, we thoroughly examine the high-level challenges hindering the practical implementation of WLAM and discuss pivotal future research directions.
SchemaAgent: A Multi-Agents Framework for Generating Relational Database Schema
Mar 31, 2025The relational database design would output a schema based on user's requirements, which defines table structures and their interrelated relations. Translating requirements into accurate schema involves several non-trivial subtasks demanding both database expertise and domain-specific knowledge. This poses unique challenges for automated design of relational databases. Existing efforts are mostly based on customized rules or conventional deep learning models, often producing suboptimal schema. Recently, large language models (LLMs) have significantly advanced intelligent application development across various domains. In this paper, we propose SchemaAgent, a unified LLM-based multi-agent framework for the automated generation of high-quality database schema. SchemaAgent is the first to apply LLMs for schema generation, which emulates the workflow of manual schema design by assigning specialized roles to agents and enabling effective collaboration to refine their respective subtasks. Schema generation is a streamlined workflow, where directly applying the multi-agent framework may cause compounding impact of errors. To address this, we incorporate dedicated roles for reflection and inspection, alongside an innovative error detection and correction mechanism to identify and rectify issues across various phases. For evaluation, we present a benchmark named \textit{RSchema}, which contains more than 500 pairs of requirement description and schema. Experimental results on this benchmark demonstrate the superiority of our approach over mainstream LLMs for relational database schema generation.
Video-VoT-R1: An efficient video inference model integrating image packing and AoE architecture
Mar 20, 2025In the field of video-language pretraining, existing models face numerous challenges in terms of inference efficiency and multimodal data processing. This paper proposes a KunLunBaize-VoT-R1 video inference model based on a long-sequence image encoder, along with its training and application methods. By integrating image packing technology, the Autonomy-of-Experts (AoE) architecture, and combining the video of Thought (VoT), a large language model (LLM) trained with large-scale reinforcement learning, and multiple training techniques, the efficiency and accuracy of the model in video inference tasks are effectively improved. Experiments show that this model performs outstandingly in multiple tests, providing a new solution for video-language understanding.
MoChat: Joints-Grouped Spatio-Temporal Grounding LLM for Multi-Turn Motion Comprehension and Description
Oct 15, 2024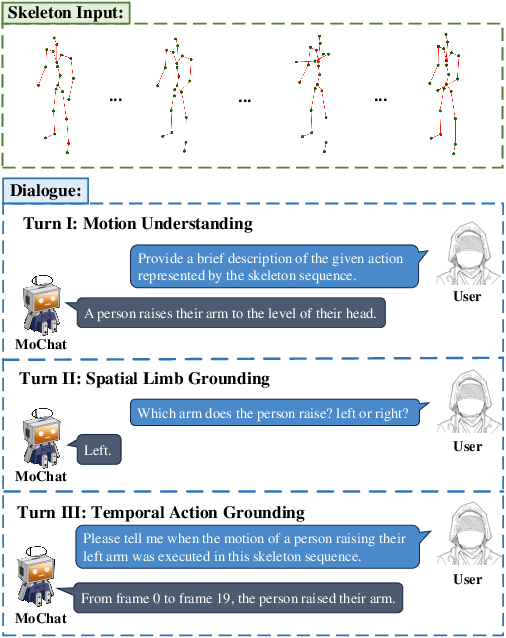
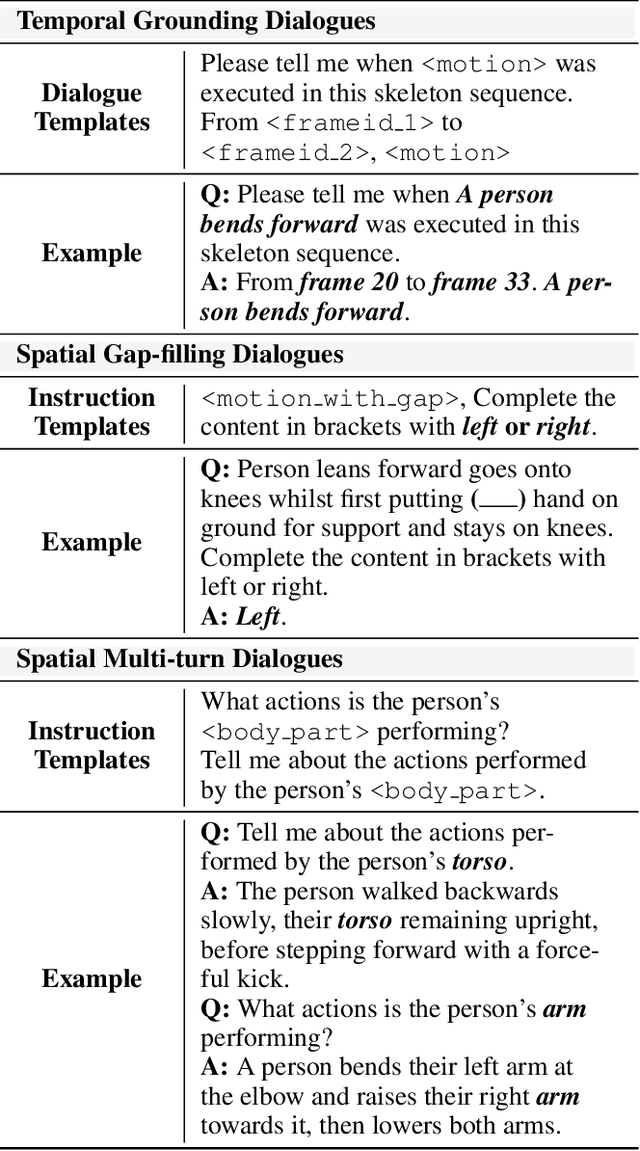
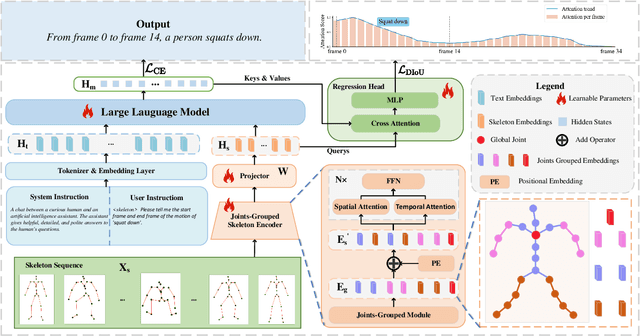

Despite continuous advancements in deep learning for understanding human motion, existing models often struggle to accurately identify action timing and specific body parts, typically supporting only single-round interaction. Such limitations in capturing fine-grained motion details reduce their effectiveness in motion understanding tasks. In this paper, we propose MoChat, a multimodal large language model capable of spatio-temporal grounding of human motion and understanding multi-turn dialogue context. To achieve these capabilities, we group the spatial information of each skeleton frame based on human anatomical structure and then apply them with Joints-Grouped Skeleton Encoder, whose outputs are combined with LLM embeddings to create spatio-aware and temporal-aware embeddings separately. Additionally, we develop a pipeline for extracting timestamps from skeleton sequences based on textual annotations, and construct multi-turn dialogues for spatially grounding. Finally, various task instructions are generated for jointly training. Experimental results demonstrate that MoChat achieves state-of-the-art performance across multiple metrics in motion understanding tasks, making it as the first model capable of fine-grained spatio-temporal grounding of human motion.
Large Language Model-Based Agents for Software Engineering: A Survey
Sep 04, 2024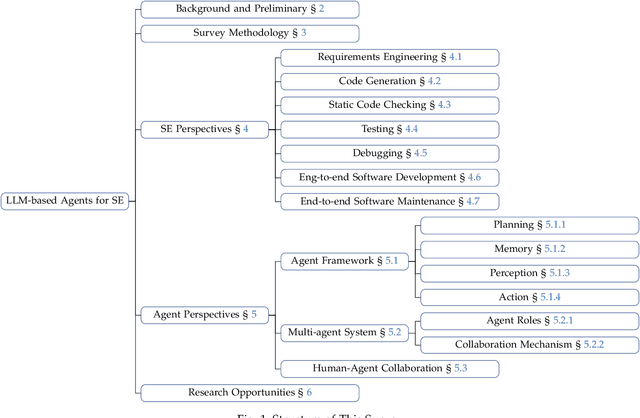



The recent advance in Large Language Models (LLMs) has shaped a new paradigm of AI agents, i.e., LLM-based agents. Compared to standalone LLMs, LLM-based agents substantially extend the versatility and expertise of LLMs by enhancing LLMs with the capabilities of perceiving and utilizing external resources and tools. To date, LLM-based agents have been applied and shown remarkable effectiveness in Software Engineering (SE). The synergy between multiple agents and human interaction brings further promise in tackling complex real-world SE problems. In this work, we present a comprehensive and systematic survey on LLM-based agents for SE. We collect 106 papers and categorize them from two perspectives, i.e., the SE and agent perspectives. In addition, we discuss open challenges and future directions in this critical domain. The repository of this survey is at https://github.com/FudanSELab/Agent4SE-Paper-List.
Joint Beamforming and Antenna Design for Near-Field Fluid Antenna System
Jul 08, 2024
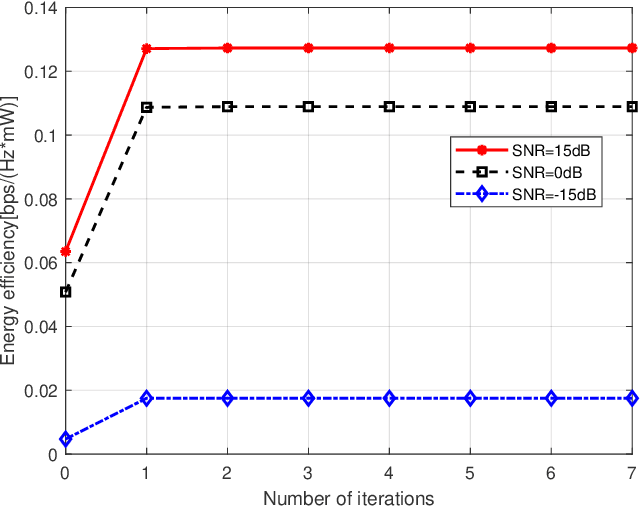
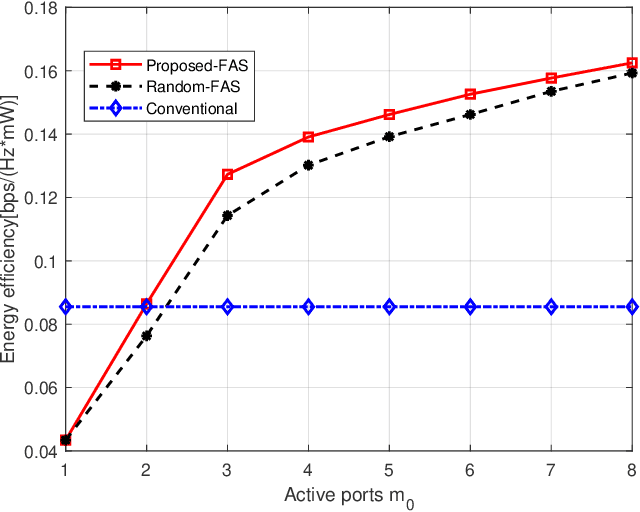
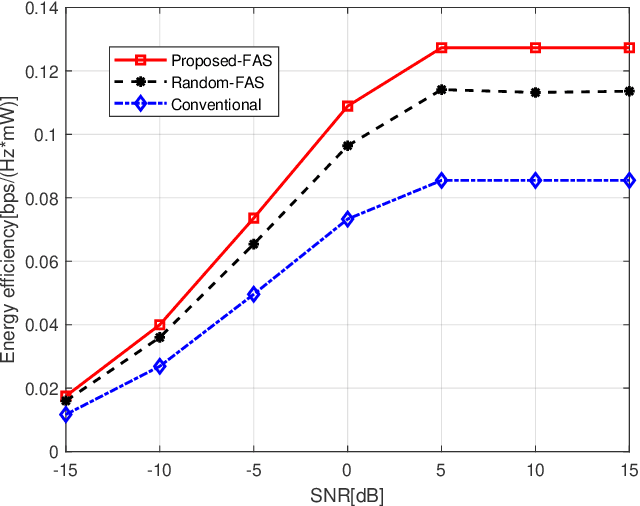
In this letter, we study the energy efficiency maximization problem for a fluid antenna system (FAS) in near field communications. Specifically, we consider a point-to-point near-field system where the base station (BS) transmitter has multiple fixed-position antennas and the user receives the signals with multiple fluid antennas. Our objective is to jointly optimize the transmit beamforming of the BS and the fluid antenna positions at the user for maximizing the energy efficiency. Our scheme is based on an alternating optimization algorithm that iteratively solves the beamforming and antenna position subproblems. Our simulation results validate the performance improvement of the proposed algorithm and confirm the effectiveness of FAS.
Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models
May 13, 2024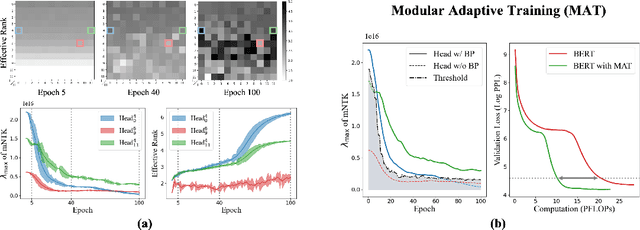

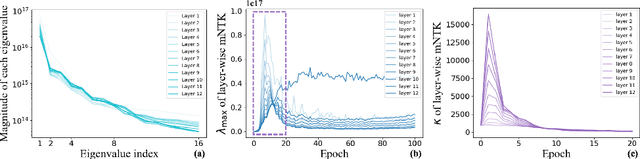

Despite their prevalence in deep-learning communities, over-parameterized models convey high demands of computational costs for proper training. This work studies the fine-grained, modular-level learning dynamics of over-parameterized models to attain a more efficient and fruitful training strategy. Empirical evidence reveals that when scaling down into network modules, such as heads in self-attention models, we can observe varying learning patterns implicitly associated with each module's trainability. To describe such modular-level learning capabilities, we introduce a novel concept dubbed modular neural tangent kernel (mNTK), and we demonstrate that the quality of a module's learning is tightly associated with its mNTK's principal eigenvalue $\lambda_{\max}$. A large $\lambda_{\max}$ indicates that the module learns features with better convergence, while those miniature ones may impact generalization negatively. Inspired by the discovery, we propose a novel training strategy termed Modular Adaptive Training (MAT) to update those modules with their $\lambda_{\max}$ exceeding a dynamic threshold selectively, concentrating the model on learning common features and ignoring those inconsistent ones. Unlike most existing training schemes with a complete BP cycle across all network modules, MAT can significantly save computations by its partially-updating strategy and can further improve performance. Experiments show that MAT nearly halves the computational cost of model training and outperforms the accuracy of baselines.
Fluid Antenna Relay Assisted Communication Systems Through Antenna Location Optimization
Mar 31, 2024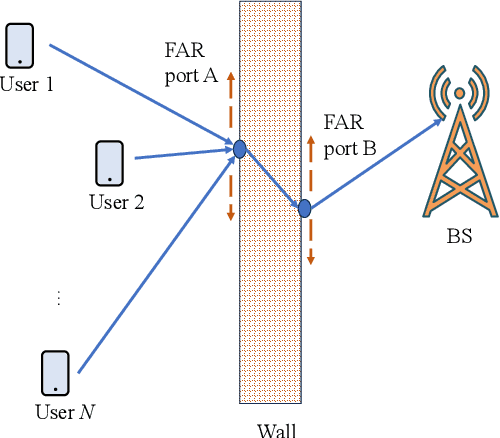
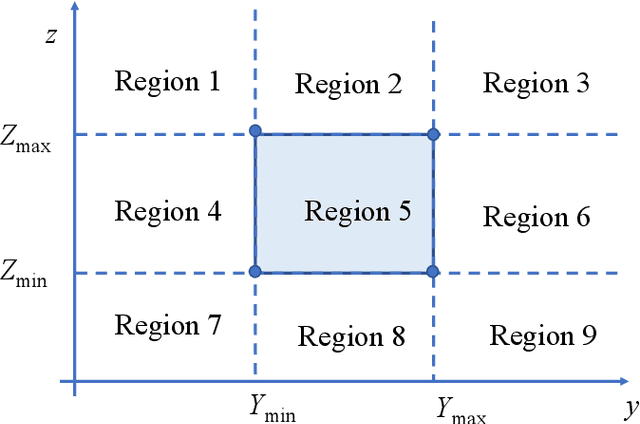
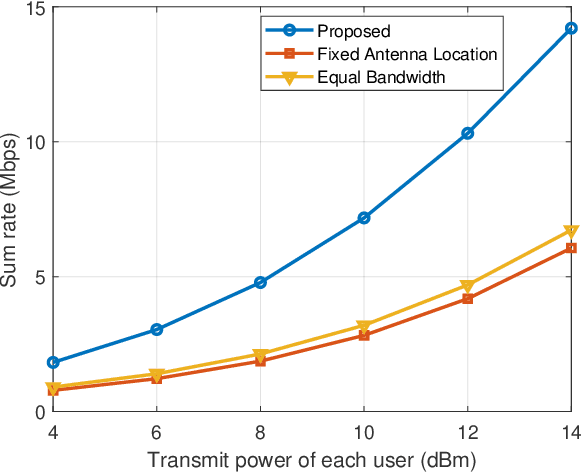
In this paper, we investigate the problem of resource allocation for fluid antenna relay (FAR) system with antenna location optimization. In the considered model, each user transmits information to a base station (BS) with help of FAR. The antenna location of the FAR is flexible and can be adapted to dynamic location distribution of the users. We formulate a sum rate maximization problem through jointly optimizing the antenna location and bandwidth allocation with meeting the minimum rate requirements, total bandwidth budget, and feasible antenna region constraints. To solve this problem, we obtain the optimal bandwidth in closed form. Based on the optimal bandwidth, the original problem is reduced to the antenna location optimization problem and an alternating algorithm is proposed. Simulation results verify the effectiveness of the proposed algorithm and the sum rate can be increased by up to 125% compared to the conventional schemes.