 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeachingCoach: A Fine-Tuned Scaffolding Chatbot for Instructional Guidance to Instructors
Mar 18, 2026Higher education instructors often lack timely and pedagogically grounded support, as scalable instructional guidance remains limited and existing tools rely on generic chatbot advice or non-scalable teaching center human-human consultations. We present TeachingCoach, a pedagogically grounded chatbot designed to support instructor professional development through real-time, conversational guidance. TeachingCoach is built on a data-centric pipeline that extracts pedagogical rules from educational resources and uses synthetic dialogue generation to fine-tune a specialized language model that guides instructors through problem identification, diagnosis, and strategy development. Expert evaluations show TeachingCoach produces clearer, more reflective, and more responsive guidance than a GPT-4o mini baseline, while a user study with higher education instructors highlights trade-offs between conversational depth and interaction efficiency. Together, these results demonstrate that pedagogically grounded, synthetic data driven chatbots can improve instructional support and offer a scalable design approach for future instructional chatbot systems.
Automated Benchmark Generation from Domain Guidelines Informed by Bloom's Taxonomy
Jan 28, 2026Open-ended question answering (QA) evaluates a model's ability to perform contextualized reasoning beyond factual recall. This challenge is especially acute in practice-based domains, where knowledge is procedural and grounded in professional judgment, while most existing LLM benchmarks depend on pre-existing human exam datasets that are often unavailable in such settings. We introduce a framework for automated benchmark generation from expert-authored guidelines informed by Bloom's Taxonomy. It converts expert practices into implicit violation-based scenarios and expands them into auto-graded multiple-choice questions (MCQs) and multi-turn dialogues across four cognitive levels, enabling deterministic, reproducible, and scalable evaluation. Applied to three applied domains: teaching, dietetics, and caregiving, we find differences between model and human-like reasoning: LLMs sometimes perform relatively better on higher-order reasoning (Analyze) but fail more frequently on lower-level items (Remember). We produce large-scale, psychometrically informed benchmarks that surface these non-intuitive model behaviors and enable evaluation of contextualized reasoning in real-world settings.
Aligning LLMs for the Classroom with Knowledge-Based Retrieval -- A Comparative RAG Study
Sep 09, 2025



Large language models like ChatGPT are increasingly used in classrooms, but they often provide outdated or fabricated information that can mislead students. Retrieval Augmented Generation (RAG) improves reliability of LLMs by grounding responses in external resources. We investigate two accessible RAG paradigms, vector-based retrieval and graph-based retrieval to identify best practices for classroom question answering (QA). Existing comparative studies fail to account for pedagogical factors such as educational disciplines, question types, and practical deployment costs. Using a novel dataset, EduScopeQA, of 3,176 questions across academic subjects, we measure performance on various educational query types, from specific facts to broad thematic discussions. We also evaluate system alignment with a dataset of systematically altered textbooks that contradict the LLM's latent knowledge. We find that OpenAI Vector Search RAG (representing vector-based RAG) performs well as a low-cost generalist, especially for quick fact retrieval. On the other hand, GraphRAG Global excels at providing pedagogically rich answers to thematic queries, and GraphRAG Local achieves the highest accuracy with the dense, altered textbooks when corpus integrity is critical. Accounting for the 10-20x higher resource usage of GraphRAG (representing graph-based RAG), we show that a dynamic branching framework that routes queries to the optimal retrieval method boosts fidelity and efficiency. These insights provide actionable guidelines for educators and system designers to integrate RAG-augmented LLMs into learning environments effectively.
CTR-Driven Ad Text Generation via Online Feedback Preference Optimization
Jul 27, 2025Advertising text plays a critical role in determining click-through rates (CTR) in online advertising. Large Language Models (LLMs) offer significant efficiency advantages over manual ad text creation. However, LLM-generated ad texts do not guarantee higher CTR performance compared to human-crafted texts, revealing a gap between generation quality and online performance of ad texts. In this work, we propose a novel ad text generation method which optimizes for CTR through preference optimization from online feedback. Our approach adopts an innovative two-stage framework: (1) diverse ad text sampling via one-shot in-context learning, using retrieval-augmented generation (RAG) to provide exemplars with chain-of-thought (CoT) reasoning; (2) CTR-driven preference optimization from online feedback, which weighs preference pairs according to their CTR gains and confidence levels. Through our method, the resulting model enables end-to-end generation of high-CTR ad texts. Extensive experiments have demonstrated the effectiveness of our method in both offline and online metrics. Notably, we have applied our method on a large-scale online shopping platform and achieved significant CTR improvements, showcasing its strong applicability and effectiveness in advertising systems.
BioChemInsight: An Open-Source Toolkit for Automated Identification and Recognition of Optical Chemical Structures and Activity Data in Scientific Publications
Apr 12, 2025Automated extraction of chemical structures and their bioactivity data is crucial for accelerating drug discovery and enabling data-driven pharmaceutical research. Existing optical chemical structure recognition (OCSR) tools fail to autonomously associate molecular structures with their bioactivity profiles, creating a critical bottleneck in structure-activity relationship (SAR) analysis. Here, we present BioChemInsight, an open-source pipeline that integrates: (1) DECIMER Segmentation and MolVec for chemical structure recognition, (2) Qwen2.5-VL-32B for compound identifier association, and (3) PaddleOCR with Gemini-2.0-flash for bioactivity extraction and unit normalization. We evaluated the performance of BioChemInsight on 25 patents and 17 articles. BioChemInsight achieved 95% accuracy for tabular patent data (structure/identifier recognition), with lower accuracy in non-tabular patents (~80% structures, ~75% identifiers), plus 92.2 % bioactivity extraction accuracy. For articles, it attained >99% identifiers and 78-80% structure accuracy in non-tabular formats, plus 97.4% bioactivity extraction accuracy. The system generates ready-to-use SAR datasets, reducing data preprocessing time from weeks to hours while enabling applications in high-throughput screening and ML-driven drug design (https://github.com/dahuilangda/BioChemInsight).
Strategize Globally, Adapt Locally: A Multi-Turn Red Teaming Agent with Dual-Level Learning
Apr 02, 2025The exploitation of large language models (LLMs) for malicious purposes poses significant security risks as these models become more powerful and widespread. While most existing red-teaming frameworks focus on single-turn attacks, real-world adversaries typically operate in multi-turn scenarios, iteratively probing for vulnerabilities and adapting their prompts based on threat model responses. In this paper, we propose \AlgName, a novel multi-turn red-teaming agent that emulates sophisticated human attackers through complementary learning dimensions: global tactic-wise learning that accumulates knowledge over time and generalizes to new attack goals, and local prompt-wise learning that refines implementations for specific goals when initial attempts fail. Unlike previous multi-turn approaches that rely on fixed strategy sets, \AlgName enables the agent to identify new jailbreak tactics, develop a goal-based tactic selection framework, and refine prompt formulations for selected tactics. Empirical evaluations on JailbreakBench demonstrate our framework's superior performance, achieving over 90\% attack success rates against GPT-3.5-Turbo and Llama-3.1-70B within 5 conversation turns, outperforming state-of-the-art baselines. These results highlight the effectiveness of dynamic learning in identifying and exploiting model vulnerabilities in realistic multi-turn scenarios.
SchemaAgent: A Multi-Agents Framework for Generating Relational Database Schema
Mar 31, 2025The relational database design would output a schema based on user's requirements, which defines table structures and their interrelated relations. Translating requirements into accurate schema involves several non-trivial subtasks demanding both database expertise and domain-specific knowledge. This poses unique challenges for automated design of relational databases. Existing efforts are mostly based on customized rules or conventional deep learning models, often producing suboptimal schema. Recently, large language models (LLMs) have significantly advanced intelligent application development across various domains. In this paper, we propose SchemaAgent, a unified LLM-based multi-agent framework for the automated generation of high-quality database schema. SchemaAgent is the first to apply LLMs for schema generation, which emulates the workflow of manual schema design by assigning specialized roles to agents and enabling effective collaboration to refine their respective subtasks. Schema generation is a streamlined workflow, where directly applying the multi-agent framework may cause compounding impact of errors. To address this, we incorporate dedicated roles for reflection and inspection, alongside an innovative error detection and correction mechanism to identify and rectify issues across various phases. For evaluation, we present a benchmark named \textit{RSchema}, which contains more than 500 pairs of requirement description and schema. Experimental results on this benchmark demonstrate the superiority of our approach over mainstream LLMs for relational database schema generation.
Towards reliable respiratory disease diagnosis based on cough sounds and vision transformers
Sep 03, 2024Recent advancements in deep learning techniques have sparked performance boosts in various real-world applications including disease diagnosis based on multi-modal medical data. Cough sound data-based respiratory disease (e.g., COVID-19 and Chronic Obstructive Pulmonary Disease) diagnosis has also attracted much attention. However, existing works usually utilise traditional machine learning or deep models of moderate scales. On the other hand, the developed approaches are trained and evaluated on small-scale data due to the difficulty of curating and annotating clinical data on scale. To address these issues in prior works, we create a unified framework to evaluate various deep models from lightweight Convolutional Neural Networks (e.g., ResNet18) to modern vision transformers and compare their performance in respiratory disease classification. Based on the observations from such an extensive empirical study, we propose a novel approach to cough-based disease classification based on both self-supervised and supervised learning on a large-scale cough data set. Experimental results demonstrate our proposed approach outperforms prior arts consistently on two benchmark datasets for COVID-19 diagnosis and a proprietary dataset for COPD/non-COPD classification with an AUROC of 92.5%.
AutoScale: Automatic Prediction of Compute-optimal Data Composition for Training LLMs
Jul 29, 2024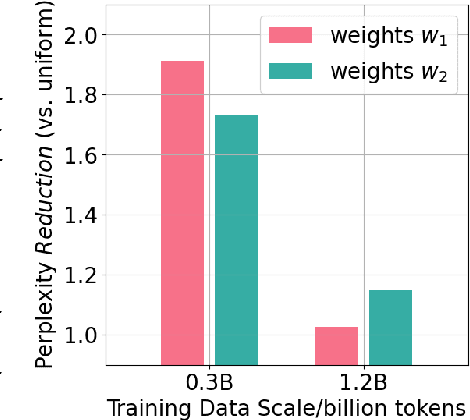
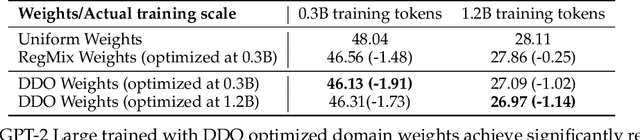
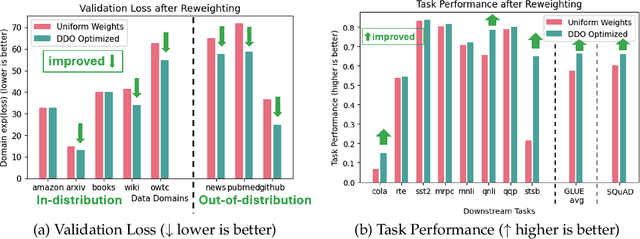
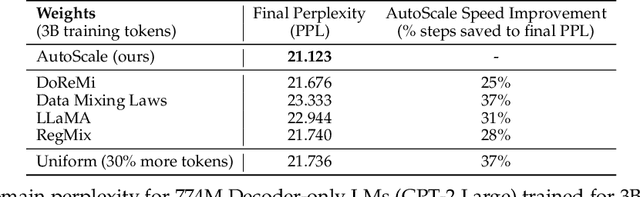
To ensure performance on a diverse set of downstream tasks, LLMs are pretrained via data mixtures over different domains. In this work, we demonstrate that the optimal data composition for a fixed compute budget varies depending on the scale of the training data, suggesting that the common practice of empirically determining an optimal composition using small-scale experiments will not yield the optimal data mixtures when scaling up to the final model. To address this challenge, we propose *AutoScale*, an automated tool that finds a compute-optimal data composition for training at any desired target scale. AutoScale first determines the optimal composition at a small scale using a novel bilevel optimization framework, Direct Data Optimization (*DDO*), and then fits a predictor to estimate the optimal composition at larger scales. The predictor's design is inspired by our theoretical analysis of scaling laws related to data composition, which could be of independent interest. In empirical studies with pre-training 774M Decoder-only LMs (GPT-2 Large) on RedPajama dataset, AutoScale decreases validation perplexity at least 25% faster than any baseline with up to 38% speed up compared to without reweighting, achieving the best overall performance across downstream tasks. On pre-training Encoder-only LMs (BERT) with masked language modeling, DDO is shown to decrease loss on all domains while visibly improving average task performance on GLUE benchmark by 8.7% and on large-scale QA dataset (SQuAD) by 5.9% compared with without reweighting. AutoScale speeds up training by up to 28%. Our codes are open-sourced.
The 2nd FutureDial Challenge: Dialog Systems with Retrieval Augmented Generation (FutureDial-RAG)
May 21, 2024The 2nd FutureDial Challenge: Dialog Systems with Retrieval Augmented Generation (FutureDial-RAG), Co-located with SLT 2024