 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training
Jul 02, 2025Reinforcement learning (RL) has become a pivotal technology in the post-training phase of large language models (LLMs). Traditional task-colocated RL frameworks suffer from significant scalability bottlenecks, while task-separated RL frameworks face challenges in complex dataflows and the corresponding resource idling and workload imbalance. Moreover, most existing frameworks are tightly coupled with LLM training or inference engines, making it difficult to support custom-designed engines. To address these challenges, we propose AsyncFlow, an asynchronous streaming RL framework for efficient post-training. Specifically, we introduce a distributed data storage and transfer module that provides a unified data management and fine-grained scheduling capability in a fully streamed manner. This architecture inherently facilitates automated pipeline overlapping among RL tasks and dynamic load balancing. Moreover, we propose a producer-consumer-based asynchronous workflow engineered to minimize computational idleness by strategically deferring parameter update process within staleness thresholds. Finally, the core capability of AsynFlow is architecturally decoupled from underlying training and inference engines and encapsulated by service-oriented user interfaces, offering a modular and customizable user experience. Extensive experiments demonstrate an average of 1.59 throughput improvement compared with state-of-the-art baseline. The presented architecture in this work provides actionable insights for next-generation RL training system designs.
BioChemInsight: An Open-Source Toolkit for Automated Identification and Recognition of Optical Chemical Structures and Activity Data in Scientific Publications
Apr 12, 2025Automated extraction of chemical structures and their bioactivity data is crucial for accelerating drug discovery and enabling data-driven pharmaceutical research. Existing optical chemical structure recognition (OCSR) tools fail to autonomously associate molecular structures with their bioactivity profiles, creating a critical bottleneck in structure-activity relationship (SAR) analysis. Here, we present BioChemInsight, an open-source pipeline that integrates: (1) DECIMER Segmentation and MolVec for chemical structure recognition, (2) Qwen2.5-VL-32B for compound identifier association, and (3) PaddleOCR with Gemini-2.0-flash for bioactivity extraction and unit normalization. We evaluated the performance of BioChemInsight on 25 patents and 17 articles. BioChemInsight achieved 95% accuracy for tabular patent data (structure/identifier recognition), with lower accuracy in non-tabular patents (~80% structures, ~75% identifiers), plus 92.2 % bioactivity extraction accuracy. For articles, it attained >99% identifiers and 78-80% structure accuracy in non-tabular formats, plus 97.4% bioactivity extraction accuracy. The system generates ready-to-use SAR datasets, reducing data preprocessing time from weeks to hours while enabling applications in high-throughput screening and ML-driven drug design (https://github.com/dahuilangda/BioChemInsight).
Act Better by Timing: A timing-Aware Reinforcement Learning for Autonomous Driving
Jun 19, 2024


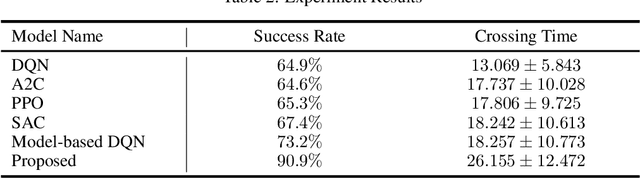
Coping with intensively interactive scenarios is one of the significant challenges in the development of autonomous driving. Reinforcement learning (RL) offers an ideal solution for such scenarios through its self-evolution mechanism via interaction with the environment. However, the lack of sufficient safety mechanisms in common RL leads to the fact that agent often find it difficult to interact well in highly dynamic environment and may collide in pursuit of short-term rewards. Much of the existing safe RL methods require environment modeling to generate reliable safety boundaries that constrain agent behavior. Nevertheless, acquiring such safety boundaries is not always feasible in dynamic environments. Inspired by the driver's behavior of acting when uncertainty is minimal, this study introduces the concept of action timing to replace explicit safety boundary modeling. We define "actor" as an agent to decide optimal action at each step. By imaging the actor take opportunity to act as a timing-dependent gradual process, the other agent called "timing taker" can evaluate the optimal action execution time, and relate the optimal timing to each action moment as a dynamic safety factor to constrain the actor's action. In the experiment involving a complex, unsignaled intersection interaction, this framework achieved superior safety performance compared to all benchmark models.
Brain-on-Switch: Towards Advanced Intelligent Network Data Plane via NN-Driven Traffic Analysis at Line-Speed
Mar 17, 2024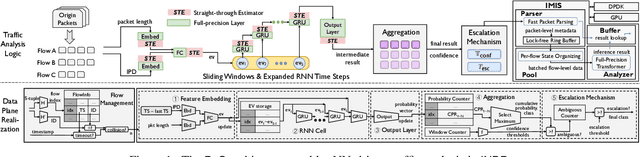
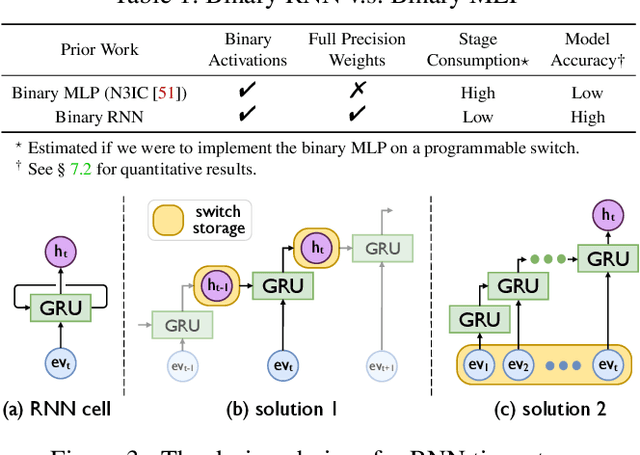
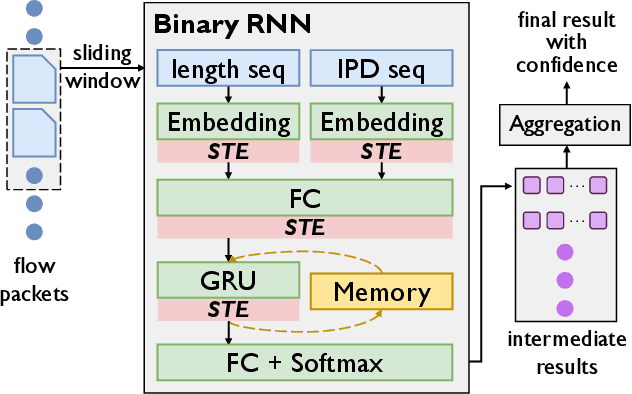
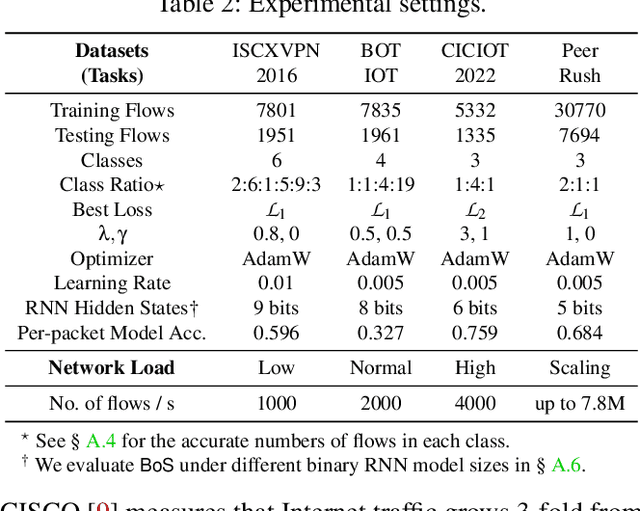
The emerging programmable networks sparked significant research on Intelligent Network Data Plane (INDP), which achieves learning-based traffic analysis at line-speed. Prior art in INDP focus on deploying tree/forest models on the data plane. We observe a fundamental limitation in tree-based INDP approaches: although it is possible to represent even larger tree/forest tables on the data plane, the flow features that are computable on the data plane are fundamentally limited by hardware constraints. In this paper, we present BoS to push the boundaries of INDP by enabling Neural Network (NN) driven traffic analysis at line-speed. Many types of NNs (such as Recurrent Neural Network (RNN), and transformers) that are designed to work with sequential data have advantages over tree-based models, because they can take raw network data as input without complex feature computations on the fly. However, the challenge is significant: the recurrent computation scheme used in RNN inference is fundamentally different from the match-action paradigm used on the network data plane. BoS addresses this challenge by (i) designing a novel data plane friendly RNN architecture that can execute unlimited RNN time steps with limited data plane stages, effectively achieving line-speed RNN inference; and (ii) complementing the on-switch RNN model with an off-switch transformer-based traffic analysis module to further boost the overall performance. We implement a prototype of BoS using a P4 programmable switch as our data plane, and extensively evaluate it over multiple traffic analysis tasks. The results show that BoS outperforms state-of-the-art in both analysis accuracy and scalability.
COOR-PLT: A hierarchical control model for coordinating adaptive platoons of connected and autonomous vehicles at signal-free intersections based on deep reinforcement learning
Jul 01, 2022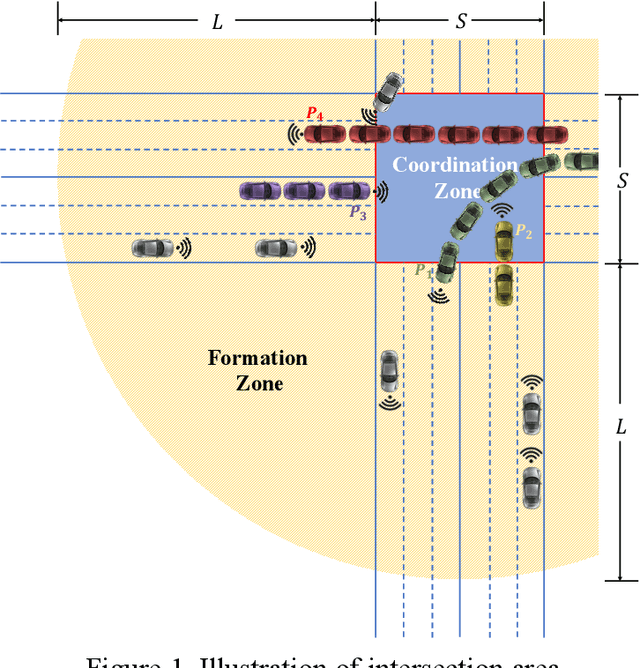

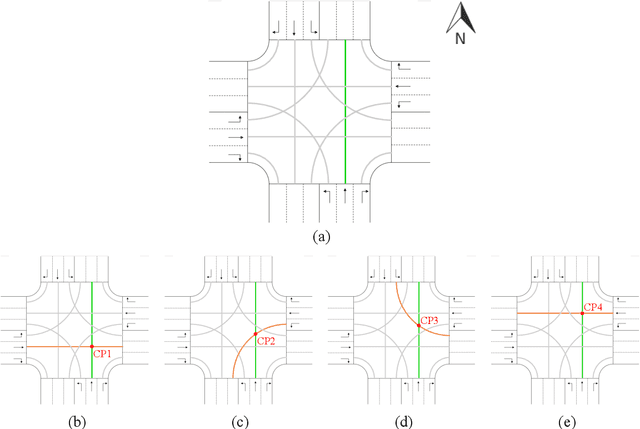
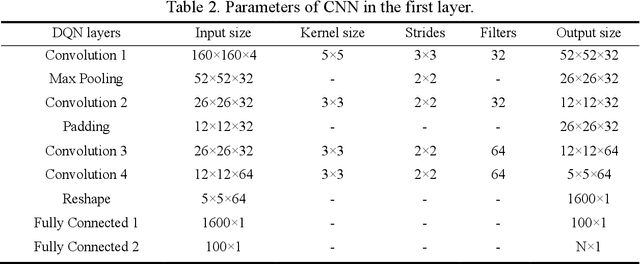
Platooning and coordination are two implementation strategies that are frequently proposed for traffic control of connected and autonomous vehicles (CAVs) at signal-free intersections instead of using conventional traffic signals. However, few studies have attempted to integrate both strategies to better facilitate the CAV control at signal-free intersections. To this end, this study proposes a hierarchical control model, named COOR-PLT, to coordinate adaptive CAV platoons at a signal-free intersection based on deep reinforcement learning (DRL). COOR-PLT has a two-layer framework. The first layer uses a centralized control strategy to form adaptive platoons. The optimal size of each platoon is determined by considering multiple objectives (i.e., efficiency, fairness and energy saving). The second layer employs a decentralized control strategy to coordinate multiple platoons passing through the intersection. Each platoon is labeled with coordinated status or independent status, upon which its passing priority is determined. As an efficient DRL algorithm, Deep Q-network (DQN) is adopted to determine platoon sizes and passing priorities respectively in the two layers. The model is validated and examined on the simulator Simulation of Urban Mobility (SUMO). The simulation results demonstrate that the model is able to: (1) achieve satisfactory convergence performances; (2) adaptively determine platoon size in response to varying traffic conditions; and (3) completely avoid deadlocks at the intersection. By comparison with other control methods, the model manifests its superiority of adopting adaptive platooning and DRL-based coordination strategies. Also, the model outperforms several state-of-the-art methods on reducing travel time and fuel consumption in different traffic conditions.
Modeling Adaptive Platoon and Reservation Based Autonomous Intersection Control: A Deep Reinforcement Learning Approach
Jun 24, 2022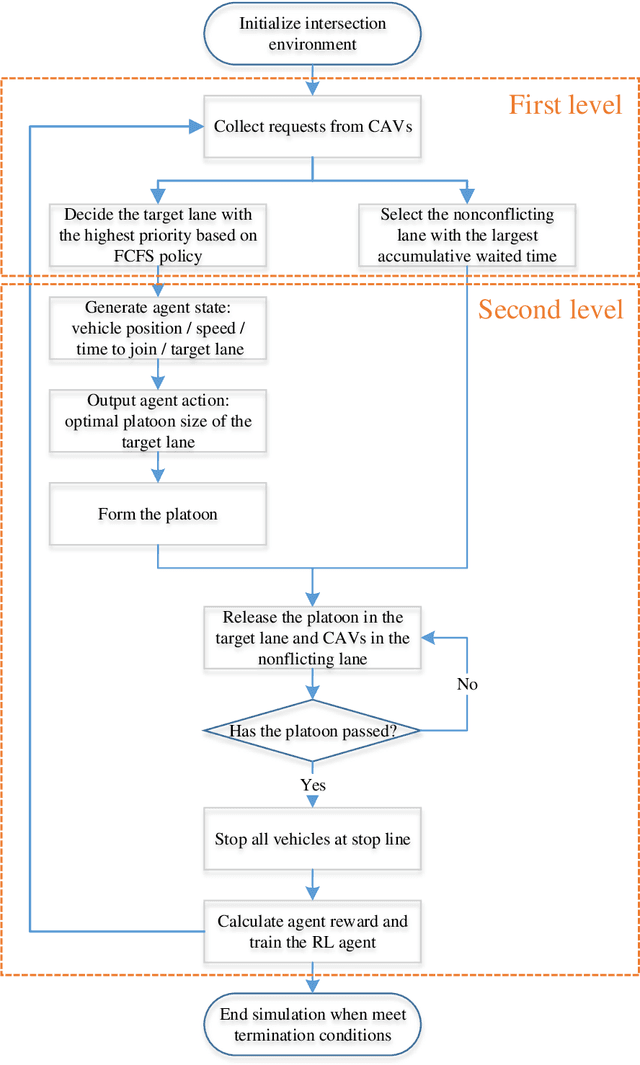
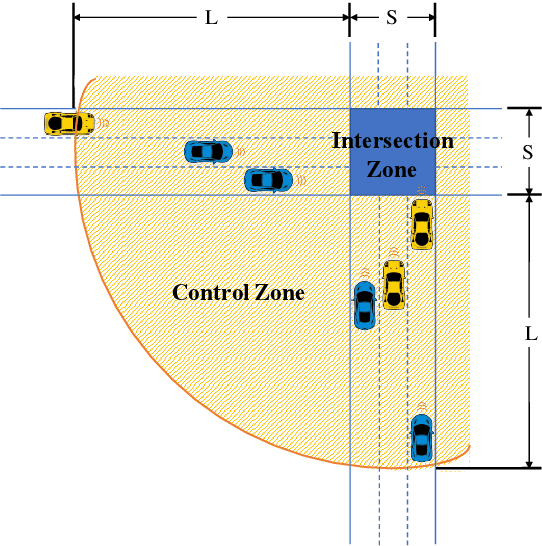
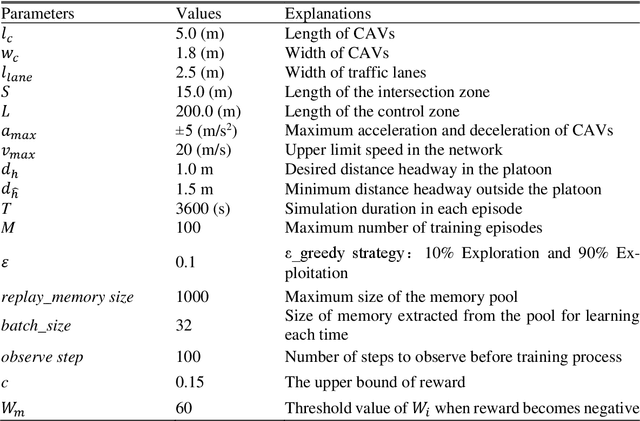
As a strategy to reduce travel delay and enhance energy efficiency, platooning of connected and autonomous vehicles (CAVs) at non-signalized intersections has become increasingly popular in academia. However, few studies have attempted to model the relation between the optimal platoon size and the traffic conditions around the intersection. To this end, this study proposes an adaptive platoon based autonomous intersection control model powered by deep reinforcement learning (DRL) technique. The model framework has following two levels: the first level adopts a First Come First Serve (FCFS) reservation based policy integrated with a nonconflicting lane selection mechanism to determine vehicles' passing priority; and the second level applies a deep Q-network algorithm to identify the optimal platoon size based on the real-time traffic condition of an intersection. When being tested on a traffic micro-simulator, our proposed model exhibits superior performances on travel efficiency and fuel conservation as compared to the state-of-the-art methods.
Weakly-supervised Action Localization via Hierarchical Mining
Jun 22, 2022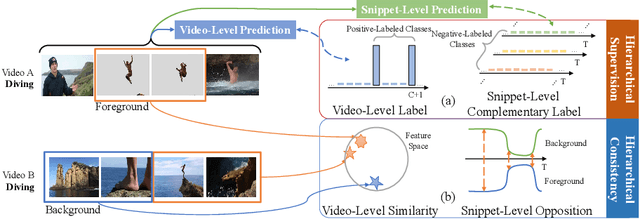
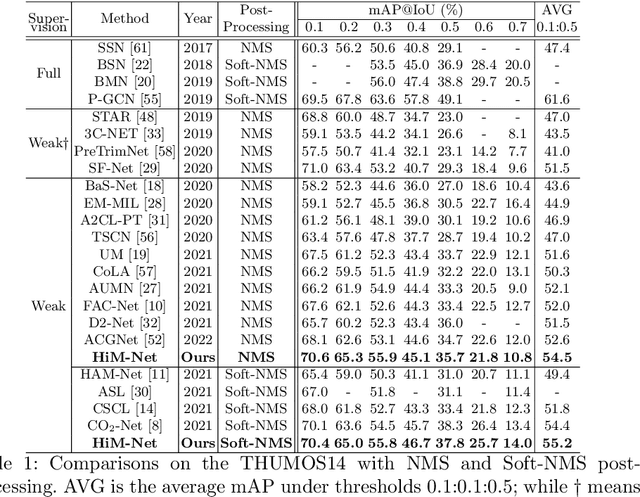
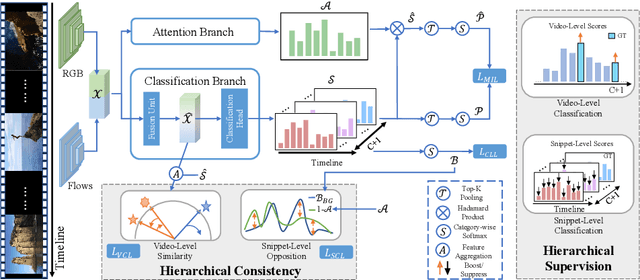
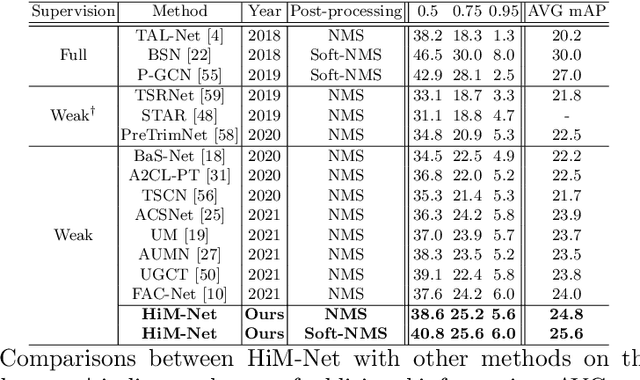
Weakly-supervised action localization aims to localize and classify action instances in the given videos temporally with only video-level categorical labels. Thus, the crucial issue of existing weakly-supervised action localization methods is the limited supervision from the weak annotations for precise predictions. In this work, we propose a hierarchical mining strategy under video-level and snippet-level manners, i.e., hierarchical supervision and hierarchical consistency mining, to maximize the usage of the given annotations and prediction-wise consistency. To this end, a Hierarchical Mining Network (HiM-Net) is proposed. Concretely, it mines hierarchical supervision for classification in two grains: one is the video-level existence for ground truth categories captured by multiple instance learning; the other is the snippet-level inexistence for each negative-labeled category from the perspective of complementary labels, which is optimized by our proposed complementary label learning. As for hierarchical consistency, HiM-Net explores video-level co-action feature similarity and snippet-level foreground-background opposition, for discriminative representation learning and consistent foreground-background separation. Specifically, prediction variance is viewed as uncertainty to select the pairs with high consensus for proposed foreground-background collaborative learning. Comprehensive experimental results show that HiM-Net outperforms existing methods on THUMOS14 and ActivityNet1.3 datasets with large margins by hierarchically mining the supervision and consistency. Code will be available on GitHub.
Masked Image Modeling with Denoising Contrast
May 19, 2022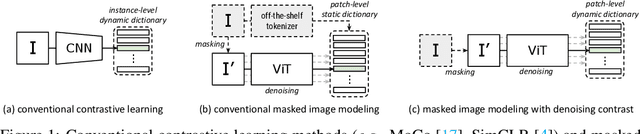
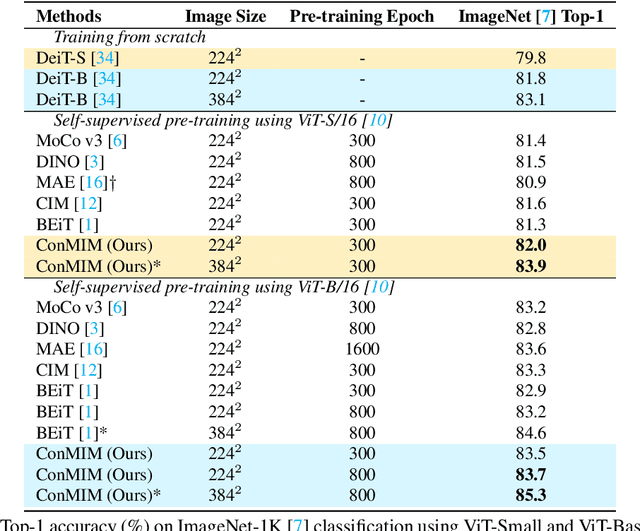
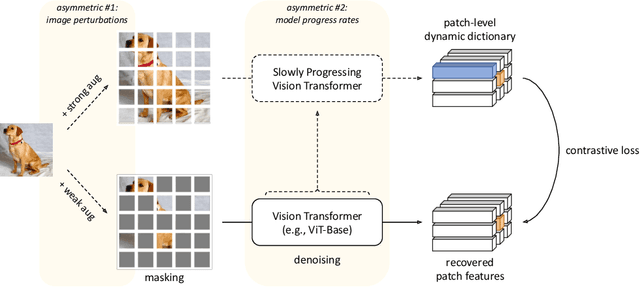

Since the development of self-supervised visual representation learning from contrastive learning to masked image modeling, there is no significant difference in essence, that is, how to design proper pretext tasks for vision dictionary look-up. Masked image modeling recently dominates this line of research with state-of-the-art performance on vision Transformers, where the core is to enhance the patch-level visual context capturing of the network via denoising auto-encoding mechanism. Rather than tailoring image tokenizers with extra training stages as in previous works, we unleash the great potential of contrastive learning on denoising auto-encoding and introduce a new pre-training method, ConMIM, to produce simple intra-image inter-patch contrastive constraints as the learning objectives for masked patch prediction. We further strengthen the denoising mechanism with asymmetric designs, including image perturbations and model progress rates, to improve the network pre-training. ConMIM-pretrained vision Transformers with various scales achieve promising results on downstream image classification, semantic segmentation, object detection, and instance segmentation tasks.
ActorRL: A Novel Distributed Reinforcement Learning for Autonomous Intersection Management
May 05, 2022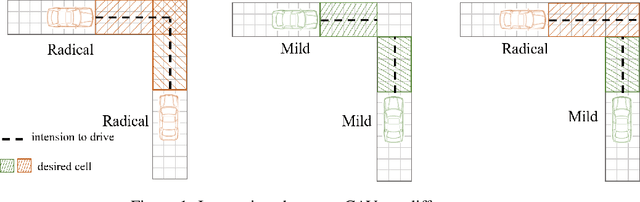
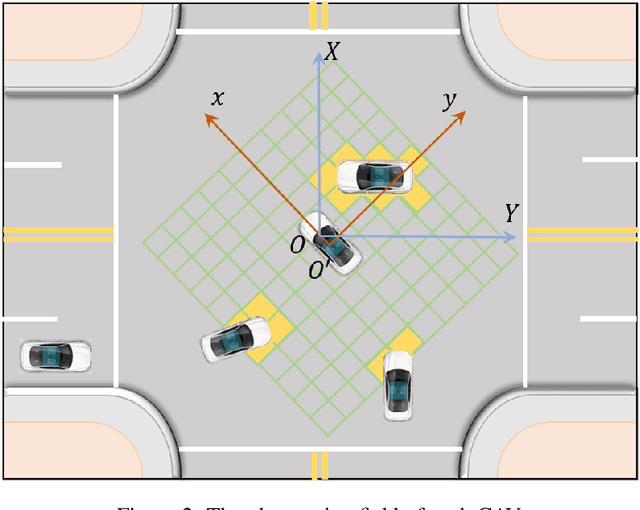

As an emerging tendency of future transportation, Connected Autonomous Vehicle (CAV) has the potential to improve traffic capacity and safety at intersections. In autonomous intersection management (AIM), distributed scheduling algorithm formulates the interactions among traffic participants as multi-agent problem with information exchange and behavioral cooperation. Deep Reinforcement Learning (DRL), as an approach obtaining satisfying performance in many domains, has been brought in AIM recently. Attempts to overcome the challenges of curse of dimensionality and instability in multi-agent DRL, we propose a novel DRL framework for AIM problem, ActorRL, where actor allocation mechanism attaches multiple roles with different personalities to CAVs under global observation, including radical actor, conservative actor, safety-first actor, etc. The actor shares behavioral policies with collective memories from CAVs it is assigned to, playing the role of "navigator" at AIM. In experiments, we compares the proposed method with several widely used scheduling methods and distributed DRL without actor allocation, the results shows better performance over benchmarks.
MILES: Visual BERT Pre-training with Injected Language Semantics for Video-text Retrieval
Apr 26, 2022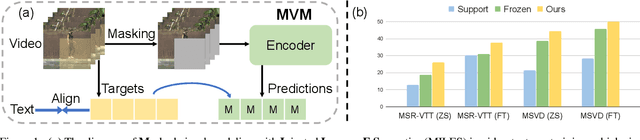
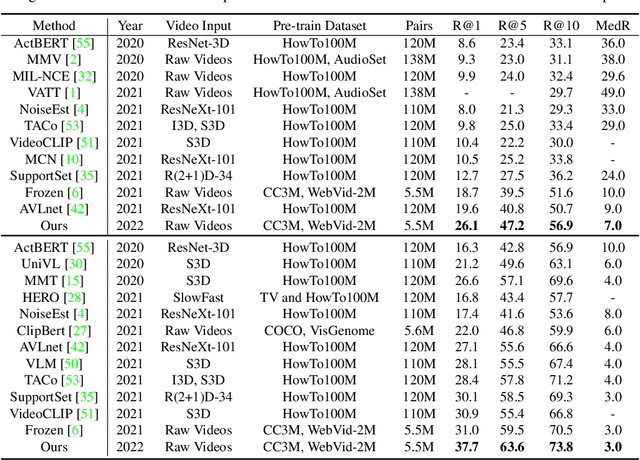
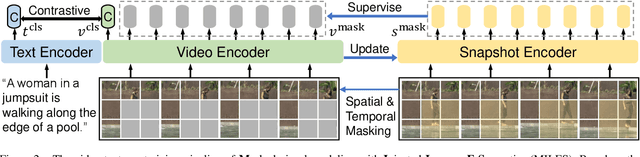
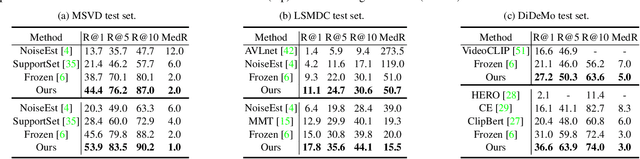
Dominant pre-training work for video-text retrieval mainly adopt the "dual-encoder" architectures to enable efficient retrieval, where two separate encoders are used to contrast global video and text representations, but ignore detailed local semantics. The recent success of image BERT pre-training with masked visual modeling that promotes the learning of local visual context, motivates a possible solution to address the above limitation. In this work, we for the first time investigate masked visual modeling in video-text pre-training with the "dual-encoder" architecture. We perform Masked visual modeling with Injected LanguagE Semantics (MILES) by employing an extra snapshot video encoder as an evolving "tokenizer" to produce reconstruction targets for masked video patch prediction. Given the corrupted video, the video encoder is trained to recover text-aligned features of the masked patches via reasoning with the visible regions along the spatial and temporal dimensions, which enhances the discriminativeness of local visual features and the fine-grained cross-modality alignment. Our method outperforms state-of-the-art methods for text-to-video retrieval on four datasets with both zero-shot and fine-tune evaluation protocols. Our approach also surpasses the baseline models significantly on zero-shot action recognition, which can be cast as video-to-text retrieval.