 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Completeness: A Generalizable Action Proposal Generator for Zero-Shot Temporal Action Localization
Aug 25, 2024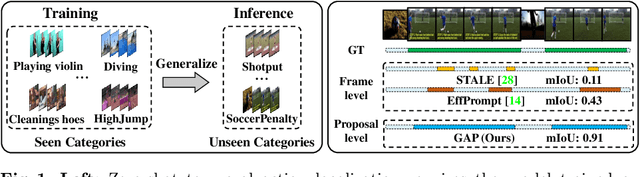
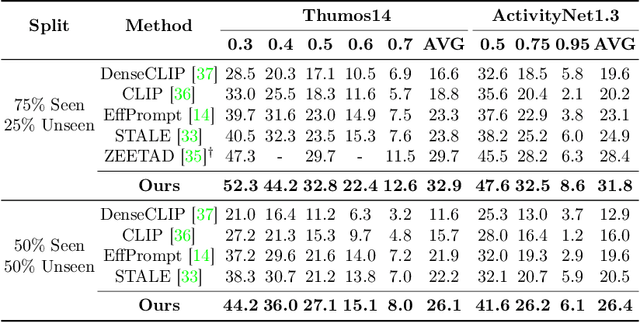
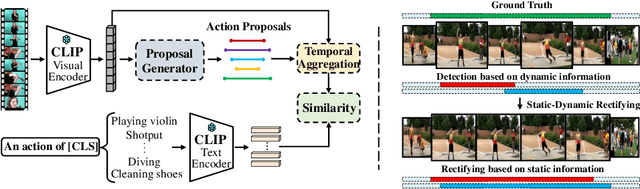

To address the zero-shot temporal action localization (ZSTAL) task, existing works develop models that are generalizable to detect and classify actions from unseen categories. They typically develop a category-agnostic action detector and combine it with the Contrastive Language-Image Pre-training (CLIP) model to solve ZSTAL. However, these methods suffer from incomplete action proposals generated for \textit{unseen} categories, since they follow a frame-level prediction paradigm and require hand-crafted post-processing to generate action proposals. To address this problem, in this work, we propose a novel model named Generalizable Action Proposal generator (GAP), which can interface seamlessly with CLIP and generate action proposals in a holistic way. Our GAP is built in a query-based architecture and trained with a proposal-level objective, enabling it to estimate proposal completeness and eliminate the hand-crafted post-processing. Based on this architecture, we propose an Action-aware Discrimination loss to enhance the category-agnostic dynamic information of actions. Besides, we introduce a Static-Dynamic Rectifying module that incorporates the generalizable static information from CLIP to refine the predicted proposals, which improves proposal completeness in a generalizable manner. Our experiments show that our GAP achieves state-of-the-art performance on two challenging ZSTAL benchmarks, i.e., Thumos14 and ActivityNet1.3. Specifically, our model obtains significant performance improvement over previous works on the two benchmarks, i.e., +3.2% and +3.4% average mAP, respectively.
Diversifying Spatial-Temporal Perception for Video Domain Generalization
Oct 27, 2023



Video domain generalization aims to learn generalizable video classification models for unseen target domains by training in a source domain. A critical challenge of video domain generalization is to defend against the heavy reliance on domain-specific cues extracted from the source domain when recognizing target videos. To this end, we propose to perceive diverse spatial-temporal cues in videos, aiming to discover potential domain-invariant cues in addition to domain-specific cues. We contribute a novel model named Spatial-Temporal Diversification Network (STDN), which improves the diversity from both space and time dimensions of video data. First, our STDN proposes to discover various types of spatial cues within individual frames by spatial grouping. Then, our STDN proposes to explicitly model spatial-temporal dependencies between video contents at multiple space-time scales by spatial-temporal relation modeling. Extensive experiments on three benchmarks of different types demonstrate the effectiveness and versatility of our approach.
Event-Guided Procedure Planning from Instructional Videos with Text Supervision
Aug 17, 2023In this work, we focus on the task of procedure planning from instructional videos with text supervision, where a model aims to predict an action sequence to transform the initial visual state into the goal visual state. A critical challenge of this task is the large semantic gap between observed visual states and unobserved intermediate actions, which is ignored by previous works. Specifically, this semantic gap refers to that the contents in the observed visual states are semantically different from the elements of some action text labels in a procedure. To bridge this semantic gap, we propose a novel event-guided paradigm, which first infers events from the observed states and then plans out actions based on both the states and predicted events. Our inspiration comes from that planning a procedure from an instructional video is to complete a specific event and a specific event usually involves specific actions. Based on the proposed paradigm, we contribute an Event-guided Prompting-based Procedure Planning (E3P) model, which encodes event information into the sequential modeling process to support procedure planning. To further consider the strong action associations within each event, our E3P adopts a mask-and-predict approach for relation mining, incorporating a probabilistic masking scheme for regularization. Extensive experiments on three datasets demonstrate the effectiveness of our proposed model.
Weakly-supervised Action Localization via Hierarchical Mining
Jun 22, 2022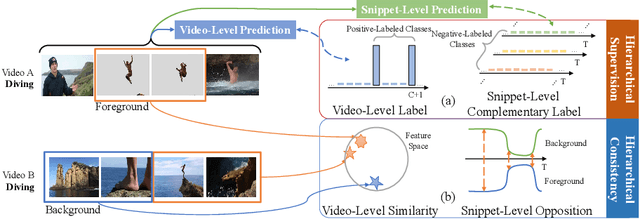
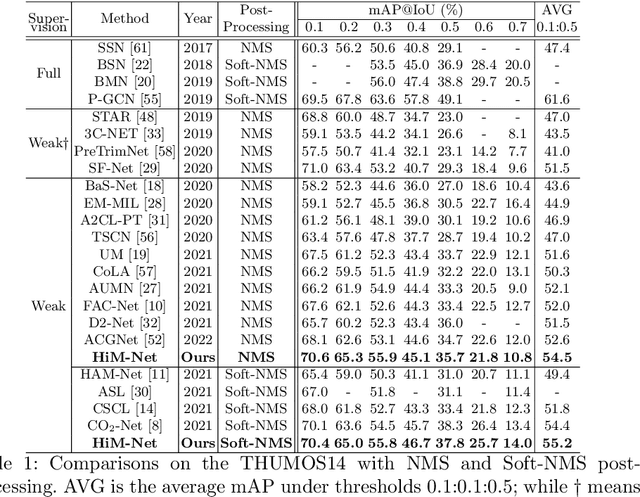
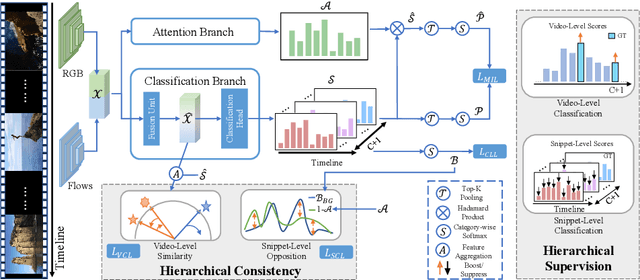
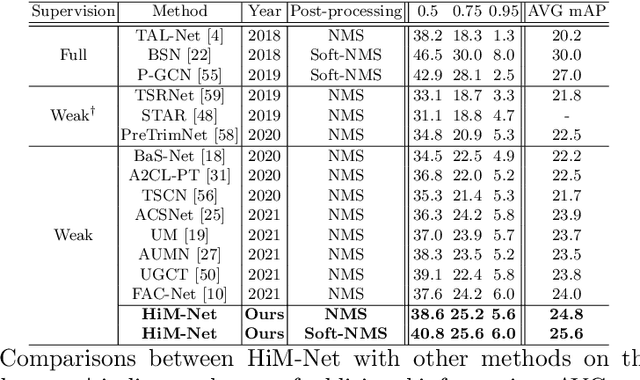
Weakly-supervised action localization aims to localize and classify action instances in the given videos temporally with only video-level categorical labels. Thus, the crucial issue of existing weakly-supervised action localization methods is the limited supervision from the weak annotations for precise predictions. In this work, we propose a hierarchical mining strategy under video-level and snippet-level manners, i.e., hierarchical supervision and hierarchical consistency mining, to maximize the usage of the given annotations and prediction-wise consistency. To this end, a Hierarchical Mining Network (HiM-Net) is proposed. Concretely, it mines hierarchical supervision for classification in two grains: one is the video-level existence for ground truth categories captured by multiple instance learning; the other is the snippet-level inexistence for each negative-labeled category from the perspective of complementary labels, which is optimized by our proposed complementary label learning. As for hierarchical consistency, HiM-Net explores video-level co-action feature similarity and snippet-level foreground-background opposition, for discriminative representation learning and consistent foreground-background separation. Specifically, prediction variance is viewed as uncertainty to select the pairs with high consensus for proposed foreground-background collaborative learning. Comprehensive experimental results show that HiM-Net outperforms existing methods on THUMOS14 and ActivityNet1.3 datasets with large margins by hierarchically mining the supervision and consistency. Code will be available on GitHub.