 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Action Localization via Hierarchical Mining
Jun 22, 2022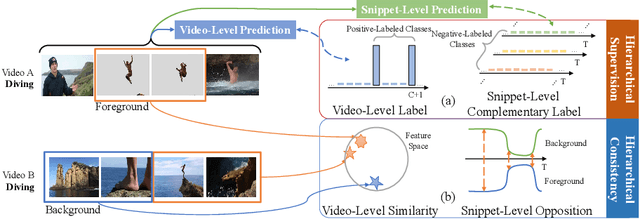
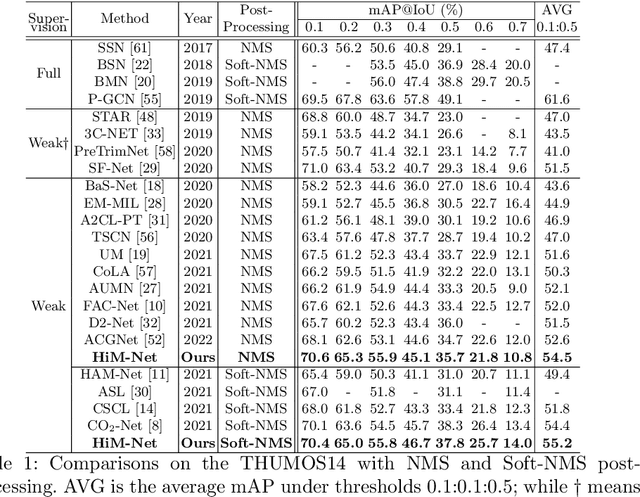
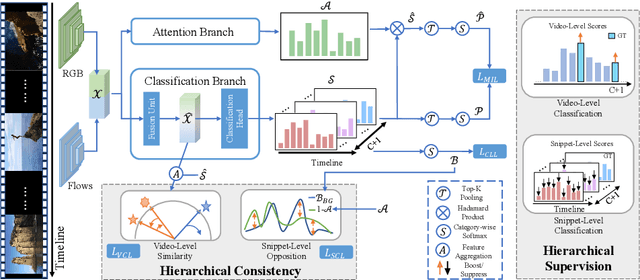
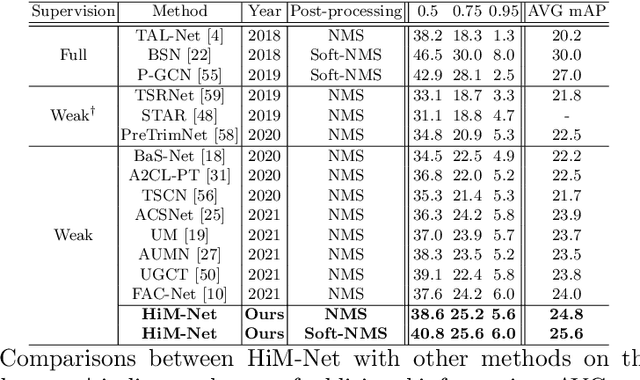
Weakly-supervised action localization aims to localize and classify action instances in the given videos temporally with only video-level categorical labels. Thus, the crucial issue of existing weakly-supervised action localization methods is the limited supervision from the weak annotations for precise predictions. In this work, we propose a hierarchical mining strategy under video-level and snippet-level manners, i.e., hierarchical supervision and hierarchical consistency mining, to maximize the usage of the given annotations and prediction-wise consistency. To this end, a Hierarchical Mining Network (HiM-Net) is proposed. Concretely, it mines hierarchical supervision for classification in two grains: one is the video-level existence for ground truth categories captured by multiple instance learning; the other is the snippet-level inexistence for each negative-labeled category from the perspective of complementary labels, which is optimized by our proposed complementary label learning. As for hierarchical consistency, HiM-Net explores video-level co-action feature similarity and snippet-level foreground-background opposition, for discriminative representation learning and consistent foreground-background separation. Specifically, prediction variance is viewed as uncertainty to select the pairs with high consensus for proposed foreground-background collaborative learning. Comprehensive experimental results show that HiM-Net outperforms existing methods on THUMOS14 and ActivityNet1.3 datasets with large margins by hierarchically mining the supervision and consistency. Code will be available on GitHub.
Cross-modal Consensus Network for Weakly Supervised Temporal Action Localization
Jul 27, 2021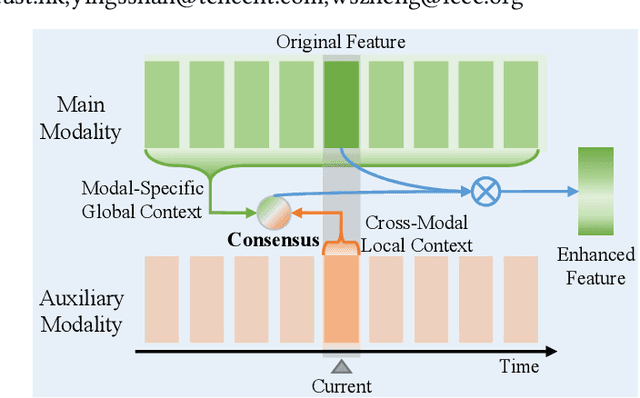
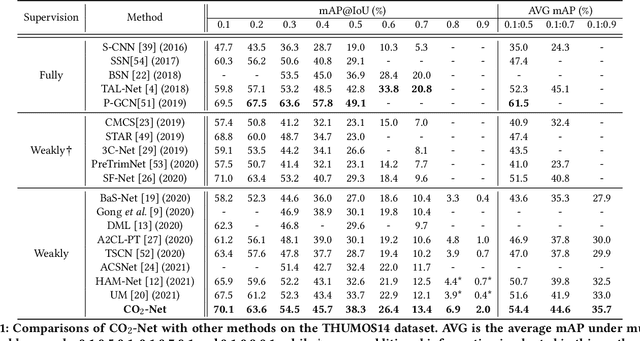
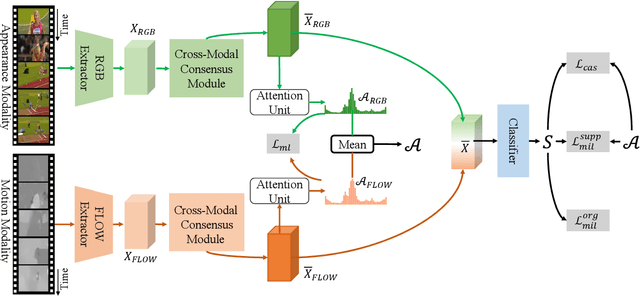
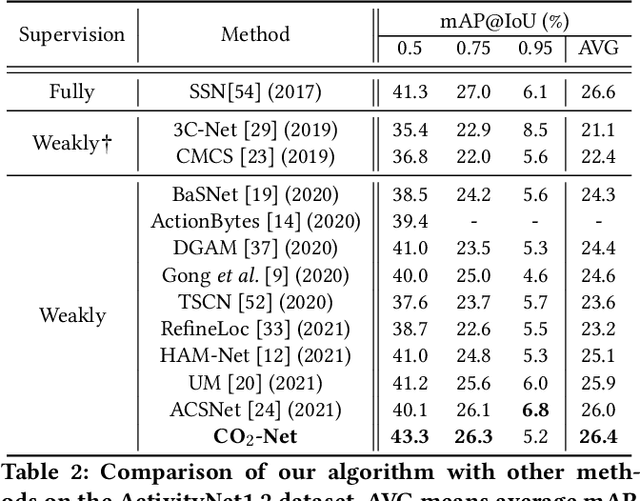
Weakly supervised temporal action localization (WS-TAL) is a challenging task that aims to localize action instances in the given video with video-level categorical supervision. Both appearance and motion features are used in previous works, while they do not utilize them in a proper way but apply simple concatenation or score-level fusion. In this work, we argue that the features extracted from the pretrained extractor, e.g., I3D, are not the WS-TALtask-specific features, thus the feature re-calibration is needed for reducing the task-irrelevant information redundancy. Therefore, we propose a cross-modal consensus network (CO2-Net) to tackle this problem. In CO2-Net, we mainly introduce two identical proposed cross-modal consensus modules (CCM) that design a cross-modal attention mechanism to filter out the task-irrelevant information redundancy using the global information from the main modality and the cross-modal local information of the auxiliary modality. Moreover, we treat the attention weights derived from each CCMas the pseudo targets of the attention weights derived from another CCM to maintain the consistency between the predictions derived from two CCMs, forming a mutual learning manner. Finally, we conduct extensive experiments on two common used temporal action localization datasets, THUMOS14 and ActivityNet1.2, to verify our method and achieve the state-of-the-art results. The experimental results show that our proposed cross-modal consensus module can produce more representative features for temporal action localization.
MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection
Apr 04, 2021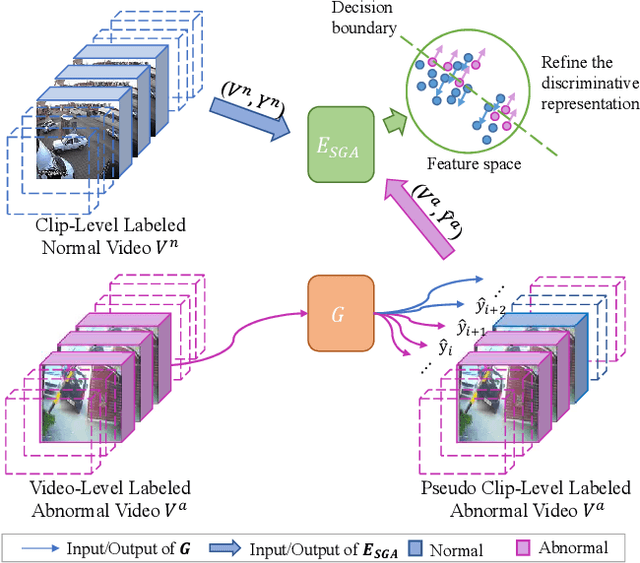
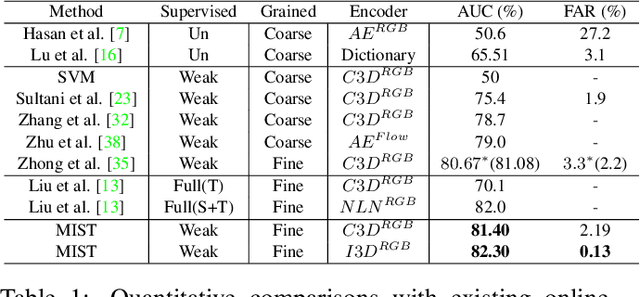
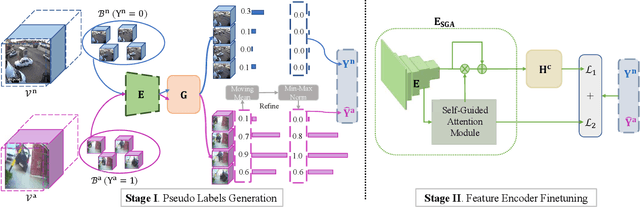

Weakly supervised video anomaly detection (WS-VAD) is to distinguish anomalies from normal events based on discriminative representations. Most existing works are limited in insufficient video representations. In this work, we develop a multiple instance self-training framework (MIST)to efficiently refine task-specific discriminative representations with only video-level annotations. In particular, MIST is composed of 1) a multiple instance pseudo label generator, which adapts a sparse continuous sampling strategy to produce more reliable clip-level pseudo labels, and 2) a self-guided attention boosted feature encoder that aims to automatically focus on anomalous regions in frames while extracting task-specific representations. Moreover, we adopt a self-training scheme to optimize both components and finally obtain a task-specific feature encoder. Extensive experiments on two public datasets demonstrate the efficacy of our method, and our method performs comparably to or even better than existing supervised and weakly supervised methods, specifically obtaining a frame-level AUC 94.83% on ShanghaiTech.