 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniZoomer: Learning to Move and Zoom in on Sphere at High-Resolution
Aug 19, 2023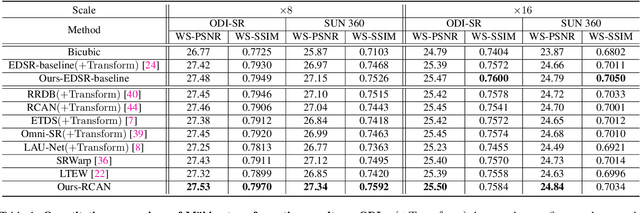
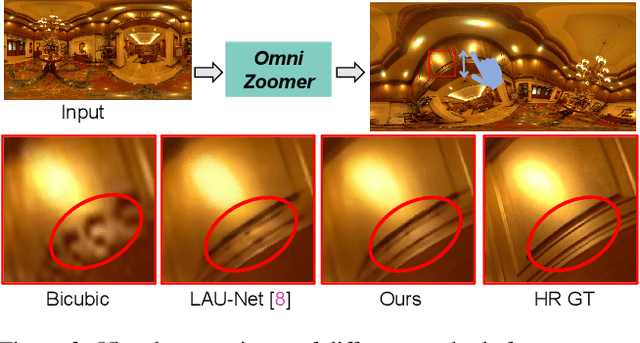
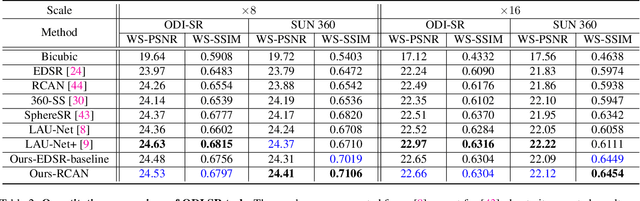
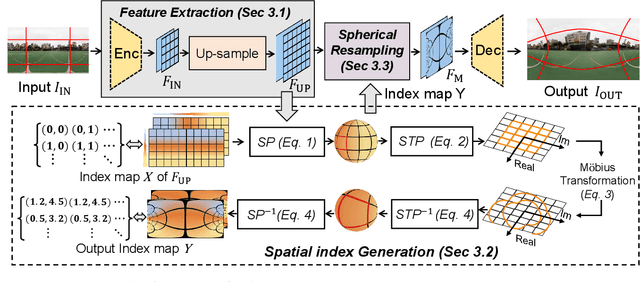
Omnidirectional images (ODIs) have become increasingly popular, as their large field-of-view (FoV) can offer viewers the chance to freely choose the view directions in immersive environments such as virtual reality. The M\"obius transformation is typically employed to further provide the opportunity for movement and zoom on ODIs, but applying it to the image level often results in blurry effect and aliasing problem. In this paper, we propose a novel deep learning-based approach, called \textbf{OmniZoomer}, to incorporate the M\"obius transformation into the network for movement and zoom on ODIs. By learning various transformed feature maps under different conditions, the network is enhanced to handle the increasing edge curvatures, which alleviates the blurry effect. Moreover, to address the aliasing problem, we propose two key components. Firstly, to compensate for the lack of pixels for describing curves, we enhance the feature maps in the high-resolution (HR) space and calculate the transformed index map with a spatial index generation module. Secondly, considering that ODIs are inherently represented in the spherical space, we propose a spherical resampling module that combines the index map and HR feature maps to transform the feature maps for better spherical correlation. The transformed feature maps are decoded to output a zoomed ODI. Experiments show that our method can produce HR and high-quality ODIs with the flexibility to move and zoom in to the object of interest. Project page is available at http://vlislab22.github.io/OmniZoomer/.
HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video
Apr 24, 2023We introduce HOSNeRF, a novel 360{\deg} free-viewpoint rendering method that reconstructs neural radiance fields for dynamic human-object-scene from a single monocular in-the-wild video. Our method enables pausing the video at any frame and rendering all scene details (dynamic humans, objects, and backgrounds) from arbitrary viewpoints. The first challenge in this task is the complex object motions in human-object interactions, which we tackle by introducing the new object bones into the conventional human skeleton hierarchy to effectively estimate large object deformations in our dynamic human-object model. The second challenge is that humans interact with different objects at different times, for which we introduce two new learnable object state embeddings that can be used as conditions for learning our human-object representation and scene representation, respectively. Extensive experiments show that HOSNeRF significantly outperforms SOTA approaches on two challenging datasets by a large margin of 40% ~ 50% in terms of LPIPS. The code, data, and compelling examples of 360{\deg} free-viewpoint renderings from single videos will be released in https://showlab.github.io/HOSNeRF.
MasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing
Apr 17, 2023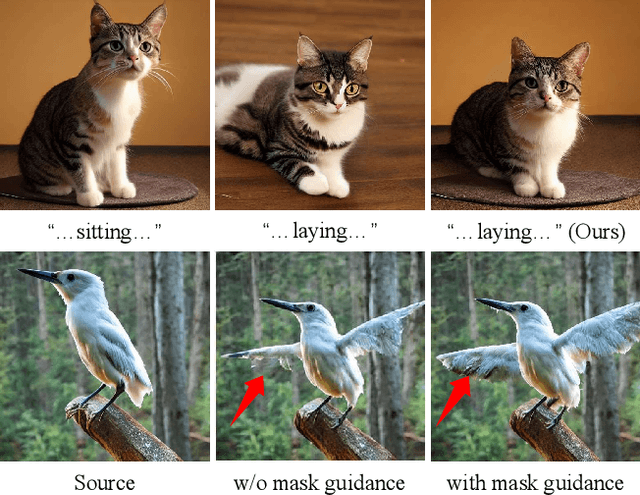
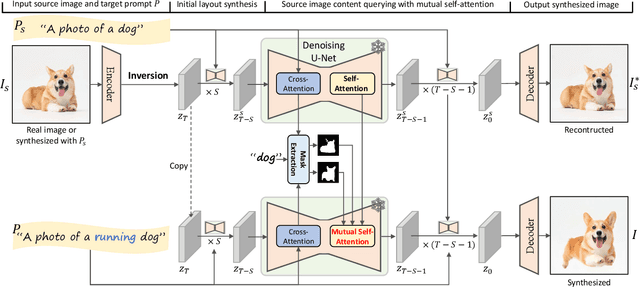
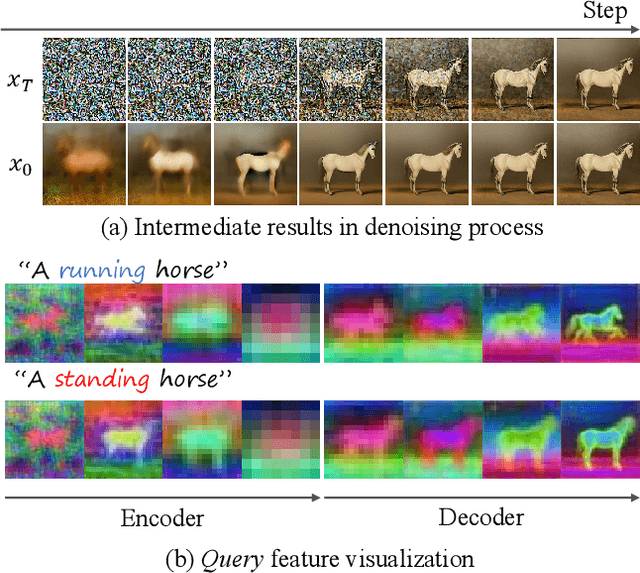
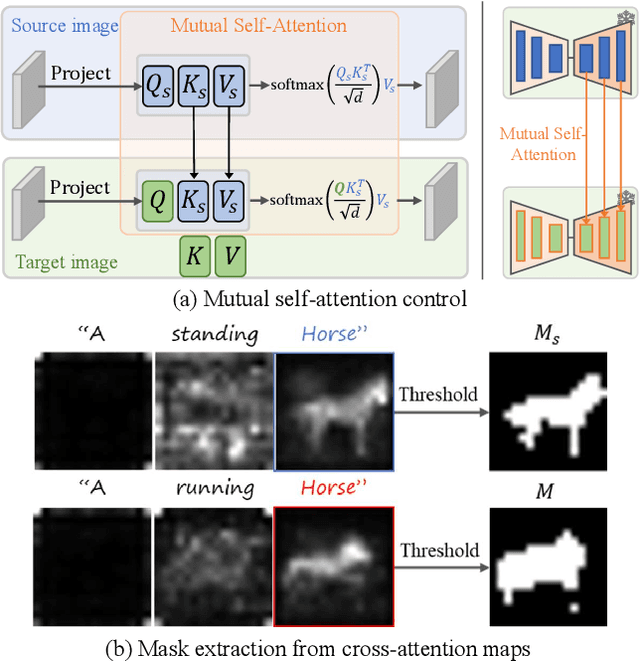
Despite the success in large-scale text-to-image generation and text-conditioned image editing, existing methods still struggle to produce consistent generation and editing results. For example, generation approaches usually fail to synthesize multiple images of the same objects/characters but with different views or poses. Meanwhile, existing editing methods either fail to achieve effective complex non-rigid editing while maintaining the overall textures and identity, or require time-consuming fine-tuning to capture the image-specific appearance. In this paper, we develop MasaCtrl, a tuning-free method to achieve consistent image generation and complex non-rigid image editing simultaneously. Specifically, MasaCtrl converts existing self-attention in diffusion models into mutual self-attention, so that it can query correlated local contents and textures from source images for consistency. To further alleviate the query confusion between foreground and background, we propose a mask-guided mutual self-attention strategy, where the mask can be easily extracted from the cross-attention maps. Extensive experiments show that the proposed MasaCtrl can produce impressive results in both consistent image generation and complex non-rigid real image editing.
VMesh: Hybrid Volume-Mesh Representation for Efficient View Synthesis
Mar 28, 2023
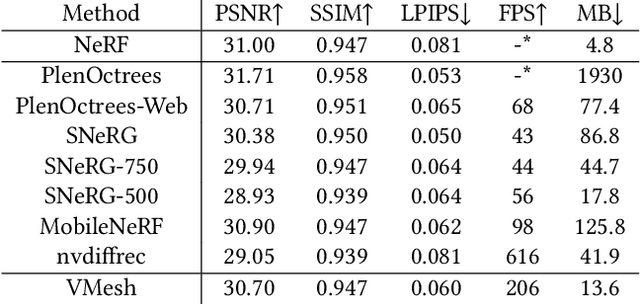
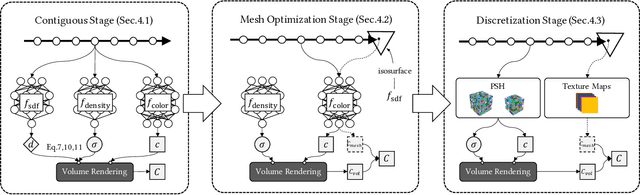
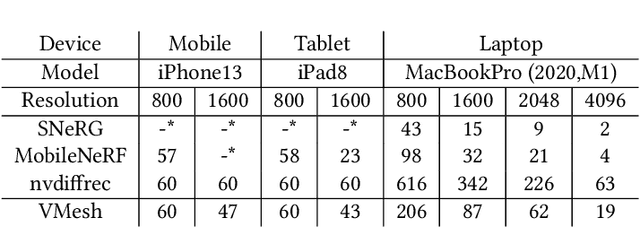
With the emergence of neural radiance fields (NeRFs), view synthesis quality has reached an unprecedented level. Compared to traditional mesh-based assets, this volumetric representation is more powerful in expressing scene geometry but inevitably suffers from high rendering costs and can hardly be involved in further processes like editing, posing significant difficulties in combination with the existing graphics pipeline. In this paper, we present a hybrid volume-mesh representation, VMesh, which depicts an object with a textured mesh along with an auxiliary sparse volume. VMesh retains the advantages of mesh-based assets, such as efficient rendering, compact storage, and easy editing, while also incorporating the ability to represent subtle geometric structures provided by the volumetric counterpart. VMesh can be obtained from multi-view images of an object and renders at 2K 60FPS on common consumer devices with high fidelity, unleashing new opportunities for real-time immersive applications.
Accelerating Vision-Language Pretraining with Free Language Modeling
Mar 24, 2023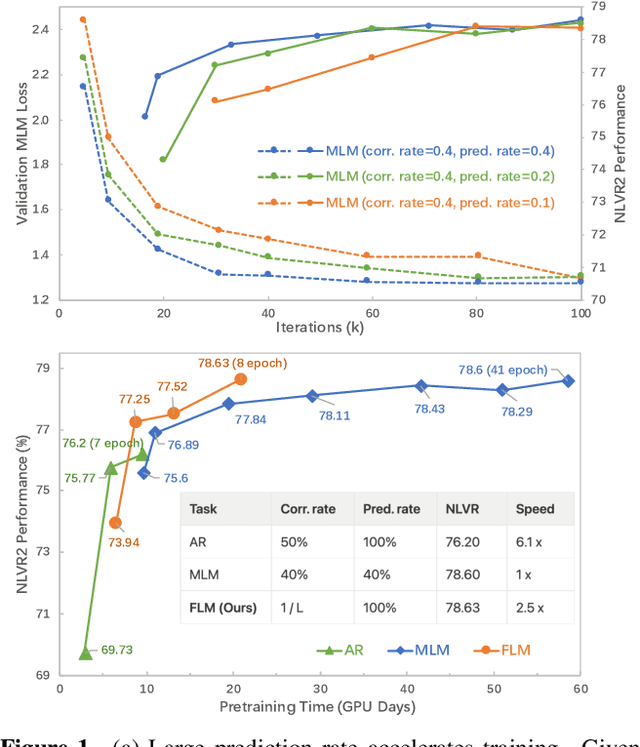
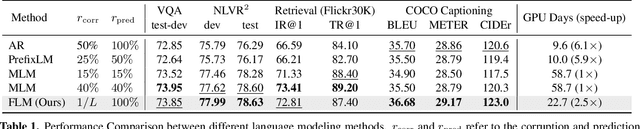
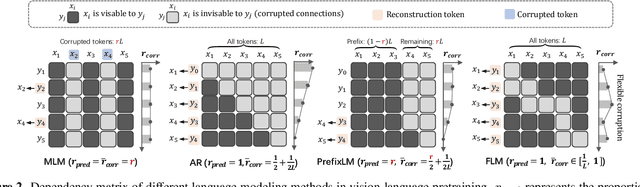
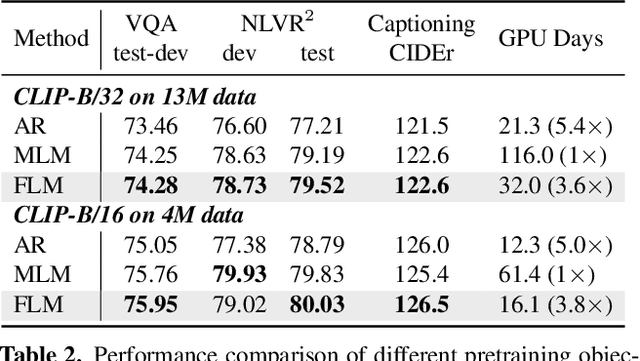
The state of the arts in vision-language pretraining (VLP) achieves exemplary performance but suffers from high training costs resulting from slow convergence and long training time, especially on large-scale web datasets. An essential obstacle to training efficiency lies in the entangled prediction rate (percentage of tokens for reconstruction) and corruption rate (percentage of corrupted tokens) in masked language modeling (MLM), that is, a proper corruption rate is achieved at the cost of a large portion of output tokens being excluded from prediction loss. To accelerate the convergence of VLP, we propose a new pretraining task, namely, free language modeling (FLM), that enables a 100% prediction rate with arbitrary corruption rates. FLM successfully frees the prediction rate from the tie-up with the corruption rate while allowing the corruption spans to be customized for each token to be predicted. FLM-trained models are encouraged to learn better and faster given the same GPU time by exploiting bidirectional contexts more flexibly. Extensive experiments show FLM could achieve an impressive 2.5x pretraining time reduction in comparison to the MLM-based methods, while keeping competitive performance on both vision-language understanding and generation tasks. Code will be public at https://github.com/TencentARC/FLM.
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
Feb 16, 2023



The incredible generative ability of large-scale text-to-image (T2I) models has demonstrated strong power of learning complex structures and meaningful semantics. However, relying solely on text prompts cannot fully take advantage of the knowledge learned by the model, especially when flexible and accurate structure control is needed. In this paper, we aim to ``dig out" the capabilities that T2I models have implicitly learned, and then explicitly use them to control the generation more granularly. Specifically, we propose to learn simple and small T2I-Adapters to align internal knowledge in T2I models with external control signals, while freezing the original large T2I models. In this way, we can train various adapters according to different conditions, and achieve rich control and editing effects. Further, the proposed T2I-Adapters have attractive properties of practical value, such as composability and generalization ability. Extensive experiments demonstrate that our T2I-Adapter has promising generation quality and a wide range of applications.
Masked Visual Reconstruction in Language Semantic Space
Jan 17, 2023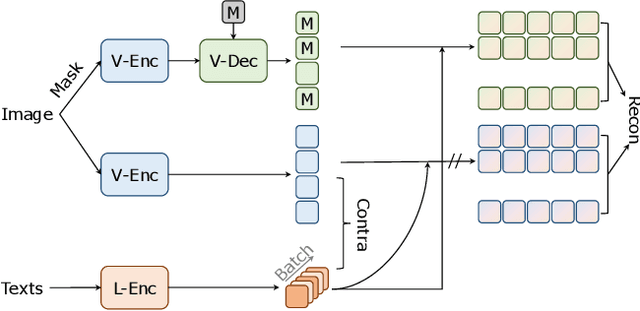
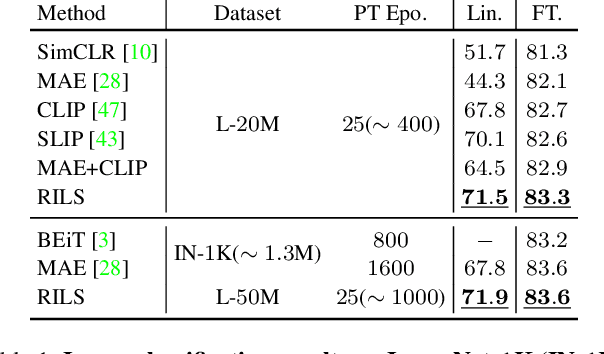
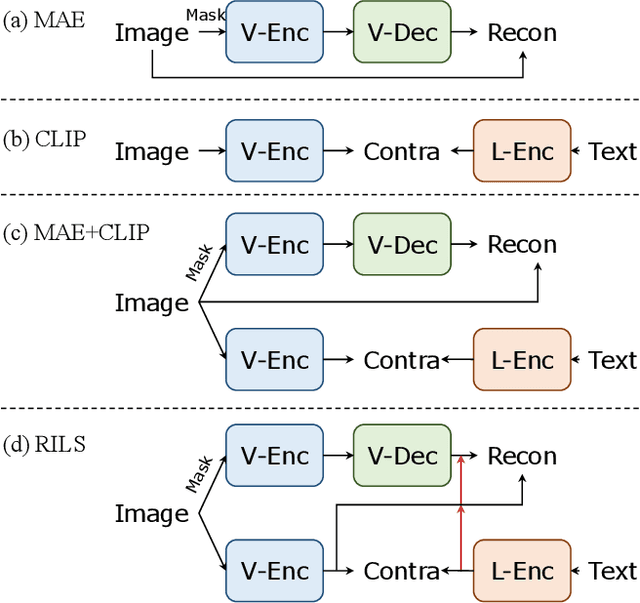
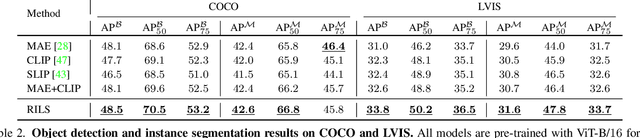
Both masked image modeling (MIM) and natural language supervision have facilitated the progress of transferable visual pre-training. In this work, we seek the synergy between two paradigms and study the emerging properties when MIM meets natural language supervision. To this end, we present a novel masked visual Reconstruction In Language semantic Space (RILS) pre-training framework, in which sentence representations, encoded by the text encoder, serve as prototypes to transform the vision-only signals into patch-sentence probabilities as semantically meaningful MIM reconstruction targets. The vision models can therefore capture useful components with structured information by predicting proper semantic of masked tokens. Better visual representations could, in turn, improve the text encoder via the image-text alignment objective, which is essential for the effective MIM target transformation. Extensive experimental results demonstrate that our method not only enjoys the best of previous MIM and CLIP but also achieves further improvements on various tasks due to their mutual benefits. RILS exhibits advanced transferability on downstream classification, detection, and segmentation, especially for low-shot regimes. Code will be made available at https://github.com/hustvl/RILS.
Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models
Dec 28, 2022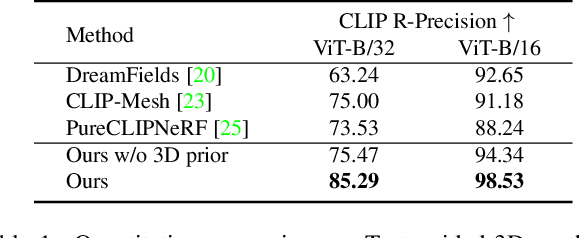



Recent CLIP-guided 3D optimization methods, e.g., DreamFields and PureCLIPNeRF achieve great success in zero-shot text-guided 3D synthesis. However, due to the scratch training and random initialization without any prior knowledge, these methods usually fail to generate accurate and faithful 3D structures that conform to the corresponding text. In this paper, we make the first attempt to introduce the explicit 3D shape prior to CLIP-guided 3D optimization methods. Specifically, we first generate a high-quality 3D shape from input texts in the text-to-shape stage as the 3D shape prior. We then utilize it as the initialization of a neural radiance field and then optimize it with the full prompt. For the text-to-shape generation, we present a simple yet effective approach that directly bridges the text and image modalities with a powerful text-to-image diffusion model. To narrow the style domain gap between images synthesized by the text-to-image model and shape renderings used to train the image-to-shape generator, we further propose to jointly optimize a learnable text prompt and fine-tune the text-to-image diffusion model for rendering-style image generation. Our method, namely, Dream3D, is capable of generating imaginative 3D content with better visual quality and shape accuracy than state-of-the-art methods.
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Dec 22, 2022


To reproduce the success of text-to-image (T2I) generation, recent works in text-to-video (T2V) generation employ large-scale text-video dataset for fine-tuning. However, such paradigm is computationally expensive. Humans have the amazing ability to learn new visual concepts from just one single exemplar. We hereby study a new T2V generation problem$\unicode{x2014}$One-Shot Video Generation, where only a single text-video pair is presented for training an open-domain T2V generator. Intuitively, we propose to adapt the T2I diffusion model pretrained on massive image data for T2V generation. We make two key observations: 1) T2I models are able to generate images that align well with the verb terms; 2) extending T2I models to generate multiple images concurrently exhibits surprisingly good content consistency. To further learn continuous motion, we propose Tune-A-Video with a tailored Sparse-Causal Attention, which generates videos from text prompts via an efficient one-shot tuning of pretrained T2I diffusion models. Tune-A-Video is capable of producing temporally-coherent videos over various applications such as change of subject or background, attribute editing, style transfer, demonstrating the versatility and effectiveness of our method.
Rethinking the Objectives of Vector-Quantized Tokenizers for Image Synthesis
Dec 06, 2022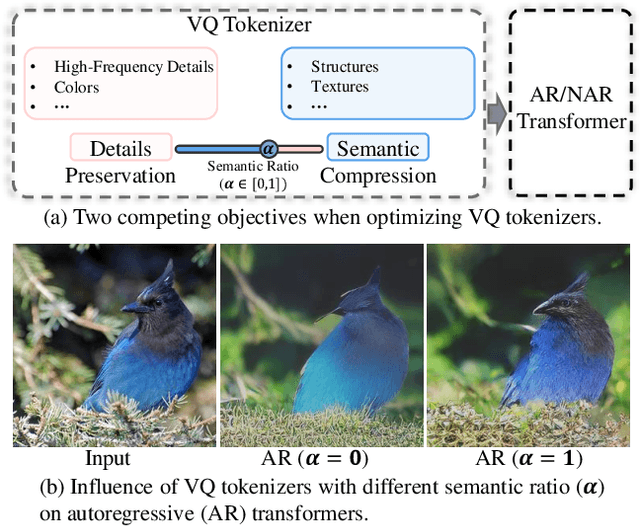
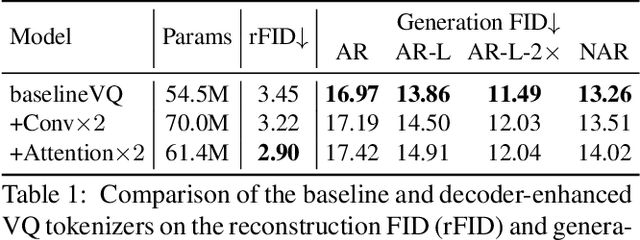

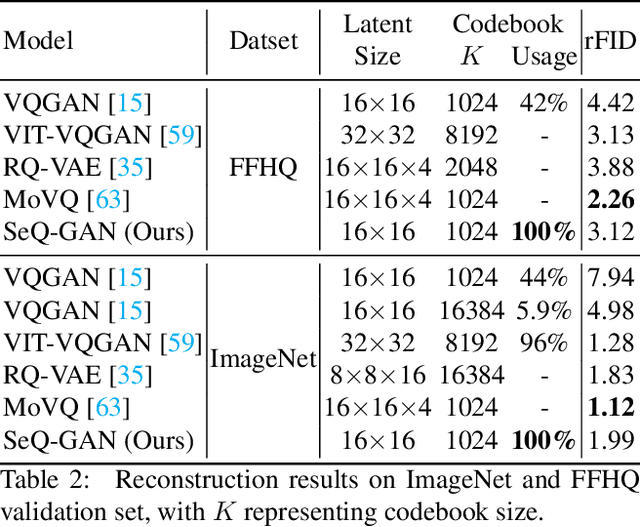
Vector-Quantized (VQ-based) generative models usually consist of two basic components, i.e., VQ tokenizers and generative transformers. Prior research focuses on improving the reconstruction fidelity of VQ tokenizers but rarely examines how the improvement in reconstruction affects the generation ability of generative transformers. In this paper, we surprisingly find that improving the reconstruction fidelity of VQ tokenizers does not necessarily improve the generation. Instead, learning to compress semantic features within VQ tokenizers significantly improves generative transformers' ability to capture textures and structures. We thus highlight two competing objectives of VQ tokenizers for image synthesis: semantic compression and details preservation. Different from previous work that only pursues better details preservation, we propose Semantic-Quantized GAN (SeQ-GAN) with two learning phases to balance the two objectives. In the first phase, we propose a semantic-enhanced perceptual loss for better semantic compression. In the second phase, we fix the encoder and codebook, but enhance and finetune the decoder to achieve better details preservation. The proposed SeQ-GAN greatly improves VQ-based generative models and surpasses the GAN and Diffusion Models on both unconditional and conditional image generation. Our SeQ-GAN (364M) achieves Frechet Inception Distance (FID) of 6.25 and Inception Score (IS) of 140.9 on 256x256 ImageNet generation, a remarkable improvement over VIT-VQGAN (714M), which obtains 11.2 FID and 97.2 IS.