 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJADE: Expert-Grounded Dynamic Evaluation for Open-Ended Professional Tasks
Feb 06, 2026Evaluating agentic AI on open-ended professional tasks faces a fundamental dilemma between rigor and flexibility. Static rubrics provide rigorous, reproducible assessment but fail to accommodate diverse valid response strategies, while LLM-as-a-judge approaches adapt to individual responses yet suffer from instability and bias. Human experts address this dilemma by combining domain-grounded principles with dynamic, claim-level assessment. Inspired by this process, we propose JADE, a two-layer evaluation framework. Layer 1 encodes expert knowledge as a predefined set of evaluation skills, providing stable evaluation criteria. Layer 2 performs report-specific, claim-level evaluation to flexibly assess diverse reasoning strategies, with evidence-dependency gating to invalidate conclusions built on refuted claims. Experiments on BizBench show that JADE improves evaluation stability and reveals critical agent failure modes missed by holistic LLM-based evaluators. We further demonstrate strong alignment with expert-authored rubrics and effective transfer to a medical-domain benchmark, validating JADE across professional domains. Our code is publicly available at https://github.com/smiling-world/JADE.
How Good Are Large Language Models for Course Recommendation in MOOCs?
Apr 11, 2025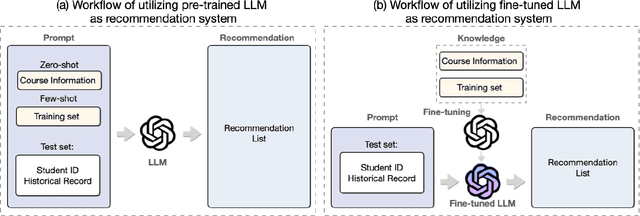


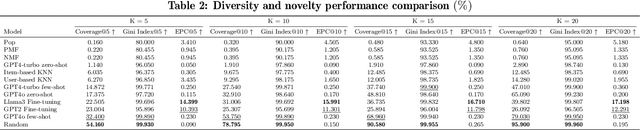
Large Language Models (LLMs) have made significant strides in natural language processing and are increasingly being integrated into recommendation systems. However, their potential in educational recommendation systems has yet to be fully explored. This paper investigates the use of LLMs as a general-purpose recommendation model, leveraging their vast knowledge derived from large-scale corpora for course recommendation tasks. We explore a variety of approaches, ranging from prompt-based methods to more advanced fine-tuning techniques, and compare their performance against traditional recommendation models. Extensive experiments were conducted on a real-world MOOC dataset, evaluating using LLMs as course recommendation systems across key dimensions such as accuracy, diversity, and novelty. Our results demonstrate that LLMs can achieve good performance comparable to traditional models, highlighting their potential to enhance educational recommendation systems. These findings pave the way for further exploration and development of LLM-based approaches in the context of educational recommendations.
Examining GPT's Capability to Generate and Map Course Concepts and Their Relationship
Apr 11, 2025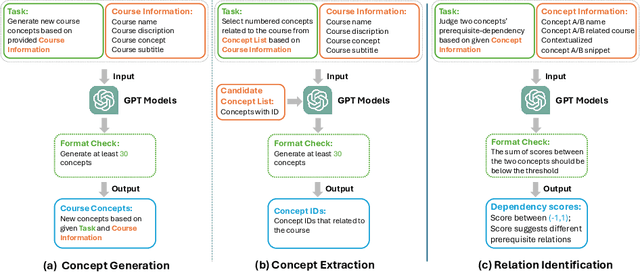
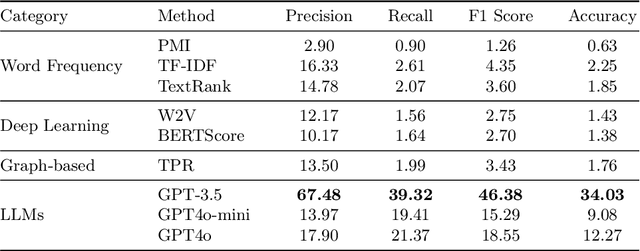

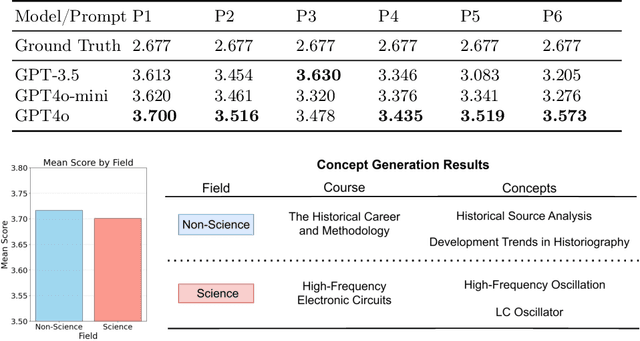
Extracting key concepts and their relationships from course information and materials facilitates the provision of visualizations and recommendations for learners who need to select the right courses to take from a large number of courses. However, identifying and extracting themes manually is labor-intensive and time-consuming. Previous machine learning-based methods to extract relevant concepts from courses heavily rely on detailed course materials, which necessitates labor-intensive preparation of course materials. This paper investigates the potential of LLMs such as GPT in automatically generating course concepts and their relations. Specifically, we design a suite of prompts and provide GPT with the course information with different levels of detail, thereby generating high-quality course concepts and identifying their relations. Furthermore, we comprehensively evaluate the quality of the generated concepts and relationships through extensive experiments. Our results demonstrate the viability of LLMs as a tool for supporting educational content selection and delivery.
Identify Then Recommend: Towards Unsupervised Group Recommendation
Oct 31, 2024Group Recommendation (GR), which aims to recommend items to groups of users, has become a promising and practical direction for recommendation systems. This paper points out two issues of the state-of-the-art GR models. (1) The pre-defined and fixed number of user groups is inadequate for real-time industrial recommendation systems, where the group distribution can shift dynamically. (2) The training schema of existing GR methods is supervised, necessitating expensive user-group and group-item labels, leading to significant annotation costs. To this end, we present a novel unsupervised group recommendation framework named \underline{I}dentify \underline{T}hen \underline{R}ecommend (\underline{ITR}), where it first identifies the user groups in an unsupervised manner even without the pre-defined number of groups, and then two pre-text tasks are designed to conduct self-supervised group recommendation. Concretely, at the group identification stage, we first estimate the adaptive density of each user point, where areas with higher densities are more likely to be recognized as group centers. Then, a heuristic merge-and-split strategy is designed to discover the user groups and decision boundaries. Subsequently, at the self-supervised learning stage, the pull-and-repulsion pre-text task is proposed to optimize the user-group distribution. Besides, the pseudo group recommendation pre-text task is designed to assist the recommendations. Extensive experiments demonstrate the superiority and effectiveness of ITR on both user recommendation (e.g., 22.22\% NDCG@5 $\uparrow$) and group recommendation (e.g., 22.95\% NDCG@5 $\uparrow$). Furthermore, we deploy ITR on the industrial recommender and achieve promising results.
Can We Improve Channel Reciprocity via Loop-back Compensation for RIS-assisted Physical Layer Key Generation
Jan 31, 2024Reconfigurable intelligent surface (RIS) facilitates the extraction of unpredictable channel features for physical layer key generation (PKG), securing communications among legitimate users with symmetric keys. Previous works have demonstrated that channel reciprocity plays a crucial role in generating symmetric keys in PKG systems, whereas, in reality, reciprocity is greatly affected by hardware interference and RIS-based jamming attacks. This motivates us to propose LoCKey, a novel approach that aims to improve channel reciprocity by mitigating interferences and attacks with a loop-back compensation scheme, thus maximizing the secrecy performance of the PKG system. Specifically, our proposed LoCKey is capable of effectively compensating for the CSI non-reciprocity by the combination of transmit-back signal value and error minimization module. Firstly, we introduce the entire flowchart of our method and provide an in-depth discussion of each step. Following that, we delve into a theoretical analysis of the performance optimizations when our LoCKey is applied for CSI reciprocity enhancement. Finally, we conduct experiments to verify the effectiveness of the proposed LoCKey in improving channel reciprocity under various interferences for RIS-assisted wireless communications. The results demonstrate a significant improvement in both the rate of key generation assisted by the RIS and the consistency of the generated keys, showing great potential for the practical deployment of our LoCKey in future wireless systems.
HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video
Apr 24, 2023We introduce HOSNeRF, a novel 360{\deg} free-viewpoint rendering method that reconstructs neural radiance fields for dynamic human-object-scene from a single monocular in-the-wild video. Our method enables pausing the video at any frame and rendering all scene details (dynamic humans, objects, and backgrounds) from arbitrary viewpoints. The first challenge in this task is the complex object motions in human-object interactions, which we tackle by introducing the new object bones into the conventional human skeleton hierarchy to effectively estimate large object deformations in our dynamic human-object model. The second challenge is that humans interact with different objects at different times, for which we introduce two new learnable object state embeddings that can be used as conditions for learning our human-object representation and scene representation, respectively. Extensive experiments show that HOSNeRF significantly outperforms SOTA approaches on two challenging datasets by a large margin of 40% ~ 50% in terms of LPIPS. The code, data, and compelling examples of 360{\deg} free-viewpoint renderings from single videos will be released in https://showlab.github.io/HOSNeRF.