 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaffolding Metacognition in Programming Education: Understanding Student-AI Interactions and Design Implications
Nov 06, 2025Generative AI tools such as ChatGPT now provide novice programmers with unprecedented access to instant, personalized support. While this holds clear promise, their influence on students' metacognitive processes remains underexplored. Existing work has largely focused on correctness and usability, with limited attention to whether and how students' use of AI assistants supports or bypasses key metacognitive processes. This study addresses that gap by analyzing student-AI interactions through a metacognitive lens in university-level programming courses. We examined more than 10,000 dialogue logs collected over three years, complemented by surveys of students and educators. Our analysis focused on how prompts and responses aligned with metacognitive phases and strategies. Synthesizing these findings across data sources, we distill design considerations for AI-powered coding assistants that aim to support rather than supplant metacognitive engagement. Our findings provide guidance for developing educational AI tools that strengthen students' learning processes in programming education.
Examining GPT's Capability to Generate and Map Course Concepts and Their Relationship
Apr 11, 2025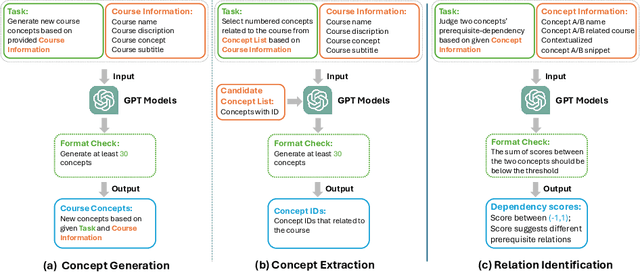
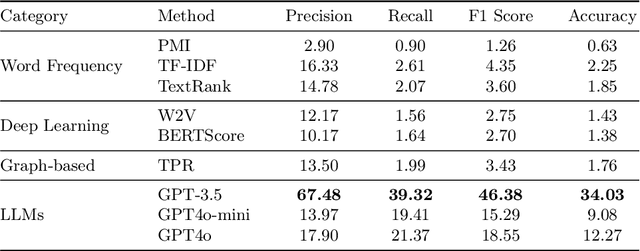

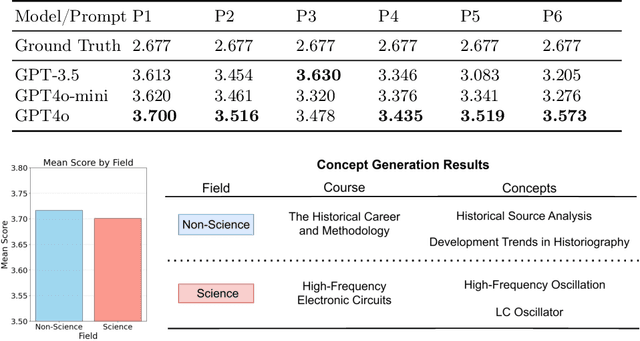
Extracting key concepts and their relationships from course information and materials facilitates the provision of visualizations and recommendations for learners who need to select the right courses to take from a large number of courses. However, identifying and extracting themes manually is labor-intensive and time-consuming. Previous machine learning-based methods to extract relevant concepts from courses heavily rely on detailed course materials, which necessitates labor-intensive preparation of course materials. This paper investigates the potential of LLMs such as GPT in automatically generating course concepts and their relations. Specifically, we design a suite of prompts and provide GPT with the course information with different levels of detail, thereby generating high-quality course concepts and identifying their relations. Furthermore, we comprehensively evaluate the quality of the generated concepts and relationships through extensive experiments. Our results demonstrate the viability of LLMs as a tool for supporting educational content selection and delivery.
DragScene: Interactive 3D Scene Editing with Single-view Drag Instructions
Dec 18, 2024



3D editing has shown remarkable capability in editing scenes based on various instructions. However, existing methods struggle with achieving intuitive, localized editing, such as selectively making flowers blossom. Drag-style editing has shown exceptional capability to edit images with direct manipulation instead of ambiguous text commands. Nevertheless, extending drag-based editing to 3D scenes presents substantial challenges due to multi-view inconsistency. To this end, we introduce DragScene, a framework that integrates drag-style editing with diverse 3D representations. First, latent optimization is performed on a reference view to generate 2D edits based on user instructions. Subsequently, coarse 3D clues are reconstructed from the reference view using a point-based representation to capture the geometric details of the edits. The latent representation of the edited view is then mapped to these 3D clues, guiding the latent optimization of other views. This process ensures that edits are propagated seamlessly across multiple views, maintaining multi-view consistency. Finally, the target 3D scene is reconstructed from the edited multi-view images. Extensive experiments demonstrate that DragScene facilitates precise and flexible drag-style editing of 3D scenes, supporting broad applicability across diverse 3D representations.
Tuning-Free Visual Customization via View Iterative Self-Attention Control
Jun 11, 2024



Fine-Tuning Diffusion Models enable a wide range of personalized generation and editing applications on diverse visual modalities. While Low-Rank Adaptation (LoRA) accelerates the fine-tuning process, it still requires multiple reference images and time-consuming training, which constrains its scalability for large-scale and real-time applications. In this paper, we propose \textit{View Iterative Self-Attention Control (VisCtrl)} to tackle this challenge. Specifically, VisCtrl is a training-free method that injects the appearance and structure of a user-specified subject into another subject in the target image, unlike previous approaches that require fine-tuning the model. Initially, we obtain the initial noise for both the reference and target images through DDIM inversion. Then, during the denoising phase, features from the reference image are injected into the target image via the self-attention mechanism. Notably, by iteratively performing this feature injection process, we ensure that the reference image features are gradually integrated into the target image. This approach results in consistent and harmonious editing with only one reference image in a few denoising steps. Moreover, benefiting from our plug-and-play architecture design and the proposed Feature Gradual Sampling strategy for multi-view editing, our method can be easily extended to edit in complex visual domains. Extensive experiments show the efficacy of VisCtrl across a spectrum of tasks, including personalized editing of images, videos, and 3D scenes.