 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDSL: A Hierarchical Domain-Specific Language for Structured 3D Indoor Scene Generation and Localized Editing with LLM Agents
Jun 08, 2026Text-driven indoor scene generation and editing require an intermediate representation that language models can both produce and revise. Existing LLM-based systems often rely on scene graphs or global constraint lists, which are compact but underspecify local geometry and make instruction-based edits difficult to localize. We frame this problem as structured program generation and local program repair, and propose Hierarchical Descriptive Scene Language (HDSL), an XML/CSS-style domain-specific language for structured 3D indoor scenes. HDSL represents rooms, regions, objects, and support surfaces as a tree with local coordinates, making complex scenes easier to plan recursively and easier to retrieve for editing. Our pipeline uses LLM agents to generate HDSL subtrees with bounded verification, grounds non-virtual nodes through multimodal asset retrieval, and applies force-directed layout optimization to repair boundary and collision errors. For editing, Hierarchical Retrieval-Augmented Generation retrieves the relevant subtree, asks the LLM to rewrite only that local context, and merges the result back through a deterministic three-way merge. In our reproduced benchmark, HDSL improves average object coverage, text-scene alignment, and generation time over full text-to-scene baselines while remaining competitive with recent layout-only reproductions on geometry metrics; for editing, HRAG reduces token use by $5.22\times$ and runtime by $6.19\times$, produces valid DSL for all eight paired edits, and better preserves unrelated scene objects.
RoboStream: Weaving Spatio-Temporal Reasoning with Memory in Vision-Language Models for Robotics
Mar 13, 2026Enabling reliable long-horizon robotic manipulation is a crucial step toward open-world embodied intelligence. However, VLM-based planners treat each step as an isolated observation-to-action mapping, forcing them to reinfer scene geometry from raw pixels at every decision point while remaining unaware of how prior actions have reshaped the environment. Despite strong short-horizon performance, these systems lack the spatio-temporal reasoning required for persistent geometric anchoring and memory of action-triggered state transitions. Without persistent state tracking, perceptual errors accumulate across the execution horizon, temporarily occluded objects are catastrophically forgotten, and these compounding failures lead to precondition violations that cascade through subsequent steps. In contrast, humans maintain a persistent mental model that continuously tracks spatial relations and action consequences across interactions rather than reconstructing them at each instant. Inspired by this human capacity for causal spatio-temporal reasoning with persistent memory, we propose RoboStream, a training-free framework that achieves geometric anchoring through Spatio-Temporal Fusion Tokens (STF-Tokens), which bind visual evidence to 3D geometric attributes for persistent object grounding, and maintains causal continuity via a Causal Spatio-Temporal Graph (CSTG) that records action-triggered state transitions across steps. This design enables the planner to trace causal chains and preserve object permanence under occlusion without additional training or fine-tuning. RoboStream achieves 90.5% on long-horizon RLBench and 44.4% on challenging real-world block-building tasks, where both SoFar and VoxPoser score 11.1%, demonstrating that spatio-temporal reasoning and causal memory are critical missing components for reliable long-horizon manipulation.
Tail-Aware Post-Training Quantization for 3D Geometry Models
Feb 02, 2026The burgeoning complexity and scale of 3D geometry models pose significant challenges for deployment on resource-constrained platforms. While Post-Training Quantization (PTQ) enables efficient inference without retraining, conventional methods, primarily optimized for 2D Vision Transformers, fail to transfer effectively to 3D models due to intricate feature distributions and prohibitive calibration overhead. To address these challenges, we propose TAPTQ, a Tail-Aware Post-Training Quantization pipeline specifically engineered for 3D geometric learning. Our contribution is threefold: (1) To overcome the data-scale bottleneck in 3D datasets, we develop a progressive coarse-to-fine calibration construction strategy that constructs a highly compact subset to achieve both statistical purity and geometric representativeness. (2) We reformulate the quantization interval search as an optimization problem and introduce a ternary-search-based solver, reducing the computational complexity from $\mathcal{O}(N)$ to $\mathcal{O}(\log N)$ for accelerated deployment. (3) To mitigate quantization error accumulation, we propose TRE-Guided Module-wise Compensation, which utilizes a Tail Relative Error (TRE) metric to adaptively identify and rectify distortions in modules sensitive to long-tailed activation outliers. Extensive experiments on the VGGT and Pi3 benchmarks demonstrate that TAPTQ consistently outperforms state-of-the-art PTQ methods in accuracy while significantly reducing calibration time. The code will be released soon.
Splatwizard: A Benchmark Toolkit for 3D Gaussian Splatting Compression
Dec 31, 2025The recent advent of 3D Gaussian Splatting (3DGS) has marked a significant breakthrough in real-time novel view synthesis. However, the rapid proliferation of 3DGS-based algorithms has created a pressing need for standardized and comprehensive evaluation tools, especially for compression task. Existing benchmarks often lack the specific metrics necessary to holistically assess the unique characteristics of different methods, such as rendering speed, rate distortion trade-offs memory efficiency, and geometric accuracy. To address this gap, we introduce Splatwizard, a unified benchmark toolkit designed specifically for benchmarking 3DGS compression models. Splatwizard provides an easy-to-use framework to implement new 3DGS compression model and utilize state-of-the-art techniques proposed by previous work. Besides, an integrated pipeline that automates the calculation of key performance indicators, including image-based quality metrics, chamfer distance of reconstruct mesh, rendering frame rates, and computational resource consumption is included in the framework as well. Code is available at https://github.com/splatwizard/splatwizard
SD-GS: Structured Deformable 3D Gaussians for Efficient Dynamic Scene Reconstruction
Jul 10, 2025Current 4D Gaussian frameworks for dynamic scene reconstruction deliver impressive visual fidelity and rendering speed, however, the inherent trade-off between storage costs and the ability to characterize complex physical motions significantly limits the practical application of these methods. To tackle these problems, we propose SD-GS, a compact and efficient dynamic Gaussian splatting framework for complex dynamic scene reconstruction, featuring two key contributions. First, we introduce a deformable anchor grid, a hierarchical and memory-efficient scene representation where each anchor point derives multiple 3D Gaussians in its local spatiotemporal region and serves as the geometric backbone of the 3D scene. Second, to enhance modeling capability for complex motions, we present a deformation-aware densification strategy that adaptively grows anchors in under-reconstructed high-dynamic regions while reducing redundancy in static areas, achieving superior visual quality with fewer anchors. Experimental results demonstrate that, compared to state-of-the-art methods, SD-GS achieves an average of 60\% reduction in model size and an average of 100\% improvement in FPS, significantly enhancing computational efficiency while maintaining or even surpassing visual quality.
Lungmix: A Mixup-Based Strategy for Generalization in Respiratory Sound Classification
Dec 29, 2024Respiratory sound classification plays a pivotal role in diagnosing respiratory diseases. While deep learning models have shown success with various respiratory sound datasets, our experiments indicate that models trained on one dataset often fail to generalize effectively to others, mainly due to data collection and annotation \emph{inconsistencies}. To address this limitation, we introduce \emph{Lungmix}, a novel data augmentation technique inspired by Mixup. Lungmix generates augmented data by blending waveforms using loudness and random masks while interpolating labels based on their semantic meaning, helping the model learn more generalized representations. Comprehensive evaluations across three datasets, namely ICBHI, SPR, and HF, demonstrate that Lungmix significantly enhances model generalization to unseen data. In particular, Lungmix boosts the 4-class classification score by up to 3.55\%, achieving performance comparable to models trained directly on the target dataset.
DragScene: Interactive 3D Scene Editing with Single-view Drag Instructions
Dec 18, 2024



3D editing has shown remarkable capability in editing scenes based on various instructions. However, existing methods struggle with achieving intuitive, localized editing, such as selectively making flowers blossom. Drag-style editing has shown exceptional capability to edit images with direct manipulation instead of ambiguous text commands. Nevertheless, extending drag-based editing to 3D scenes presents substantial challenges due to multi-view inconsistency. To this end, we introduce DragScene, a framework that integrates drag-style editing with diverse 3D representations. First, latent optimization is performed on a reference view to generate 2D edits based on user instructions. Subsequently, coarse 3D clues are reconstructed from the reference view using a point-based representation to capture the geometric details of the edits. The latent representation of the edited view is then mapped to these 3D clues, guiding the latent optimization of other views. This process ensures that edits are propagated seamlessly across multiple views, maintaining multi-view consistency. Finally, the target 3D scene is reconstructed from the edited multi-view images. Extensive experiments demonstrate that DragScene facilitates precise and flexible drag-style editing of 3D scenes, supporting broad applicability across diverse 3D representations.
EVOS: Efficient Implicit Neural Training via EVOlutionary Selector
Dec 13, 2024



We propose EVOlutionary Selector (EVOS), an efficient training paradigm for accelerating Implicit Neural Representation (INR). Unlike conventional INR training that feeds all samples through the neural network in each iteration, our approach restricts training to strategically selected points, reducing computational overhead by eliminating redundant forward passes. Specifically, we treat each sample as an individual in an evolutionary process, where only those fittest ones survive and merit inclusion in training, adaptively evolving with the neural network dynamics. While this is conceptually similar to Evolutionary Algorithms, their distinct objectives (selection for acceleration vs. iterative solution optimization) require a fundamental redefinition of evolutionary mechanisms for our context. In response, we design sparse fitness evaluation, frequency-guided crossover, and augmented unbiased mutation to comprise EVOS. These components respectively guide sample selection with reduced computational cost, enhance performance through frequency-domain balance, and mitigate selection bias from cached evaluation. Extensive experiments demonstrate that our method achieves approximately 48%-66% reduction in training time while ensuring superior convergence without additional cost, establishing state-of-the-art acceleration among recent sampling-based strategies.
Enhancing Implicit Neural Representations via Symmetric Power Transformation
Dec 12, 2024



We propose symmetric power transformation to enhance the capacity of Implicit Neural Representation~(INR) from the perspective of data transformation. Unlike prior work utilizing random permutation or index rearrangement, our method features a reversible operation that does not require additional storage consumption. Specifically, we first investigate the characteristics of data that can benefit the training of INR, proposing the Range-Defined Symmetric Hypothesis, which posits that specific range and symmetry can improve the expressive ability of INR. Based on this hypothesis, we propose a nonlinear symmetric power transformation to achieve both range-defined and symmetric properties simultaneously. We use the power coefficient to redistribute data to approximate symmetry within the target range. To improve the robustness of the transformation, we further design deviation-aware calibration and adaptive soft boundary to address issues of extreme deviation boosting and continuity breaking. Extensive experiments are conducted to verify the performance of the proposed method, demonstrating that our transformation can reliably improve INR compared with other data transformations. We also conduct 1D audio, 2D image and 3D video fitting tasks to demonstrate the effectiveness and applicability of our method.
SizeGS: Size-aware Compression of 3D Gaussians with Hierarchical Mixed Precision Quantization
Dec 08, 2024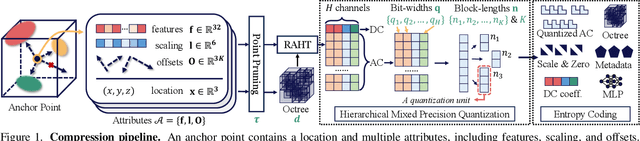
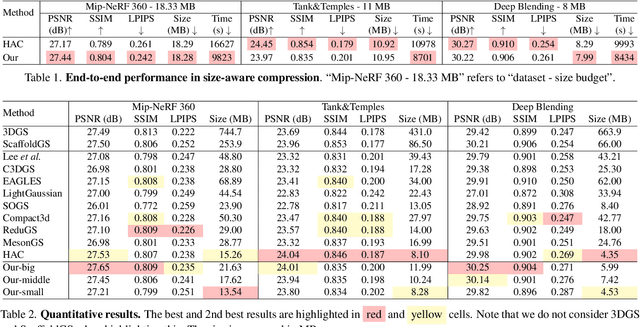
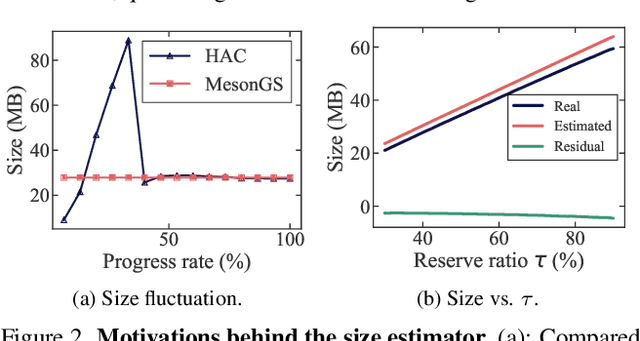

Effective compression technology is crucial for 3DGS to adapt to varying storage and transmission conditions. However, existing methods fail to address size constraints while maintaining optimal quality. In this paper, we introduce SizeGS, a framework that compresses 3DGS within a specified size budget while optimizing visual quality. We start with a size estimator to establish a clear relationship between file size and hyperparameters. Leveraging this estimator, we incorporate mixed precision quantization (MPQ) into 3DGS attributes, structuring MPQ in two hierarchical level -- inter-attribute and intra-attribute -- to optimize visual quality under the size constraint. At the inter-attribute level, we assign bit-widths to each attribute channel by formulating the combinatorial optimization as a 0-1 integer linear program, which can be efficiently solved. At the intra-attribute level, we divide each attribute channel into blocks of vectors, quantizing each vector based on the optimal bit-width derived at the inter-attribute level. Dynamic programming determines block lengths. Using the size estimator and MPQ, we develop a calibrated algorithm to identify optimal hyperparameters in just 10 minutes, achieving a 1.69$\times$ efficiency increase with quality comparable to state-of-the-art methods.