 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPSv3++: Scaling Reward Models Across the Full Spectrum of Diffusion Model Capabilities
Jun 12, 2026Reward models guide text-to-image (T2I) systems toward outputs aligned with human preferences. However, typical reward models such as HPSv3 are trained on pre-annotated data from earlier T2I models, without accounting for quality discriminative shifts arising from evolving model capabilities and reinforcement learning (RL) iterations, limiting their broader applicability. In this work, we propose HPSv3++, a reward model framework that elevates the HPSv3 model for varying T2I model capabilities and their RL iteration changes across the full capability-iteration spectrum. Specifically, we first introduce HPDv3++, a 212K dual-dimension preference dataset annotated for text fidelity and aesthetic quality using a recent high-capability (Qwen-Image) model with human supervision. We then propose a two-stage training framework. Stage 1 employs data-aware orthogonal gradient projection to incorporate diverse aesthetic perception from HPDv3++ while preserving the original effective human preference knowledge in HPSv3. Stage 2 further leverages unlabeled data from T2I models spanning different capability levels and RL iterations, and introduces a joint capability-iterations conditioned signal for the reward model together with a standard deviation-driven unsupervised guidance mechanism, strengthening reward model across the capability-iteration spectrum. HPSv3++ achieves state-of-the-art preference prediction, outperforming HPSv3 9.8% on HPDv3, 5.5% on GenAI-Bench, while achieving 79.1%/88.1% on our proposed HPDv3++. When used for T2I RL training, it consistently improves GenEval scores across diverse T2I models, demonstrating its wide-range capabilities. The code is available at https://github.com/PlantPotatoOnMoon/HPSv3-PlusPlus.
Lungmix: A Mixup-Based Strategy for Generalization in Respiratory Sound Classification
Dec 29, 2024Respiratory sound classification plays a pivotal role in diagnosing respiratory diseases. While deep learning models have shown success with various respiratory sound datasets, our experiments indicate that models trained on one dataset often fail to generalize effectively to others, mainly due to data collection and annotation \emph{inconsistencies}. To address this limitation, we introduce \emph{Lungmix}, a novel data augmentation technique inspired by Mixup. Lungmix generates augmented data by blending waveforms using loudness and random masks while interpolating labels based on their semantic meaning, helping the model learn more generalized representations. Comprehensive evaluations across three datasets, namely ICBHI, SPR, and HF, demonstrate that Lungmix significantly enhances model generalization to unseen data. In particular, Lungmix boosts the 4-class classification score by up to 3.55\%, achieving performance comparable to models trained directly on the target dataset.
EVOS: Efficient Implicit Neural Training via EVOlutionary Selector
Dec 13, 2024



We propose EVOlutionary Selector (EVOS), an efficient training paradigm for accelerating Implicit Neural Representation (INR). Unlike conventional INR training that feeds all samples through the neural network in each iteration, our approach restricts training to strategically selected points, reducing computational overhead by eliminating redundant forward passes. Specifically, we treat each sample as an individual in an evolutionary process, where only those fittest ones survive and merit inclusion in training, adaptively evolving with the neural network dynamics. While this is conceptually similar to Evolutionary Algorithms, their distinct objectives (selection for acceleration vs. iterative solution optimization) require a fundamental redefinition of evolutionary mechanisms for our context. In response, we design sparse fitness evaluation, frequency-guided crossover, and augmented unbiased mutation to comprise EVOS. These components respectively guide sample selection with reduced computational cost, enhance performance through frequency-domain balance, and mitigate selection bias from cached evaluation. Extensive experiments demonstrate that our method achieves approximately 48%-66% reduction in training time while ensuring superior convergence without additional cost, establishing state-of-the-art acceleration among recent sampling-based strategies.
Enhancing Implicit Neural Representations via Symmetric Power Transformation
Dec 12, 2024



We propose symmetric power transformation to enhance the capacity of Implicit Neural Representation~(INR) from the perspective of data transformation. Unlike prior work utilizing random permutation or index rearrangement, our method features a reversible operation that does not require additional storage consumption. Specifically, we first investigate the characteristics of data that can benefit the training of INR, proposing the Range-Defined Symmetric Hypothesis, which posits that specific range and symmetry can improve the expressive ability of INR. Based on this hypothesis, we propose a nonlinear symmetric power transformation to achieve both range-defined and symmetric properties simultaneously. We use the power coefficient to redistribute data to approximate symmetry within the target range. To improve the robustness of the transformation, we further design deviation-aware calibration and adaptive soft boundary to address issues of extreme deviation boosting and continuity breaking. Extensive experiments are conducted to verify the performance of the proposed method, demonstrating that our transformation can reliably improve INR compared with other data transformations. We also conduct 1D audio, 2D image and 3D video fitting tasks to demonstrate the effectiveness and applicability of our method.
SizeGS: Size-aware Compression of 3D Gaussians with Hierarchical Mixed Precision Quantization
Dec 08, 2024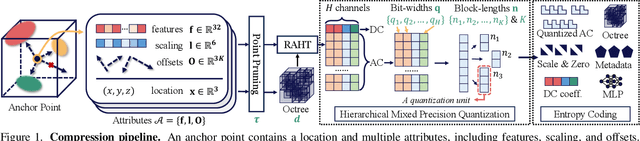
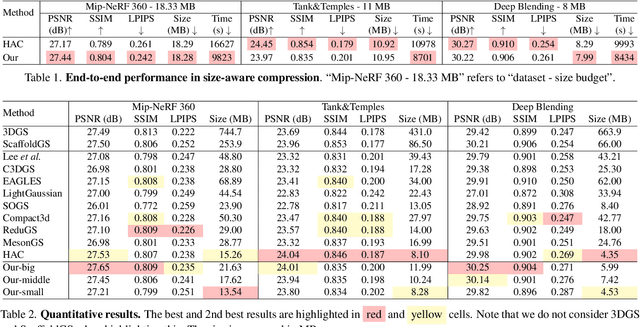
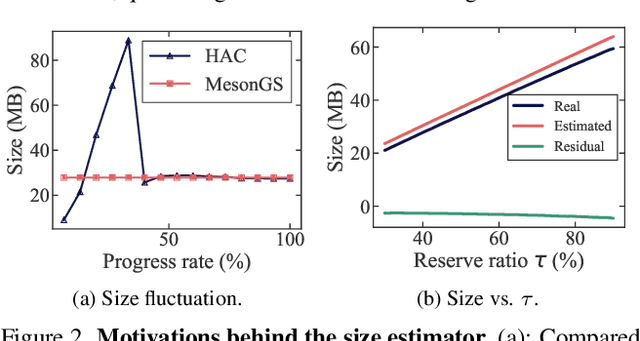

Effective compression technology is crucial for 3DGS to adapt to varying storage and transmission conditions. However, existing methods fail to address size constraints while maintaining optimal quality. In this paper, we introduce SizeGS, a framework that compresses 3DGS within a specified size budget while optimizing visual quality. We start with a size estimator to establish a clear relationship between file size and hyperparameters. Leveraging this estimator, we incorporate mixed precision quantization (MPQ) into 3DGS attributes, structuring MPQ in two hierarchical level -- inter-attribute and intra-attribute -- to optimize visual quality under the size constraint. At the inter-attribute level, we assign bit-widths to each attribute channel by formulating the combinatorial optimization as a 0-1 integer linear program, which can be efficiently solved. At the intra-attribute level, we divide each attribute channel into blocks of vectors, quantizing each vector based on the optimal bit-width derived at the inter-attribute level. Dynamic programming determines block lengths. Using the size estimator and MPQ, we develop a calibrated algorithm to identify optimal hyperparameters in just 10 minutes, achieving a 1.69$\times$ efficiency increase with quality comparable to state-of-the-art methods.
MesonGS: Post-training Compression of 3D Gaussians via Efficient Attribute Transformation
Sep 15, 2024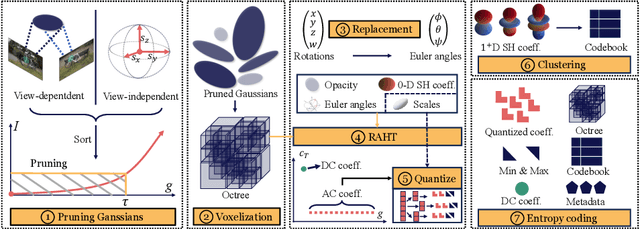
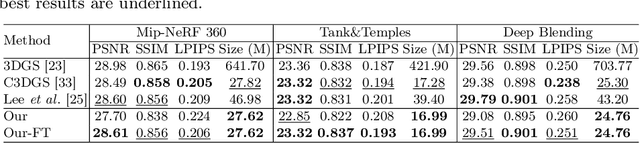
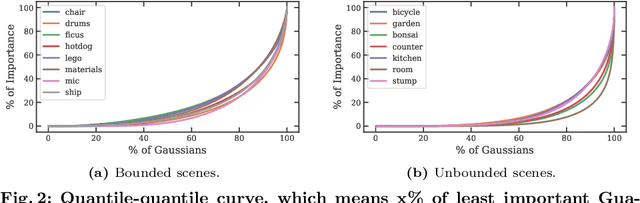
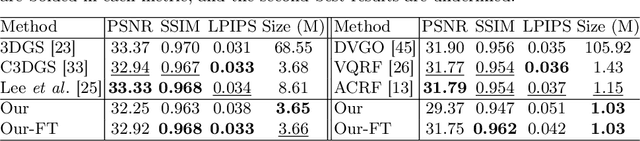
3D Gaussian Splatting demonstrates excellent quality and speed in novel view synthesis. Nevertheless, the huge file size of the 3D Gaussians presents challenges for transmission and storage. Current works design compact models to replace the substantial volume and attributes of 3D Gaussians, along with intensive training to distill information. These endeavors demand considerable training time, presenting formidable hurdles for practical deployment. To this end, we propose MesonGS, a codec for post-training compression of 3D Gaussians. Initially, we introduce a measurement criterion that considers both view-dependent and view-independent factors to assess the impact of each Gaussian point on the rendering output, enabling the removal of insignificant points. Subsequently, we decrease the entropy of attributes through two transformations that complement subsequent entropy coding techniques to enhance the file compression rate. More specifically, we first replace rotation quaternions with Euler angles; then, we apply region adaptive hierarchical transform to key attributes to reduce entropy. Lastly, we adopt finer-grained quantization to avoid excessive information loss. Moreover, a well-crafted finetune scheme is devised to restore quality. Extensive experiments demonstrate that MesonGS significantly reduces the size of 3D Gaussians while preserving competitive quality.
Expansive Supervision for Neural Radiance Field
Sep 12, 2024Neural Radiance Fields have achieved success in creating powerful 3D media representations with their exceptional reconstruction capabilities. However, the computational demands of volume rendering pose significant challenges during model training. Existing acceleration techniques often involve redesigning the model architecture, leading to limitations in compatibility across different frameworks. Furthermore, these methods tend to overlook the substantial memory costs incurred. In response to these challenges, we introduce an expansive supervision mechanism that efficiently balances computational load, rendering quality and flexibility for neural radiance field training. This mechanism operates by selectively rendering a small but crucial subset of pixels and expanding their values to estimate the error across the entire area for each iteration. Compare to conventional supervision, our method effectively bypasses redundant rendering processes, resulting in notable reductions in both time and memory consumption. Experimental results demonstrate that integrating expansive supervision within existing state-of-the-art acceleration frameworks can achieve 69% memory savings and 42% time savings, with negligible compromise in visual quality.