 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Blessing of Pre-training in Weak-to-Strong Generalization
May 07, 2026The paradigm of Weak-to-Strong Generalization (W2SG) suggests that a pre-trained strong model can surpass its weak supervisor, yet the decisive role of pre-training remains theoretically and empirically under-explored. In this work, we identify pre-training as the essential prerequisite for the emergence of W2SG. Theoretically, we formalize the W2SG problem within a high-dimensional single-index model framework using spiked Gaussian data, modeling pre-training as a spectral initialization step. Building upon prior impossibility results regarding the failure of learning under random initialization, we prove that W2SG is achievable when pre-training provides a geometric warm start that places the model within an "effective region" characterized by a perturbed strong-convexity geometry. Within this region, we derive a rigorous generalization bound that naturally captures the optimization dynamics: an initial performance improvement followed by a saturation bottleneck dictated by the weak supervisor's bias. Empirically, we first validate all our assumptions and theoretical insights through controlled synthetic simulations. Finally, through a massive-scale evaluation of hundreds of intermediate pre-training checkpoints from large language models, we demonstrate that W2SG is not an innate capability but emerges via a phase transition tightly coupled with the progression of pre-training.
SynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
Apr 20, 2026Controllable cooperative humanoid manipulation is a fundamental yet challenging problem for embodied intelligence, due to severe data scarcity, complexities in multi-agent coordination, and limited generalization across objects. In this paper, we present SynAgent, a unified framework that enables scalable and physically plausible cooperative manipulation by leveraging Solo-to-Cooperative Agent Synergy to transfer skills from single-agent human-object interaction to multi-agent human-object-human scenarios. To maintain semantic integrity during motion transfer, we introduce an interaction-preserving retargeting method based on an Interact Mesh constructed via Delaunay tetrahedralization, which faithfully maintains spatial relationships among humans and objects. Building upon this refined data, we propose a single-agent pretraining and adaptation paradigm that bootstraps synergistic collaborative behaviors from abundant single-human data through decentralized training and multi-agent PPO. Finally, we develop a trajectory-conditioned generative policy using a conditional VAE, trained via multi-teacher distillation from motion imitation priors to achieve stable and controllable object-level trajectory execution. Extensive experiments demonstrate that SynAgent significantly outperforms existing baselines in both cooperative imitation and trajectory-conditioned control, while generalizing across diverse object geometries. Codes and data will be available after publication. Project Page: http://yw0208.github.io/synagent
Industrial3D: A Terrestrial LiDAR Point Cloud Dataset and CrossParadigm Benchmark for Industrial Infrastructure
Mar 30, 2026Automated semantic understanding of dense point clouds is a prerequisite for Scan-to-BIM pipelines, digital twin construction, and as-built verification--core tasks in the digital transformation of the construction industry. Yet for industrial mechanical, electrical, and plumbing (MEP) facilities, this challenge remains largely unsolved: TLS acquisitions of water treatment plants, chiller halls, and pumping stations exhibit extreme geometric ambiguity, severe occlusion, and extreme class imbalance that architectural benchmarks (e.g., S3DIS or ScanNet) cannot adequately represent. We present Industrial3D, a terrestrial LiDAR dataset comprising 612 million expertly labelled points at 6 mm resolution from 13 water treatment facilities. At 6.6x the scale of the closest comparable MEP dataset, Industrial3D provides the largest and most demanding testbed for industrial 3D scene understanding to date. We further establish the first industrial cross-paradigm benchmark, evaluating nine representative methods across fully supervised, weakly supervised, unsupervised, and foundation model settings under a unified benchmark protocol. The best supervised method achieves 55.74% mIoU, whereas zero-shot Point-SAM reaches only 15.79%--a 39.95 percentage-point gap that quantifies the unresolved domain-transfer challenge for industrial TLS data. Systematic analysis reveals that this gap originates from a dual crisis: statistical rarity (215:1 imbalance, 3.5x more severe than S3DIS) and geometric ambiguity (tail-class points share cylindrical primitives with head-class pipes) that frequency-based re-weighting alone cannot resolve. Industrial3D, along with benchmark code and pre-trained models, will be publicly available at https://github.com/pointcloudyc/Industrial3D.
Resolving Primitive-Sharing Ambiguity in Long-Tailed Industrial Point Cloud Segmentation via Spatial Context Constraints
Jan 27, 2026Industrial point cloud segmentation for Digital Twin construction faces a persistent challenge: safety-critical components such as reducers and valves are systematically misclassified. These failures stem from two compounding factors: such components are rare in training data, yet they share identical local geometry with dominant structures like pipes. This work identifies a dual crisis unique to industrial 3D data extreme class imbalance 215:1 ratio compounded by geometric ambiguity where most tail classes share cylindrical primitives with head classes. Existing frequency-based re-weighting methods address statistical imbalance but cannot resolve geometric ambiguity. We propose spatial context constraints that leverage neighborhood prediction consistency to disambiguate locally similar structures. Our approach extends the Class-Balanced (CB) Loss framework with two architecture-agnostic mechanisms: (1) Boundary-CB, an entropy-based constraint that emphasizes ambiguous boundaries, and (2) Density-CB, a density-based constraint that compensates for scan-dependent variations. Both integrate as plug-and-play modules without network modifications, requiring only loss function replacement. On the Industrial3D dataset (610M points from water treatment facilities), our method achieves 55.74% mIoU with 21.7% relative improvement on tail-class performance (29.59% vs. 24.32% baseline) while preserving head-class accuracy (88.14%). Components with primitive-sharing ambiguity show dramatic gains: reducer improves from 0% to 21.12% IoU; valve improves by 24.3% relative. This resolves geometric ambiguity without the typical head-tail trade-off, enabling reliable identification of safety-critical components for automated knowledge extraction in Digital Twin applications.
Cross-Domain Transfer with Self-Supervised Spectral-Spatial Modeling for Hyperspectral Image Classification
Jan 26, 2026Self-supervised learning has demonstrated considerable potential in hyperspectral representation, yet its application in cross-domain transfer scenarios remains under-explored. Existing methods, however, still rely on source domain annotations and are susceptible to distribution shifts, leading to degraded generalization performance in the target domain. To address this, this paper proposes a self-supervised cross-domain transfer framework that learns transferable spectral-spatial joint representations without source labels and achieves efficient adaptation under few samples in the target domain. During the self-supervised pre-training phase, a Spatial-Spectral Transformer (S2Former) module is designed. It adopts a dual-branch spatial-spectral transformer and introduces a bidirectional cross-attention mechanism to achieve spectral-spatial collaborative modeling: the spatial branch enhances structural awareness through random masking, while the spectral branch captures fine-grained differences. Both branches mutually guide each other to improve semantic consistency. We further propose a Frequency Domain Constraint (FDC) to maintain frequency-domain consistency through real Fast Fourier Transform (rFFT) and high-frequency magnitude loss, thereby enhancing the model's capability to discern fine details and boundaries. During the fine-tuning phase, we introduce a Diffusion-Aligned Fine-tuning (DAFT) distillation mechanism. This aligns semantic evolution trajectories through a teacher-student structure, enabling robust transfer learning under low-label conditions. Experimental results demonstrate stable classification performance and strong cross-domain adaptability across four hyperspectral datasets, validating the method's effectiveness under resource-constrained conditions.
AI-enabled Satellite Edge Computing: A Single-Pixel Feature based Shallow Classification Model for Hyperspectral Imaging
Jan 26, 2026As the important component of the Earth observation system, hyperspectral imaging satellites provide high-fidelity and enriched information for the formulation of related policies due to the powerful spectral measurement capabilities. However, the transmission speed of the satellite downlink has become a major bottleneck in certain applications, such as disaster monitoring and emergency mapping, which demand a fast response ability. We propose an efficient AI-enabled Satellite Edge Computing paradigm for hyperspectral image classification, facilitating the satellites to attain autonomous decision-making. To accommodate the resource constraints of satellite platforms, the proposed method adopts a lightweight, non-deep learning framework integrated with a few-shot learning strategy. Moreover, onboard processing on satellites could be faced with sensor failure and scan pattern errors, which result in degraded image quality with bad/misaligned pixels and mixed noise. To address these challenges, we develop a novel two-stage pixel-wise label propagation scheme that utilizes only intrinsic spectral features at the single pixel level without the necessity to consider spatial structural information as requested by deep neural networks. In the first stage, initial pixel labels are obtained by propagating selected anchor labels through the constructed anchor-pixel affinity matrix. Subsequently, a top-k pruned sparse graph is generated by directly computing pixel-level similarities. In the second stage, a closed-form solution derived from the sparse graph is employed to replace iterative computations. Furthermore, we developed a rank constraint-based graph clustering algorithm to determine the anchor labels.
Beyond the Black Box: Theory and Mechanism of Large Language Models
Jan 06, 2026The rapid emergence of Large Language Models (LLMs) has precipitated a profound paradigm shift in Artificial Intelligence, delivering monumental engineering successes that increasingly impact modern society. However, a critical paradox persists within the current field: despite the empirical efficacy, our theoretical understanding of LLMs remains disproportionately nascent, forcing these systems to be treated largely as ``black boxes''. To address this theoretical fragmentation, this survey proposes a unified lifecycle-based taxonomy that organizes the research landscape into six distinct stages: Data Preparation, Model Preparation, Training, Alignment, Inference, and Evaluation. Within this framework, we provide a systematic review of the foundational theories and internal mechanisms driving LLM performance. Specifically, we analyze core theoretical issues such as the mathematical justification for data mixtures, the representational limits of various architectures, and the optimization dynamics of alignment algorithms. Moving beyond current best practices, we identify critical frontier challenges, including the theoretical limits of synthetic data self-improvement, the mathematical bounds of safety guarantees, and the mechanistic origins of emergent intelligence. By connecting empirical observations with rigorous scientific inquiry, this work provides a structured roadmap for transitioning LLM development from engineering heuristics toward a principled scientific discipline.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025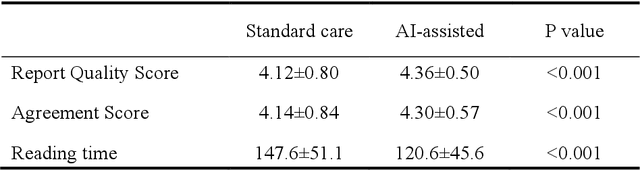
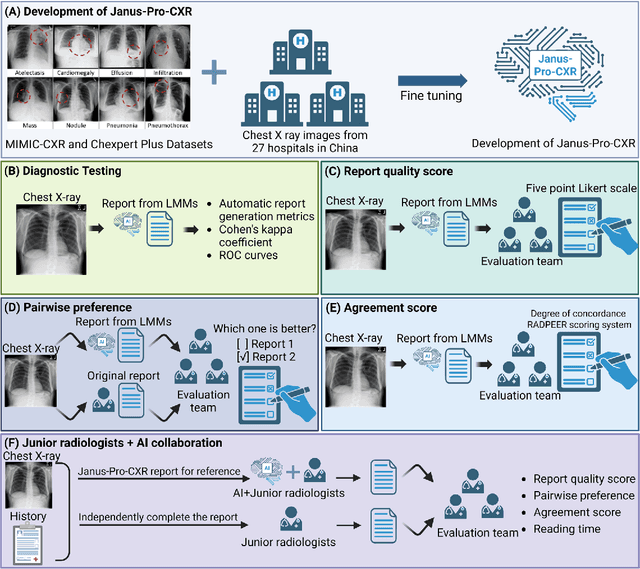
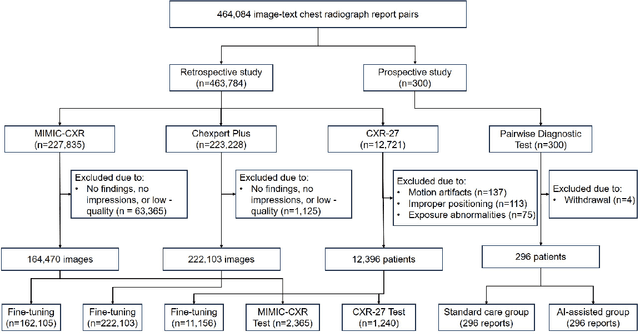
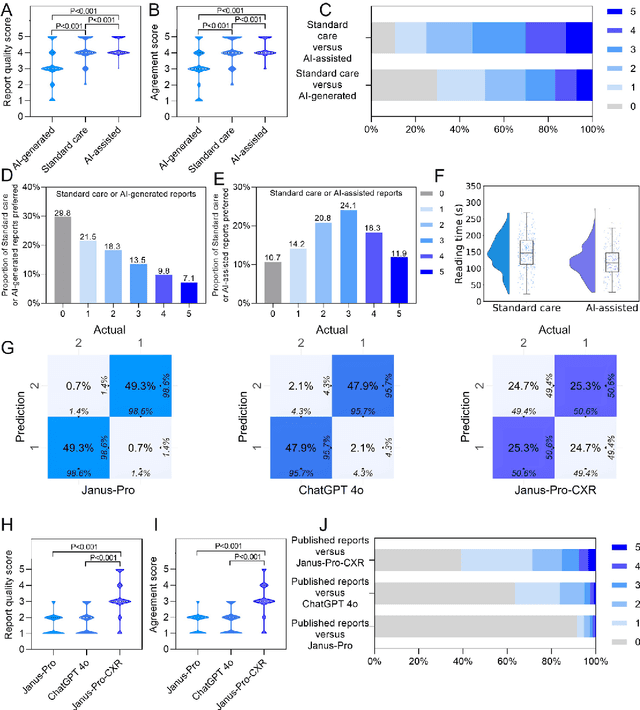
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn LLM Agents
Oct 16, 2025Large language model (LLM)-based agents are increasingly trained with reinforcement learning (RL) to enhance their ability to interact with external environments through tool use, particularly in search-based settings that require multi-turn reasoning and knowledge acquisition. However, existing approaches typically rely on outcome-based rewards that are only provided at the final answer. This reward sparsity becomes particularly problematic in multi-turn settings, where long trajectories exacerbate two critical issues: (i) advantage collapse, where all rollouts receive identical rewards and provide no useful learning signals, and (ii) lack of fine-grained credit assignment, where dependencies between turns are obscured, especially in long-horizon tasks. In this paper, we propose Information Gain-based Policy Optimization (IGPO), a simple yet effective RL framework that provides dense and intrinsic supervision for multi-turn agent training. IGPO models each interaction turn as an incremental process of acquiring information about the ground truth, and defines turn-level rewards as the marginal increase in the policy's probability of producing the correct answer. Unlike prior process-level reward approaches that depend on external reward models or costly Monte Carlo estimation, IGPO derives intrinsic rewards directly from the model's own belief updates. These intrinsic turn-level rewards are combined with outcome-level supervision to form dense reward trajectories. Extensive experiments on both in-domain and out-of-domain benchmarks demonstrate that IGPO consistently outperforms strong baselines in multi-turn scenarios, achieving higher accuracy and improved sample efficiency.
TemporalFlowViz: Parameter-Aware Visual Analytics for Interpreting Scramjet Combustion Evolution
Sep 05, 2025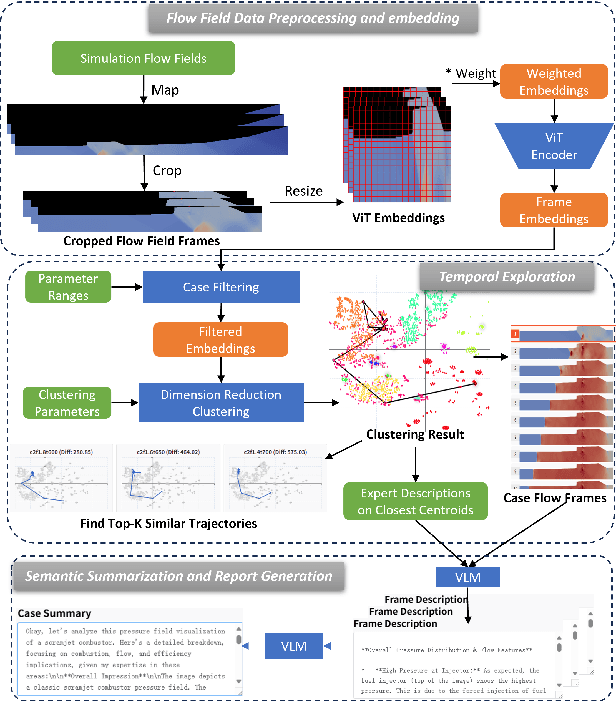
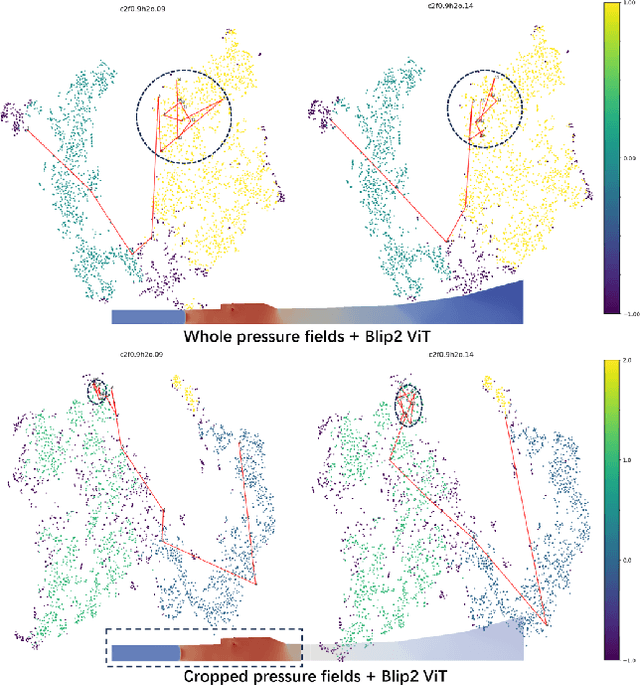
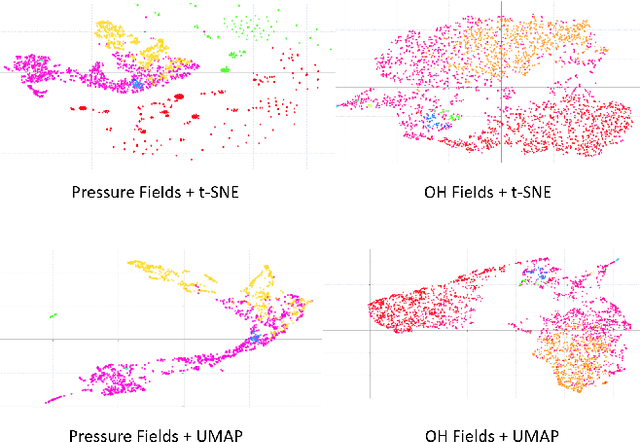
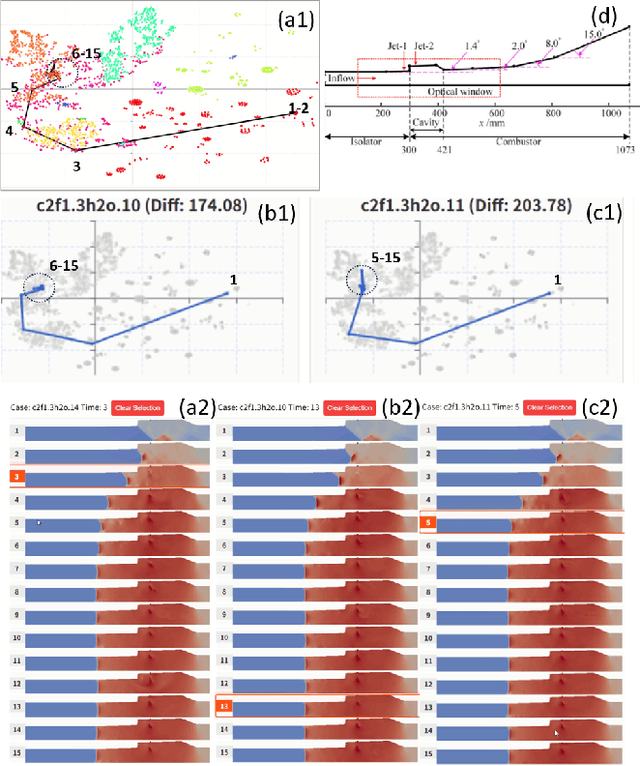
Understanding the complex combustion dynamics within scramjet engines is critical for advancing high-speed propulsion technologies. However, the large scale and high dimensionality of simulation-generated temporal flow field data present significant challenges for visual interpretation, feature differentiation, and cross-case comparison. In this paper, we present TemporalFlowViz, a parameter-aware visual analytics workflow and system designed to support expert-driven clustering, visualization, and interpretation of temporal flow fields from scramjet combustion simulations. Our approach leverages hundreds of simulated combustion cases with varying initial conditions, each producing time-sequenced flow field images. We use pretrained Vision Transformers to extract high-dimensional embeddings from these frames, apply dimensionality reduction and density-based clustering to uncover latent combustion modes, and construct temporal trajectories in the embedding space to track the evolution of each simulation over time. To bridge the gap between latent representations and expert reasoning, domain specialists annotate representative cluster centroids with descriptive labels. These annotations are used as contextual prompts for a vision-language model, which generates natural-language summaries for individual frames and full simulation cases. The system also supports parameter-based filtering, similarity-based case retrieval, and coordinated multi-view exploration to facilitate in-depth analysis. We demonstrate the effectiveness of TemporalFlowViz through two expert-informed case studies and expert feedback, showing TemporalFlowViz enhances hypothesis generation, supports interpretable pattern discovery, and enhances knowledge discovery in large-scale scramjet combustion analysis.