 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
SD-GS: Structured Deformable 3D Gaussians for Efficient Dynamic Scene Reconstruction
Jul 10, 2025Current 4D Gaussian frameworks for dynamic scene reconstruction deliver impressive visual fidelity and rendering speed, however, the inherent trade-off between storage costs and the ability to characterize complex physical motions significantly limits the practical application of these methods. To tackle these problems, we propose SD-GS, a compact and efficient dynamic Gaussian splatting framework for complex dynamic scene reconstruction, featuring two key contributions. First, we introduce a deformable anchor grid, a hierarchical and memory-efficient scene representation where each anchor point derives multiple 3D Gaussians in its local spatiotemporal region and serves as the geometric backbone of the 3D scene. Second, to enhance modeling capability for complex motions, we present a deformation-aware densification strategy that adaptively grows anchors in under-reconstructed high-dynamic regions while reducing redundancy in static areas, achieving superior visual quality with fewer anchors. Experimental results demonstrate that, compared to state-of-the-art methods, SD-GS achieves an average of 60\% reduction in model size and an average of 100\% improvement in FPS, significantly enhancing computational efficiency while maintaining or even surpassing visual quality.
Visual Large Language Models for Generalized and Specialized Applications
Jan 06, 2025



Visual-language models (VLM) have emerged as a powerful tool for learning a unified embedding space for vision and language. Inspired by large language models, which have demonstrated strong reasoning and multi-task capabilities, visual large language models (VLLMs) are gaining increasing attention for building general-purpose VLMs. Despite the significant progress made in VLLMs, the related literature remains limited, particularly from a comprehensive application perspective, encompassing generalized and specialized applications across vision (image, video, depth), action, and language modalities. In this survey, we focus on the diverse applications of VLLMs, examining their using scenarios, identifying ethics consideration and challenges, and discussing future directions for their development. By synthesizing these contents, we aim to provide a comprehensive guide that will pave the way for future innovations and broader applications of VLLMs. The paper list repository is available: https://github.com/JackYFL/awesome-VLLMs.
CROPS: A Deployable Crop Management System Over All Possible State Availabilities
Nov 09, 2024



Exploring the optimal management strategy for nitrogen and irrigation has a significant impact on crop yield, economic profit, and the environment. To tackle this optimization challenge, this paper introduces a deployable \textbf{CR}op Management system \textbf{O}ver all \textbf{P}ossible \textbf{S}tate availabilities (CROPS). CROPS employs a language model (LM) as a reinforcement learning (RL) agent to explore optimal management strategies within the Decision Support System for Agrotechnology Transfer (DSSAT) crop simulations. A distinguishing feature of this system is that the states used for decision-making are partially observed through random masking. Consequently, the RL agent is tasked with two primary objectives: optimizing management policies and inferring masked states. This approach significantly enhances the RL agent's robustness and adaptability across various real-world agricultural scenarios. Extensive experiments on maize crops in Florida, USA, and Zaragoza, Spain, validate the effectiveness of CROPS. Not only did CROPS achieve State-of-the-Art (SOTA) results across various evaluation metrics such as production, profit, and sustainability, but the trained management policies are also immediately deployable in over of ten millions of real-world contexts. Furthermore, the pre-trained policies possess a noise resilience property, which enables them to minimize potential sensor biases, ensuring robustness and generalizability. Finally, unlike previous methods, the strength of CROPS lies in its unified and elegant structure, which eliminates the need for pre-defined states or multi-stage training. These advancements highlight the potential of CROPS in revolutionizing agricultural practices.
R-LLaVA: Improving Med-VQA Understanding through Visual Region of Interest
Oct 27, 2024



Artificial intelligence has made significant strides in medical visual question answering (Med-VQA), yet prevalent studies often interpret images holistically, overlooking the visual regions of interest that may contain crucial information, potentially aligning with a doctor's prior knowledge that can be incorporated with minimal annotations (e.g., bounding boxes). To address this gap, this paper introduces R-LLaVA, designed to enhance biomedical VQA understanding by integrating simple medical annotations as prior knowledge directly into the image space through CLIP. These annotated visual regions of interest are then fed into the LLaVA model during training, aiming to enrich the model's understanding of biomedical queries. Experimental evaluation on four standard Med-VQA datasets demonstrates R-LLaVA's superiority over existing state-of-the-art (SoTA) methods. Additionally, to verify the model's capability in visual comprehension, a novel multiple-choice medical visual understanding dataset is introduced, confirming the positive impact of focusing on visual regions of interest in advancing biomedical VQA understanding.
Multimodal Pragmatic Jailbreak on Text-to-image Models
Sep 27, 2024

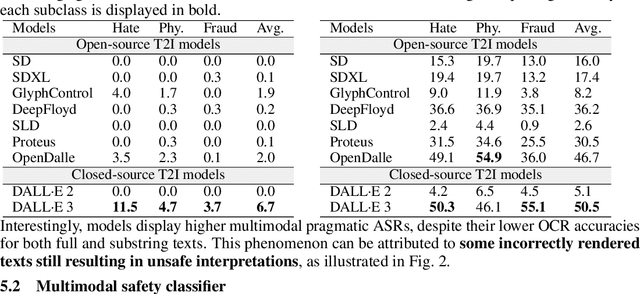

Diffusion models have recently achieved remarkable advancements in terms of image quality and fidelity to textual prompts. Concurrently, the safety of such generative models has become an area of growing concern. This work introduces a novel type of jailbreak, which triggers T2I models to generate the image with visual text, where the image and the text, although considered to be safe in isolation, combine to form unsafe content. To systematically explore this phenomenon, we propose a dataset to evaluate the current diffusion-based text-to-image (T2I) models under such jailbreak. We benchmark nine representative T2I models, including two close-source commercial models. Experimental results reveal a concerning tendency to produce unsafe content: all tested models suffer from such type of jailbreak, with rates of unsafe generation ranging from 8\% to 74\%. In real-world scenarios, various filters such as keyword blocklists, customized prompt filters, and NSFW image filters, are commonly employed to mitigate these risks. We evaluate the effectiveness of such filters against our jailbreak and found that, while current classifiers may be effective for single modality detection, they fail to work against our jailbreak. Our work provides a foundation for further development towards more secure and reliable T2I models.
InsectMamba: Insect Pest Classification with State Space Model
Apr 04, 2024



The classification of insect pests is a critical task in agricultural technology, vital for ensuring food security and environmental sustainability. However, the complexity of pest identification, due to factors like high camouflage and species diversity, poses significant obstacles. Existing methods struggle with the fine-grained feature extraction needed to distinguish between closely related pest species. Although recent advancements have utilized modified network structures and combined deep learning approaches to improve accuracy, challenges persist due to the similarity between pests and their surroundings. To address this problem, we introduce InsectMamba, a novel approach that integrates State Space Models (SSMs), Convolutional Neural Networks (CNNs), Multi-Head Self-Attention mechanism (MSA), and Multilayer Perceptrons (MLPs) within Mix-SSM blocks. This integration facilitates the extraction of comprehensive visual features by leveraging the strengths of each encoding strategy. A selective module is also proposed to adaptively aggregate these features, enhancing the model's ability to discern pest characteristics. InsectMamba was evaluated against strong competitors across five insect pest classification datasets. The results demonstrate its superior performance and verify the significance of each model component by an ablation study.
The New Agronomists: Language Models are Experts in Crop Management
Mar 28, 2024


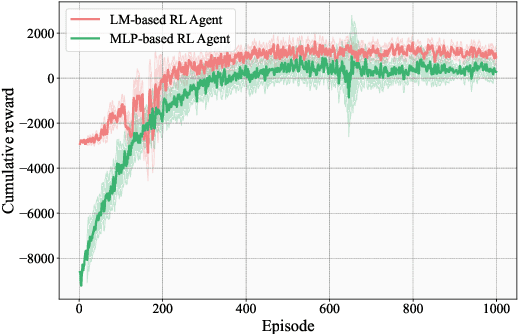
Crop management plays a crucial role in determining crop yield, economic profitability, and environmental sustainability. Despite the availability of management guidelines, optimizing these practices remains a complex and multifaceted challenge. In response, previous studies have explored using reinforcement learning with crop simulators, typically employing simple neural-network-based reinforcement learning (RL) agents. Building on this foundation, this paper introduces a more advanced intelligent crop management system. This system uniquely combines RL, a language model (LM), and crop simulations facilitated by the Decision Support System for Agrotechnology Transfer (DSSAT). We utilize deep RL, specifically a deep Q-network, to train management policies that process numerous state variables from the simulator as observations. A novel aspect of our approach is the conversion of these state variables into more informative language, facilitating the language model's capacity to understand states and explore optimal management practices. The empirical results reveal that the LM exhibits superior learning capabilities. Through simulation experiments with maize crops in Florida (US) and Zaragoza (Spain), the LM not only achieves state-of-the-art performance under various evaluation metrics but also demonstrates a remarkable improvement of over 49\% in economic profit, coupled with reduced environmental impact when compared to baseline methods. Our code is available at \url{https://github.com/jingwu6/LM_AG}.
Residual-based Language Models are Free Boosters for Biomedical Imaging
Mar 28, 2024



In this study, we uncover the unexpected efficacy of residual-based large language models (LLMs) as part of encoders for biomedical imaging tasks, a domain traditionally devoid of language or textual data. The approach diverges from established methodologies by utilizing a frozen transformer block, extracted from pre-trained LLMs, as an innovative encoder layer for the direct processing of visual tokens. This strategy represents a significant departure from the standard multi-modal vision-language frameworks, which typically hinge on language-driven prompts and inputs. We found that these LLMs could boost performance across a spectrum of biomedical imaging applications, including both 2D and 3D visual classification tasks, serving as plug-and-play boosters. More interestingly, as a byproduct, we found that the proposed framework achieved superior performance, setting new state-of-the-art results on extensive, standardized datasets in MedMNIST-2D and 3D. Through this work, we aim to open new avenues for employing LLMs in biomedical imaging and enriching the understanding of their potential in this specialized domain.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.