 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROPS: A Deployable Crop Management System Over All Possible State Availabilities
Nov 09, 2024



Exploring the optimal management strategy for nitrogen and irrigation has a significant impact on crop yield, economic profit, and the environment. To tackle this optimization challenge, this paper introduces a deployable \textbf{CR}op Management system \textbf{O}ver all \textbf{P}ossible \textbf{S}tate availabilities (CROPS). CROPS employs a language model (LM) as a reinforcement learning (RL) agent to explore optimal management strategies within the Decision Support System for Agrotechnology Transfer (DSSAT) crop simulations. A distinguishing feature of this system is that the states used for decision-making are partially observed through random masking. Consequently, the RL agent is tasked with two primary objectives: optimizing management policies and inferring masked states. This approach significantly enhances the RL agent's robustness and adaptability across various real-world agricultural scenarios. Extensive experiments on maize crops in Florida, USA, and Zaragoza, Spain, validate the effectiveness of CROPS. Not only did CROPS achieve State-of-the-Art (SOTA) results across various evaluation metrics such as production, profit, and sustainability, but the trained management policies are also immediately deployable in over of ten millions of real-world contexts. Furthermore, the pre-trained policies possess a noise resilience property, which enables them to minimize potential sensor biases, ensuring robustness and generalizability. Finally, unlike previous methods, the strength of CROPS lies in its unified and elegant structure, which eliminates the need for pre-defined states or multi-stage training. These advancements highlight the potential of CROPS in revolutionizing agricultural practices.
Transformer Based Tissue Classification in Robotic Needle Biopsy
Sep 07, 2024



Image-guided minimally invasive robotic surgery is commonly employed for tasks such as needle biopsies or localized therapies. However, the nonlinear deformation of various tissue types presents difficulties for surgeons in achieving precise needle tip placement, particularly when relying on low-fidelity biopsy imaging systems. In this paper, we introduce a method to classify needle biopsy interventions and identify tissue types based on a comprehensive needle-tissue contact model that incorporates both position and force parameters. We trained a transformer model using a comprehensive dataset collected from a formerly developed robotics platform, which consists of synthetic and porcine tissue from various locations (liver, kidney, heart, belly, hock) marked with interaction phases (pre-puncture, puncture, post-puncture, neutral). This model achieves a significant classification accuracy of 0.93. Our demonstrated method can assist surgeons in identifying transitions to different tissues, aiding surgeons with tissue awareness.
* 8 pages
Safe Model-Free Reinforcement Learning using Disturbance-Observer-Based Control Barrier Functions
Nov 30, 2022Safe reinforcement learning (RL) with assured satisfaction of hard state constraints during training has recently received a lot of attention. Safety filters, e.g., based on control barrier functions (CBFs), provide a promising way for safe RL via modifying the unsafe actions of an RL agent on the fly. Existing safety filter-based approaches typically involve learning of uncertain dynamics and quantifying the learned model error, which leads to conservative filters before a large amount of data is collected to learn a good model, thereby preventing efficient exploration. This paper presents a method for safe and efficient model-free RL using disturbance observers (DOBs) and control barrier functions (CBFs). Unlike most existing safe RL methods that deal with hard state constraints, our method does not involve model learning, and leverages DOBs to accurately estimate the pointwise value of the uncertainty, which is then incorporated into a robust CBF condition to generate safe actions. The DOB-based CBF can be used as a safety filter with any model-free RL algorithms by minimally modifying the actions of an RL agent whenever necessary to ensure safety throughout the learning process. Simulation results on a unicycle and a 2D quadrotor demonstrate that the proposed method outperforms a state-of-the-art safe RL algorithm using CBFs and Gaussian processes-based model learning, in terms of safety violation rate, and sample and computational efficiency.
Guaranteed Contraction Control in the Presence of Imperfectly Learned Dynamics
Dec 15, 2021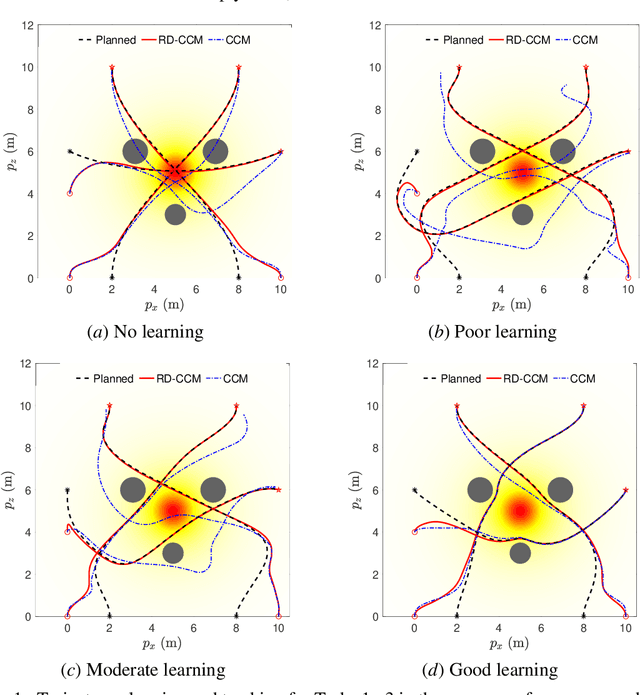
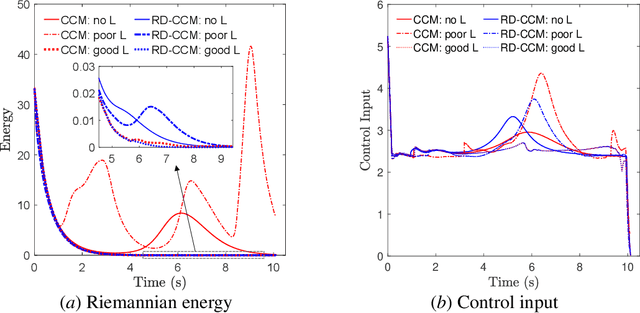
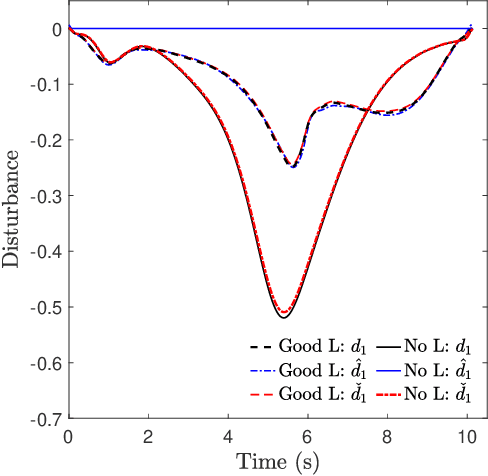
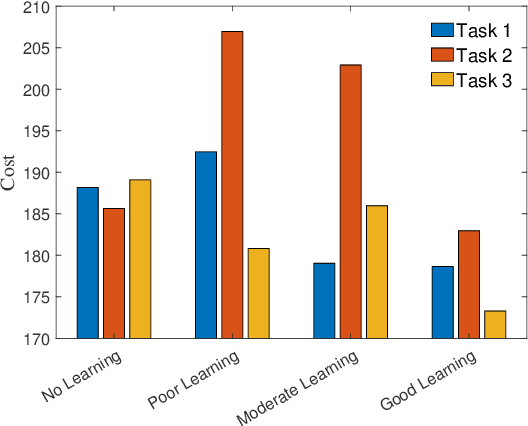
This paper presents an approach for trajectory-centric learning control based on contraction metrics and disturbance estimation for nonlinear systems subject to matched uncertainties. The approach allows for the use of a broad class of model learning tools including deep neural networks to learn uncertain dynamics while still providing guarantees of transient tracking performance throughout the learning phase, including the special case of no learning. Within the proposed approach, a disturbance estimation law is proposed to estimate the pointwise value of the uncertainty, with pre-computable estimation error bounds (EEBs). The learned dynamics, the estimated disturbances, and the EEBs are then incorporated in a robust Riemannian energy condition to compute the control law that guarantees exponential convergence of actual trajectories to desired ones throughout the learning phase, even when the learned model is poor. On the other hand, with improved accuracy, the learned model can be incorporated in a high-level planner to plan better trajectories with improved performance, e.g., lower energy consumption and shorter travel time. The proposed framework is validated on a planar quadrotor navigation example.
Robustifying Reinforcement Learning Policies with $\mathcal{L}_1$ Adaptive Control
Jun 04, 2021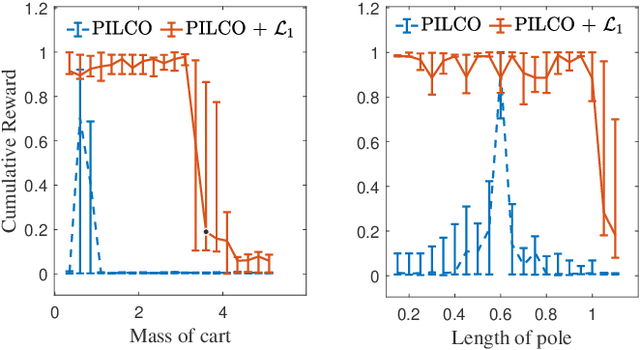
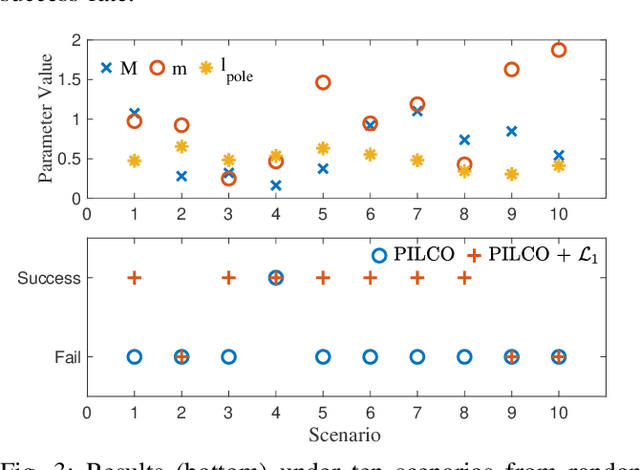
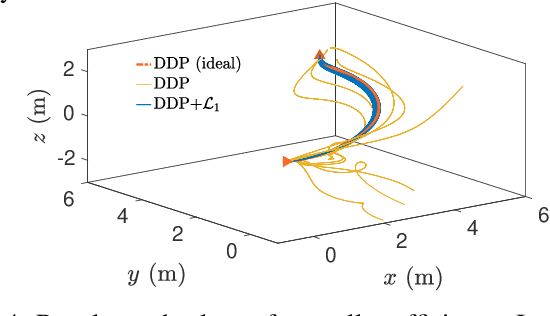
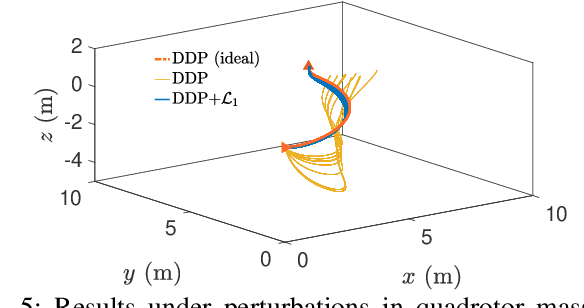
A reinforcement learning (RL) policy trained in a nominal environment could fail in a new/perturbed environment due to the existence of dynamic variations. Existing robust methods try to obtain a fixed policy for all envisioned dynamic variation scenarios through robust or adversarial training. These methods could lead to conservative performance due to emphasis on the worst case, and often involve tedious modifications to the training environment. We propose an approach to robustifying a pre-trained non-robust RL policy with $\mathcal{L}_1$ adaptive control. Leveraging the capability of an $\mathcal{L}_1$ control law in the fast estimation of and active compensation for dynamic variations, our approach can significantly improve the robustness of an RL policy trained in a standard (i.e., non-robust) way, either in a simulator or in the real world. Numerical experiments are provided to validate the efficacy of the proposed approach.