 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Memory Compression for Efficient Multi-Agent Debate
Jan 31, 2026Multi-agent debate can improve reasoning quality and reduce hallucinations, but it incurs rapidly growing context as debate rounds and agent count increase. Retaining full textual histories leads to token usage that can exceed context limits and often requires repeated summarization, adding overhead and compounding information loss. We introduce DebateOCR, a cross-modal compression framework that replaces long textual debate traces with compact image representations, which are then consumed through a dedicated vision encoder to condition subsequent rounds. This design compresses histories that commonly span tens to hundreds of thousands of tokens, cutting input tokens by more than 92% and yielding substantially lower compute cost and faster inference across multiple benchmarks. We further provide a theoretical perspective showing that diversity across agents supports recovery of omitted information: although any single compressed history may discard details, aggregating multiple agents' compressed views allows the collective representation to approach the information bottleneck with exponentially high probability.
TabDeco: A Comprehensive Contrastive Framework for Decoupled Representations in Tabular Data
Nov 17, 2024



Representation learning is a fundamental aspect of modern artificial intelligence, driving substantial improvements across diverse applications. While selfsupervised contrastive learning has led to significant advancements in fields like computer vision and natural language processing, its adaptation to tabular data presents unique challenges. Traditional approaches often prioritize optimizing model architecture and loss functions but may overlook the crucial task of constructing meaningful positive and negative sample pairs from various perspectives like feature interactions, instance-level patterns and batch-specific contexts. To address these challenges, we introduce TabDeco, a novel method that leverages attention-based encoding strategies across both rows and columns and employs contrastive learning framework to effectively disentangle feature representations at multiple levels, including features, instances and data batches. With the innovative feature decoupling hierarchies, TabDeco consistently surpasses existing deep learning methods and leading gradient boosting algorithms, including XG-Boost, CatBoost, and LightGBM, across various benchmark tasks, underscoring its effectiveness in advancing tabular data representation learning.
CROPS: A Deployable Crop Management System Over All Possible State Availabilities
Nov 09, 2024



Exploring the optimal management strategy for nitrogen and irrigation has a significant impact on crop yield, economic profit, and the environment. To tackle this optimization challenge, this paper introduces a deployable \textbf{CR}op Management system \textbf{O}ver all \textbf{P}ossible \textbf{S}tate availabilities (CROPS). CROPS employs a language model (LM) as a reinforcement learning (RL) agent to explore optimal management strategies within the Decision Support System for Agrotechnology Transfer (DSSAT) crop simulations. A distinguishing feature of this system is that the states used for decision-making are partially observed through random masking. Consequently, the RL agent is tasked with two primary objectives: optimizing management policies and inferring masked states. This approach significantly enhances the RL agent's robustness and adaptability across various real-world agricultural scenarios. Extensive experiments on maize crops in Florida, USA, and Zaragoza, Spain, validate the effectiveness of CROPS. Not only did CROPS achieve State-of-the-Art (SOTA) results across various evaluation metrics such as production, profit, and sustainability, but the trained management policies are also immediately deployable in over of ten millions of real-world contexts. Furthermore, the pre-trained policies possess a noise resilience property, which enables them to minimize potential sensor biases, ensuring robustness and generalizability. Finally, unlike previous methods, the strength of CROPS lies in its unified and elegant structure, which eliminates the need for pre-defined states or multi-stage training. These advancements highlight the potential of CROPS in revolutionizing agricultural practices.
Deep Representation Learning for Multi-functional Degradation Modeling of Community-dwelling Aging Population
Apr 08, 2024



As the aging population grows, particularly for the baby boomer generation, the United States is witnessing a significant increase in the elderly population experiencing multifunctional disabilities. These disabilities, stemming from a variety of chronic diseases, injuries, and impairments, present a complex challenge due to their multidimensional nature, encompassing both physical and cognitive aspects. Traditional methods often use univariate regression-based methods to model and predict single degradation conditions and assume population homogeneity, which is inadequate to address the complexity and diversity of aging-related degradation. This study introduces a novel framework for multi-functional degradation modeling that captures the multidimensional (e.g., physical and cognitive) and heterogeneous nature of elderly disabilities. Utilizing deep learning, our approach predicts health degradation scores and uncovers latent heterogeneity from elderly health histories, offering both efficient estimation and explainable insights into the diverse effects and causes of aging-related degradation. A real-case study demonstrates the effectiveness and marks a pivotal contribution to accurately modeling the intricate dynamics of elderly degradation, and addresses the healthcare challenges in the aging population.
Residual-based Language Models are Free Boosters for Biomedical Imaging
Mar 28, 2024



In this study, we uncover the unexpected efficacy of residual-based large language models (LLMs) as part of encoders for biomedical imaging tasks, a domain traditionally devoid of language or textual data. The approach diverges from established methodologies by utilizing a frozen transformer block, extracted from pre-trained LLMs, as an innovative encoder layer for the direct processing of visual tokens. This strategy represents a significant departure from the standard multi-modal vision-language frameworks, which typically hinge on language-driven prompts and inputs. We found that these LLMs could boost performance across a spectrum of biomedical imaging applications, including both 2D and 3D visual classification tasks, serving as plug-and-play boosters. More interestingly, as a byproduct, we found that the proposed framework achieved superior performance, setting new state-of-the-art results on extensive, standardized datasets in MedMNIST-2D and 3D. Through this work, we aim to open new avenues for employing LLMs in biomedical imaging and enriching the understanding of their potential in this specialized domain.
The New Agronomists: Language Models are Experts in Crop Management
Mar 28, 2024


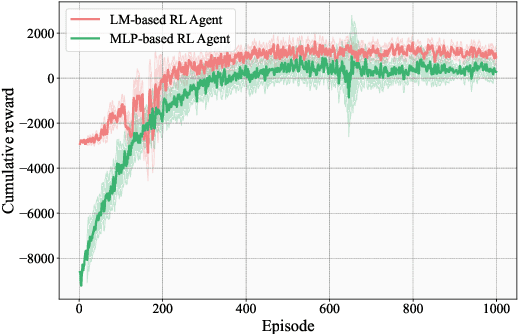
Crop management plays a crucial role in determining crop yield, economic profitability, and environmental sustainability. Despite the availability of management guidelines, optimizing these practices remains a complex and multifaceted challenge. In response, previous studies have explored using reinforcement learning with crop simulators, typically employing simple neural-network-based reinforcement learning (RL) agents. Building on this foundation, this paper introduces a more advanced intelligent crop management system. This system uniquely combines RL, a language model (LM), and crop simulations facilitated by the Decision Support System for Agrotechnology Transfer (DSSAT). We utilize deep RL, specifically a deep Q-network, to train management policies that process numerous state variables from the simulator as observations. A novel aspect of our approach is the conversion of these state variables into more informative language, facilitating the language model's capacity to understand states and explore optimal management practices. The empirical results reveal that the LM exhibits superior learning capabilities. Through simulation experiments with maize crops in Florida (US) and Zaragoza (Spain), the LM not only achieves state-of-the-art performance under various evaluation metrics but also demonstrates a remarkable improvement of over 49\% in economic profit, coupled with reduced environmental impact when compared to baseline methods. Our code is available at \url{https://github.com/jingwu6/LM_AG}.
Adaptive Ensembles of Fine-Tuned Transformers for LLM-Generated Text Detection
Mar 20, 2024



Large language models (LLMs) have reached human-like proficiency in generating diverse textual content, underscoring the necessity for effective fake text detection to avoid potential risks such as fake news in social media. Previous research has mostly tested single models on in-distribution datasets, limiting our understanding of how these models perform on different types of data for LLM-generated text detection task. We researched this by testing five specialized transformer-based models on both in-distribution and out-of-distribution datasets to better assess their performance and generalizability. Our results revealed that single transformer-based classifiers achieved decent performance on in-distribution dataset but limited generalization ability on out-of-distribution dataset. To improve it, we combined the individual classifiers models using adaptive ensemble algorithms, which improved the average accuracy significantly from 91.8% to 99.2% on an in-distribution test set and from 62.9% to 72.5% on an out-of-distribution test set. The results indicate the effectiveness, good generalization ability, and great potential of adaptive ensemble algorithms in LLM-generated text detection.
SwitchTab: Switched Autoencoders Are Effective Tabular Learners
Jan 04, 2024Self-supervised representation learning methods have achieved significant success in computer vision and natural language processing, where data samples exhibit explicit spatial or semantic dependencies. However, applying these methods to tabular data is challenging due to the less pronounced dependencies among data samples. In this paper, we address this limitation by introducing SwitchTab, a novel self-supervised method specifically designed to capture latent dependencies in tabular data. SwitchTab leverages an asymmetric encoder-decoder framework to decouple mutual and salient features among data pairs, resulting in more representative embeddings. These embeddings, in turn, contribute to better decision boundaries and lead to improved results in downstream tasks. To validate the effectiveness of SwitchTab, we conduct extensive experiments across various domains involving tabular data. The results showcase superior performance in end-to-end prediction tasks with fine-tuning. Moreover, we demonstrate that pre-trained salient embeddings can be utilized as plug-and-play features to enhance the performance of various traditional classification methods (e.g., Logistic Regression, XGBoost, etc.). Lastly, we highlight the capability of SwitchTab to create explainable representations through visualization of decoupled mutual and salient features in the latent space.
ReConTab: Regularized Contrastive Representation Learning for Tabular Data
Oct 28, 2023Representation learning stands as one of the critical machine learning techniques across various domains. Through the acquisition of high-quality features, pre-trained embeddings significantly reduce input space redundancy, benefiting downstream pattern recognition tasks such as classification, regression, or detection. Nonetheless, in the domain of tabular data, feature engineering and selection still heavily rely on manual intervention, leading to time-consuming processes and necessitating domain expertise. In response to this challenge, we introduce ReConTab, a deep automatic representation learning framework with regularized contrastive learning. Agnostic to any type of modeling task, ReConTab constructs an asymmetric autoencoder based on the same raw features from model inputs, producing low-dimensional representative embeddings. Specifically, regularization techniques are applied for raw feature selection. Meanwhile, ReConTab leverages contrastive learning to distill the most pertinent information for downstream tasks. Experiments conducted on extensive real-world datasets substantiate the framework's capacity to yield substantial and robust performance improvements. Furthermore, we empirically demonstrate that pre-trained embeddings can seamlessly integrate as easily adaptable features, enhancing the performance of various traditional methods such as XGBoost and Random Forest.