 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotiMem: Motion-Aware Approximate Memory for Energy-Efficient Neural Perception in Autonomous Vehicles
Mar 28, 2026High-resolution sensors are critical for robust autonomous perception but impose a severe memory wall on battery-constrained electric vehicles. In these systems, data movement energy often outweighs computation. Traditional image compression is ill-suited as it is semantically blind and optimizes for storage rather than bus switching activity. We propose MotiMem, a hardware-software co-designed interface. Exploiting temporal coherence,MotiMem uses lightweight 2D Motion Propagation to dynamically identify Regions of Interest (RoI). Complementing this, a Hybrid Sparsity-Aware Coding scheme leverages adaptive inversion and truncation to induce bitlevel sparsity. Extensive experiments across nuScenes, Waymo, and KITTI with 16 detection models demonstrate that MotiMem reduces memory-interface dynamic energy by approximately 43 percent while retaining approximately 93 percent of the object detection accuracy, establishing a new Pareto frontier significantly superior to standard codecs like JPEG and WebP.
MACE: Mixture-of-Experts Accelerated Coordinate Encoding for Large-Scale Scene Localization and Rendering
Oct 16, 2025Efficient localization and high-quality rendering in large-scale scenes remain a significant challenge due to the computational cost involved. While Scene Coordinate Regression (SCR) methods perform well in small-scale localization, they are limited by the capacity of a single network when extended to large-scale scenes. To address these challenges, we propose the Mixed Expert-based Accelerated Coordinate Encoding method (MACE), which enables efficient localization and high-quality rendering in large-scale scenes. Inspired by the remarkable capabilities of MOE in large model domains, we introduce a gating network to implicitly classify and select sub-networks, ensuring that only a single sub-network is activated during each inference. Furtheremore, we present Auxiliary-Loss-Free Load Balancing(ALF-LB) strategy to enhance the localization accuracy on large-scale scene. Our framework provides a significant reduction in costs while maintaining higher precision, offering an efficient solution for large-scale scene applications. Additional experiments on the Cambridge test set demonstrate that our method achieves high-quality rendering results with merely 10 minutes of training.
Deep Representation Learning for Multi-functional Degradation Modeling of Community-dwelling Aging Population
Apr 08, 2024



As the aging population grows, particularly for the baby boomer generation, the United States is witnessing a significant increase in the elderly population experiencing multifunctional disabilities. These disabilities, stemming from a variety of chronic diseases, injuries, and impairments, present a complex challenge due to their multidimensional nature, encompassing both physical and cognitive aspects. Traditional methods often use univariate regression-based methods to model and predict single degradation conditions and assume population homogeneity, which is inadequate to address the complexity and diversity of aging-related degradation. This study introduces a novel framework for multi-functional degradation modeling that captures the multidimensional (e.g., physical and cognitive) and heterogeneous nature of elderly disabilities. Utilizing deep learning, our approach predicts health degradation scores and uncovers latent heterogeneity from elderly health histories, offering both efficient estimation and explainable insights into the diverse effects and causes of aging-related degradation. A real-case study demonstrates the effectiveness and marks a pivotal contribution to accurately modeling the intricate dynamics of elderly degradation, and addresses the healthcare challenges in the aging population.
ReConTab: Regularized Contrastive Representation Learning for Tabular Data
Oct 28, 2023
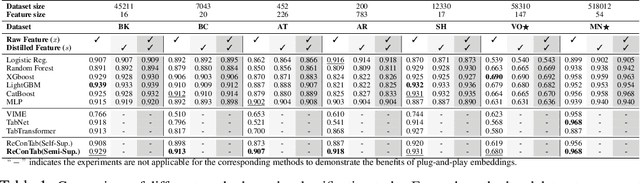

Representation learning stands as one of the critical machine learning techniques across various domains. Through the acquisition of high-quality features, pre-trained embeddings significantly reduce input space redundancy, benefiting downstream pattern recognition tasks such as classification, regression, or detection. Nonetheless, in the domain of tabular data, feature engineering and selection still heavily rely on manual intervention, leading to time-consuming processes and necessitating domain expertise. In response to this challenge, we introduce ReConTab, a deep automatic representation learning framework with regularized contrastive learning. Agnostic to any type of modeling task, ReConTab constructs an asymmetric autoencoder based on the same raw features from model inputs, producing low-dimensional representative embeddings. Specifically, regularization techniques are applied for raw feature selection. Meanwhile, ReConTab leverages contrastive learning to distill the most pertinent information for downstream tasks. Experiments conducted on extensive real-world datasets substantiate the framework's capacity to yield substantial and robust performance improvements. Furthermore, we empirically demonstrate that pre-trained embeddings can seamlessly integrate as easily adaptable features, enhancing the performance of various traditional methods such as XGBoost and Random Forest.