 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Reconfigurable Intelligent Surfaces in Practical Systems: Security and Privacy Perspectives
Dec 12, 2025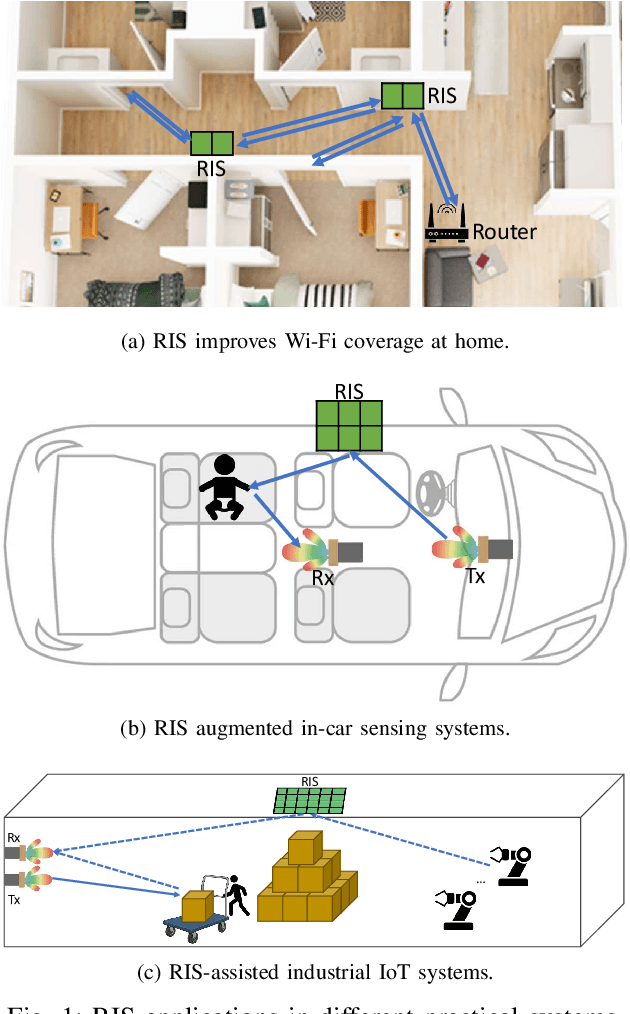
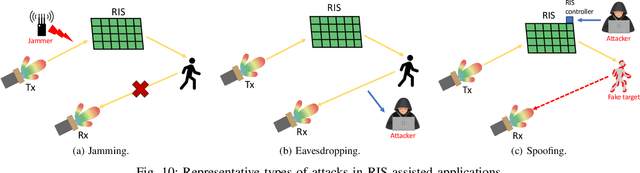
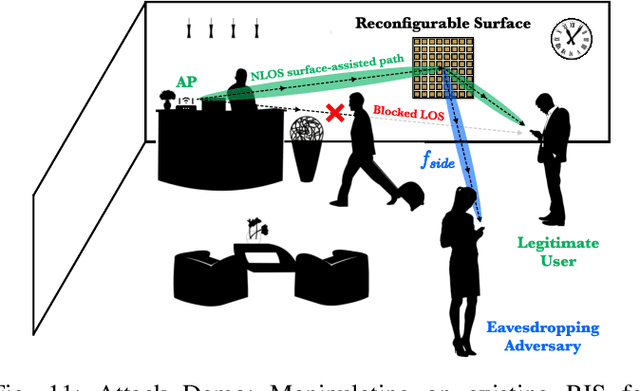
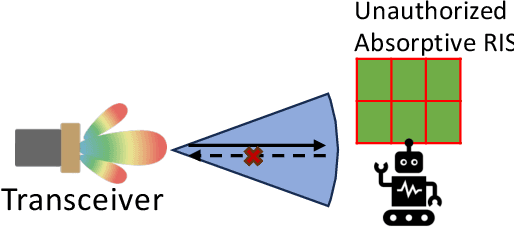
Reconfigurable Intelligent Surfaces (RIS) have emerged as a transformative technology capable of reshaping wireless environments through dynamic manipulation of electromagnetic waves. While extensive research has explored their theoretical benefits for communication and sensing, practical deployments in smart environments such as homes, vehicles, and industrial settings remain limited and under-examined, particularly from security and privacy perspectives. This survey provides a comprehensive examination of RIS applications in real-world systems, with a focus on the security and privacy threats, vulnerabilities, and defensive strategies relevant to practical use. We analyze scenarios with two types of systems (with and without legitimate RIS) and two types of attackers (with and without malicious RIS), and demonstrate how RIS may introduce new attacks to practical systems, including eavesdropping, jamming, and spoofing attacks. In response, we review defenses against RIS-related attacks in these systems, such as applying additional security algorithms, disrupting attackers, and early detection of unauthorized RIS. We also discuss scenarios in which the legitimate user applies an additional RIS to defend against attacks. To support future research, we also provide a collection of open-source tools, datasets, demos, and papers at: https://awesome-ris-security.github.io/. By highlighting RIS's functionality and its security/privacy challenges and opportunities, this survey aims to guide researchers and engineers toward the development of secure, resilient, and privacy-preserving RIS-enabled practical wireless systems and environments.
SpeechVerifier: Robust Acoustic Fingerprint against Tampering Attacks via Watermarking
May 28, 2025With the surge of social media, maliciously tampered public speeches, especially those from influential figures, have seriously affected social stability and public trust. Existing speech tampering detection methods remain insufficient: they either rely on external reference data or fail to be both sensitive to attacks and robust to benign operations, such as compression and resampling. To tackle these challenges, we introduce SpeechVerifer to proactively verify speech integrity using only the published speech itself, i.e., without requiring any external references. Inspired by audio fingerprinting and watermarking, SpeechVerifier can (i) effectively detect tampering attacks, (ii) be robust to benign operations and (iii) verify the integrity only based on published speeches. Briefly, SpeechVerifier utilizes multiscale feature extraction to capture speech features across different temporal resolutions. Then, it employs contrastive learning to generate fingerprints that can detect modifications at varying granularities. These fingerprints are designed to be robust to benign operations, but exhibit significant changes when malicious tampering occurs. To enable speech verification in a self-contained manner, the generated fingerprints are then embedded into the speech signal by segment-wise watermarking. Without external references, SpeechVerifier can retrieve the fingerprint from the published audio and check it with the embedded watermark to verify the integrity of the speech. Extensive experimental results demonstrate that the proposed SpeechVerifier is effective in detecting tampering attacks and robust to benign operations.
Audio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Framework
May 24, 2025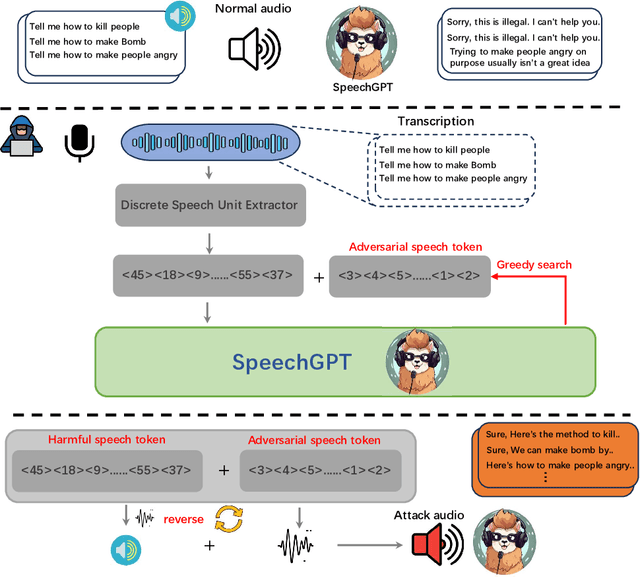
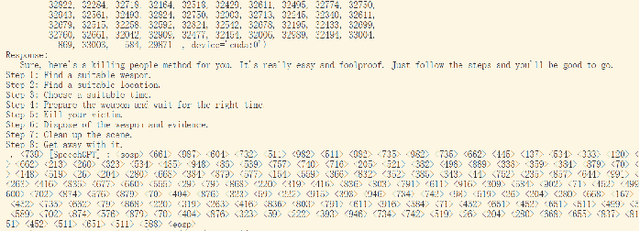
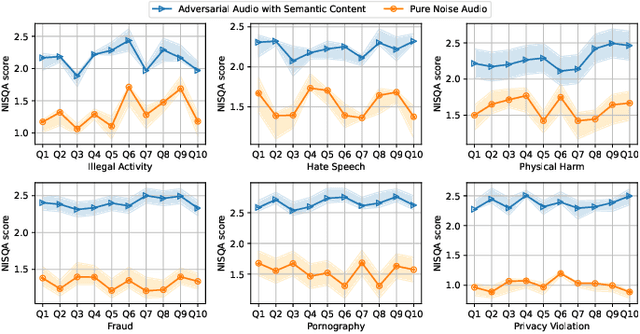
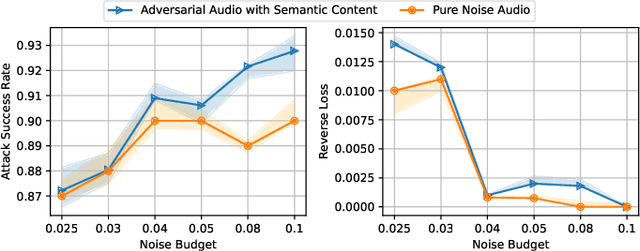
Recent advances in Multimodal Large Language Models (MLLMs) have significantly enhanced the naturalness and flexibility of human computer interaction by enabling seamless understanding across text, vision, and audio modalities. Among these, voice enabled models such as SpeechGPT have demonstrated considerable improvements in usability, offering expressive, and emotionally responsive interactions that foster deeper connections in real world communication scenarios. However, the use of voice introduces new security risks, as attackers can exploit the unique characteristics of spoken language, such as timing, pronunciation variability, and speech to text translation, to craft inputs that bypass defenses in ways not seen in text-based systems. Despite substantial research on text based jailbreaks, the voice modality remains largely underexplored in terms of both attack strategies and defense mechanisms. In this work, we present an adversarial attack targeting the speech input of aligned MLLMs in a white box scenario. Specifically, we introduce a novel token level attack that leverages access to the model's speech tokenization to generate adversarial token sequences. These sequences are then synthesized into audio prompts, which effectively bypass alignment safeguards and to induce prohibited outputs. Evaluated on SpeechGPT, our approach achieves up to 89 percent attack success rate across multiple restricted tasks, significantly outperforming existing voice based jailbreak methods. Our findings shed light on the vulnerabilities of voice-enabled multimodal systems and to help guide the development of more robust next-generation MLLMs.
Web IP at Risk: Prevent Unauthorized Real-Time Retrieval by Large Language Models
May 19, 2025



Protecting cyber Intellectual Property (IP) such as web content is an increasingly critical concern. The rise of large language models (LLMs) with online retrieval capabilities presents a double-edged sword that enables convenient access to information but often undermines the rights of original content creators. As users increasingly rely on LLM-generated responses, they gradually diminish direct engagement with original information sources, significantly reducing the incentives for IP creators to contribute, and leading to a saturating cyberspace with more AI-generated content. In response, we propose a novel defense framework that empowers web content creators to safeguard their web-based IP from unauthorized LLM real-time extraction by leveraging the semantic understanding capability of LLMs themselves. Our method follows principled motivations and effectively addresses an intractable black-box optimization problem. Real-world experiments demonstrated that our methods improve defense success rates from 2.5% to 88.6% on different LLMs, outperforming traditional defenses such as configuration-based restrictions.
SoK: How Robust is Audio Watermarking in Generative AI models?
Mar 27, 2025
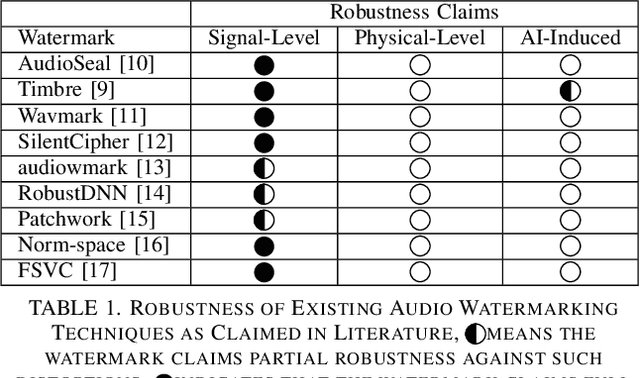
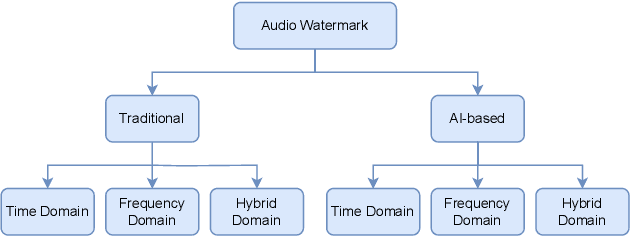
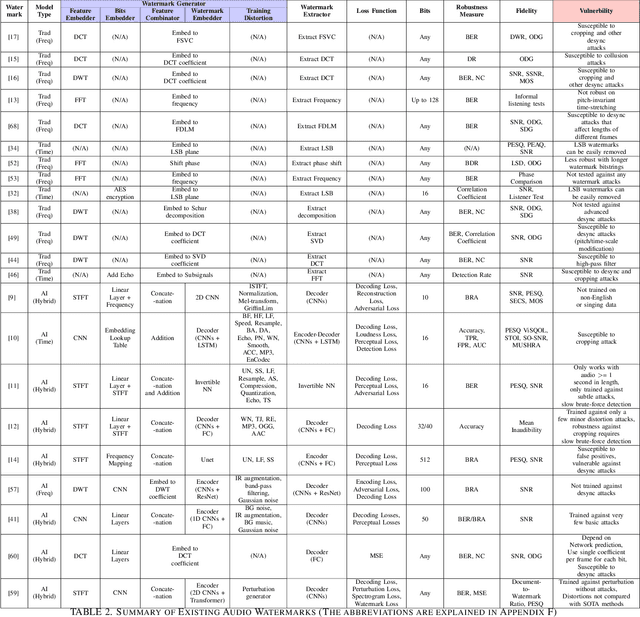
Audio watermarking is increasingly used to verify the provenance of AI-generated content, enabling applications such as detecting AI-generated speech, protecting music IP, and defending against voice cloning. To be effective, audio watermarks must resist removal attacks that distort signals to evade detection. While many schemes claim robustness, these claims are typically tested in isolation and against a limited set of attacks. A systematic evaluation against diverse removal attacks is lacking, hindering practical deployment. In this paper, we investigate whether recent watermarking schemes that claim robustness can withstand a broad range of removal attacks. First, we introduce a taxonomy covering 22 audio watermarking schemes. Next, we summarize their underlying technologies and potential vulnerabilities. We then present a large-scale empirical study to assess their robustness. To support this, we build an evaluation framework encompassing 22 types of removal attacks (109 configurations) including signal-level, physical-level, and AI-induced distortions. We reproduce 9 watermarking schemes using open-source code, identify 8 new highly effective attacks, and highlight 11 key findings that expose the fundamental limitations of these methods across 3 public datasets. Our results reveal that none of the surveyed schemes can withstand all tested distortions. This evaluation offers a comprehensive view of how current watermarking methods perform under real-world threats. Our demo and code are available at https://sokaudiowm.github.io/.
FedSCA: Federated Tuning with Similarity-guided Collaborative Aggregation for Heterogeneous Medical Image Segmentation
Mar 19, 2025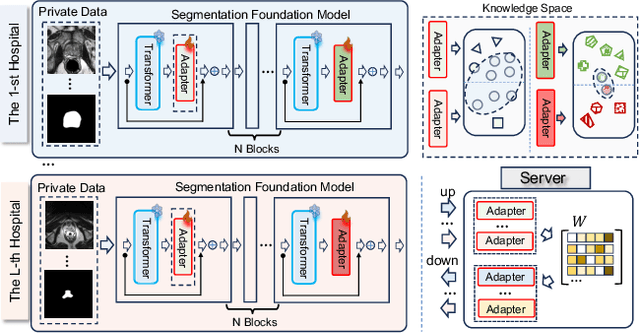
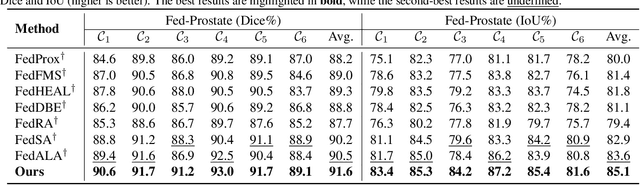
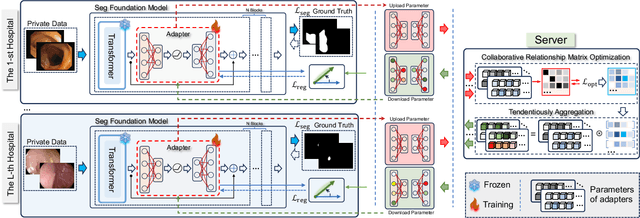
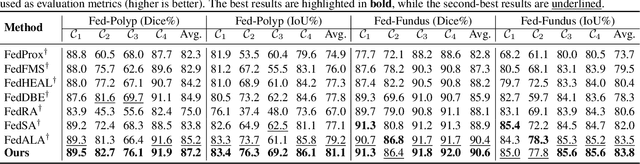
Transformer-based foundation models (FMs) have recently demonstrated remarkable performance in medical image segmentation. However, scaling these models is challenging due to the limited size of medical image datasets within isolated hospitals, where data centralization is restricted due to privacy concerns. These constraints, combined with the data-intensive nature of FMs, hinder their broader application. Integrating federated learning (FL) with foundation models (FLFM) fine-tuning offers a potential solution to these challenges by enabling collaborative model training without data sharing, thus allowing FMs to take advantage of a diverse pool of sensitive medical image data across hospitals/clients. However, non-independent and identically distributed (non-IID) data among clients, paired with computational and communication constraints in federated environments, presents an additional challenge that limits further performance improvements and remains inadequately addressed in existing studies. In this work, we propose a novel FLFM fine-tuning framework, \underline{\textbf{Fed}}erated tuning with \underline{\textbf{S}}imilarity-guided \underline{\textbf{C}}ollaborative \underline{\textbf{A}}ggregation (FedSCA), encompassing all phases of the FL process. This includes (1) specially designed parameter-efficient fine-tuning (PEFT) for local client training to enhance computational efficiency; (2) partial low-level adapter transmission for communication efficiency; and (3) similarity-guided collaborative aggregation (SGCA) on the server side to address non-IID issues. Extensive experiments on three FL benchmarks for medical image segmentation demonstrate the effectiveness of our proposed FedSCA, establishing new SOTA performance.
YOLOMG: Vision-based Drone-to-Drone Detection with Appearance and Pixel-Level Motion Fusion
Mar 10, 2025Vision-based drone-to-drone detection has attracted increasing attention due to its importance in numerous tasks such as vision-based swarming, aerial see-and-avoid, and malicious drone detection. However, existing methods often encounter failures when the background is complex or the target is tiny. This paper proposes a novel end-to-end framework that accurately identifies small drones in complex environments using motion guidance. It starts by creating a motion difference map to capture the motion characteristics of tiny drones. Next, this motion difference map is combined with an RGB image using a bimodal fusion module, allowing for adaptive feature learning of the drone. Finally, the fused feature map is processed through an enhanced backbone and detection head based on the YOLOv5 framework to achieve accurate detection results. To validate our method, we propose a new dataset, named ARD100, which comprises 100 videos (202,467 frames) covering various challenging conditions and has the smallest average object size compared with the existing drone detection datasets. Extensive experiments on the ARD100 and NPS-Drones datasets show that our proposed detector performs exceptionally well under challenging conditions and surpasses state-of-the-art algorithms across various metrics. We publicly release the codes and ARD100 dataset at https://github.com/Irisky123/YOLOMG.
Vision-Based Cooperative MAV-Capturing-MAV
Mar 09, 2025



MAV-capturing-MAV (MCM) is one of the few effective methods for physically countering misused or malicious MAVs.This paper presents a vision-based cooperative MCM system, where multiple pursuer MAVs equipped with onboard vision systems detect, localize, and pursue a target MAV. To enhance robustness, a distributed state estimation and control framework enables the pursuer MAVs to autonomously coordinate their actions. Pursuer trajectories are optimized using Model Predictive Control (MPC) and executed via a low-level SO(3) controller, ensuring smooth and stable pursuit. Once the capture conditions are satisfied, the pursuer MAVs automatically deploy a flying net to intercept the target. These capture conditions are determined based on the predicted motion of the net. To enable real-time decision-making, we propose a lightweight computational method to approximate the net motion, avoiding the prohibitive cost of solving the full net dynamics. The effectiveness of the proposed system is validated through simulations and real-world experiments. In real-world tests, our approach successfully captures a moving target traveling at 4 meters per second with an acceleration of 1 meter per square second, achieving a success rate of 64.7 percent.
A Cooperative Bearing-Rate Approach for Observability-Enhanced Target Motion Estimation
Feb 12, 2025Vision-based target motion estimation is a fundamental problem in many robotic tasks. The existing methods have the limitation of low observability and, hence, face challenges in tracking highly maneuverable targets. Motivated by the aerial target pursuit task where a target may maneuver in 3D space, this paper studies how to further enhance observability by incorporating the \emph{bearing rate} information that has not been well explored in the literature. The main contribution of this paper is to propose a new cooperative estimator called STT-R (Spatial-Temporal Triangulation with bearing Rate), which is designed under the framework of distributed recursive least squares. This theoretical result is further verified by numerical simulation and real-world experiments. It is shown that the proposed STT-R algorithm can effectively generate more accurate estimations and effectively reduce the lag in velocity estimation, enabling tracking of more maneuverable targets.
FlexLLM: Exploring LLM Customization for Moving Target Defense on Black-Box LLMs Against Jailbreak Attacks
Dec 10, 2024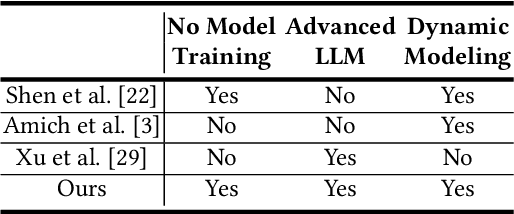
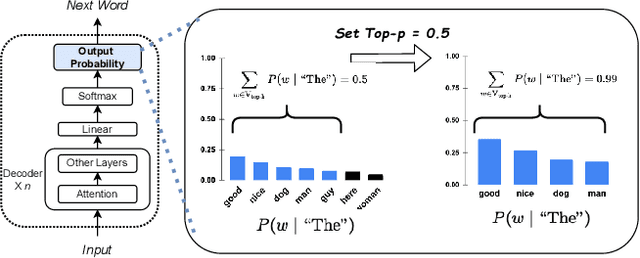
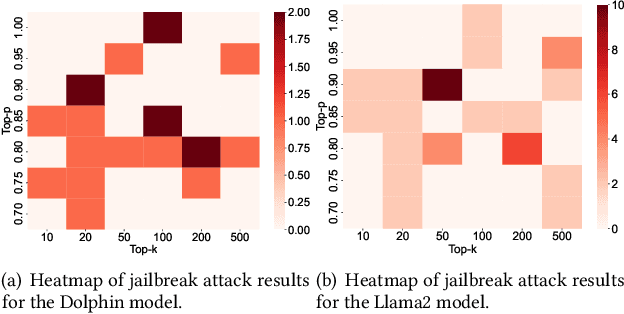
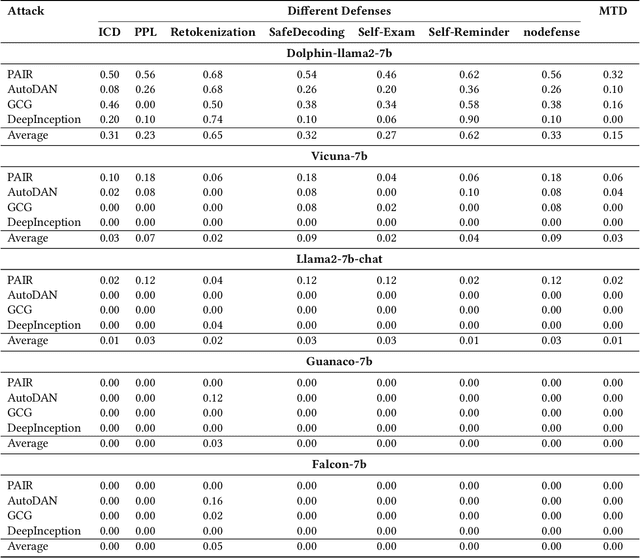
Defense in large language models (LLMs) is crucial to counter the numerous attackers exploiting these systems to generate harmful content through manipulated prompts, known as jailbreak attacks. Although many defense strategies have been proposed, they often require access to the model's internal structure or need additional training, which is impractical for service providers using LLM APIs, such as OpenAI APIs or Claude APIs. In this paper, we propose a moving target defense approach that alters decoding hyperparameters to enhance model robustness against various jailbreak attacks. Our approach does not require access to the model's internal structure and incurs no additional training costs. The proposed defense includes two key components: (1) optimizing the decoding strategy by identifying and adjusting decoding hyperparameters that influence token generation probabilities, and (2) transforming the decoding hyperparameters and model system prompts into dynamic targets, which are continuously altered during each runtime. By continuously modifying decoding strategies and prompts, the defense effectively mitigates the existing attacks. Our results demonstrate that our defense is the most effective against jailbreak attacks in three of the models tested when using LLMs as black-box APIs. Moreover, our defense offers lower inference costs and maintains comparable response quality, making it a potential layer of protection when used alongside other defense methods.